Sinds november 2021 is ChatGPT en de onderliggende technologie van de Large Language Models (LLM’s) een alomtegenwoordig onderwerp. Vanuit puur technisch oogpunt is de werking van LLM’s gebaseerd op ‘next-word-prediction’. Dit betekent dat de voorspelling van een woord plaatsvindt op basis van voorgaande woorden. Door de enorme omvang van de trainingsdata en modelparameters – GPT 3.5 bestaat bijvoorbeeld uit 175 miljard parameters – kunnen de LLM's verschillende situaties 'begrijpen' en complexere taalkundige en semantische patronen herkennen/reproduceren.
Beperkingen
Maar achter alle hype rond LLM’s schuilen ook terechte kritiek en prestatieproblemen:
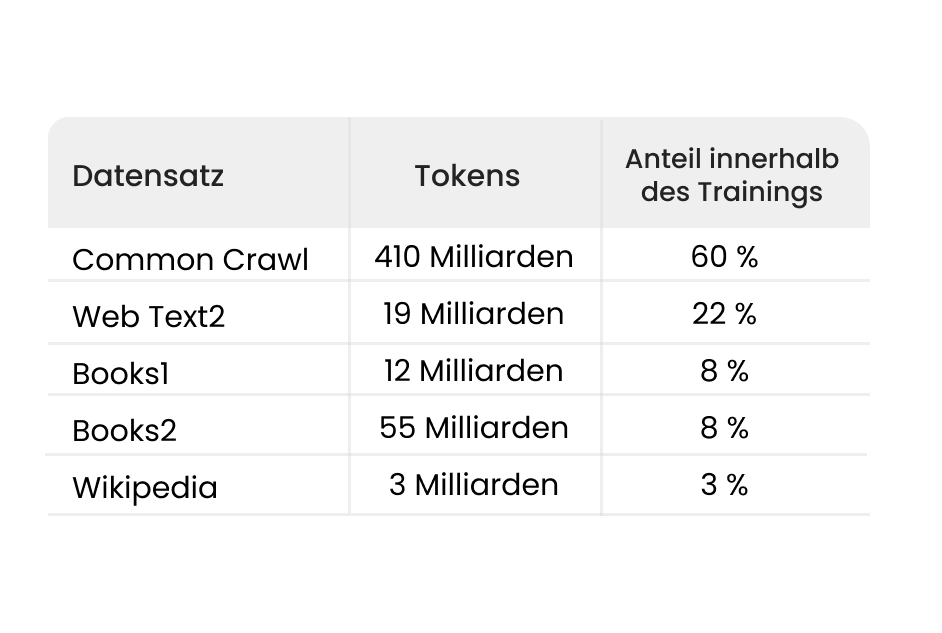
LLM’s worden getraind op basis van een enorme hoeveelheid gegevens. Hiervoor wordt bijvoorbeeld gebruikgemaakt van teksten uit Wikipedia, nieuwsberichten of de zogenaamde CommonCrawl. De inhoud van deze datasets is in de meeste gevallen erg algemeen en weinig specifiek. Nicheonderwerpen en informatie die bijvoorbeeld afkomstig is uit minder bekende of door licenties beschermde boeken, zijn hier niet te vinden.
Zeker wanneer je een chatbot zoals ChatGPT vragen stelt over onderwerpen waar je zelf verstand van hebt – ook wel ‘prompts’ genoemd – merk je al snel dat deze systemen hun grenzen bereiken. Omdat de onderliggende AI-modellen niet voldoende zijn getraind met informatie over bepaalde onderwerpen, verzinnen deze modellen antwoorden die op het eerste gezicht heel aannemelijk lijken. Op het gebied van AI noemt men dit fenomeen een 'hallucinatie'. Met andere woorden zou men ook kunnen zeggen dat het model overtuigend Feiten verzint en zo desinformatie verspreidt.
Een ander probleem is dat LLM’s alleen worden getraind met gegevens die tot een bepaalde peildatum reiken. Bij GPT-3.5 is dat bijvoorbeeld juni 2021. Alle informatie en teksten die na die datum zijn gepubliceerd, zijn dus niet beschikbaar voor het AI-model. Het regelmatig bijscholen van de modellen met nieuwe gegevens kan helpen om deze gegevenskloof te dichten, maar dit is zeer kostbaar en tijdrovend.
De beperkingen en problemen van LLM's beperken de bruikbaarheid voor veel gebruikers aanzienlijk, met name in zeer gespecialiseerde domeinen.
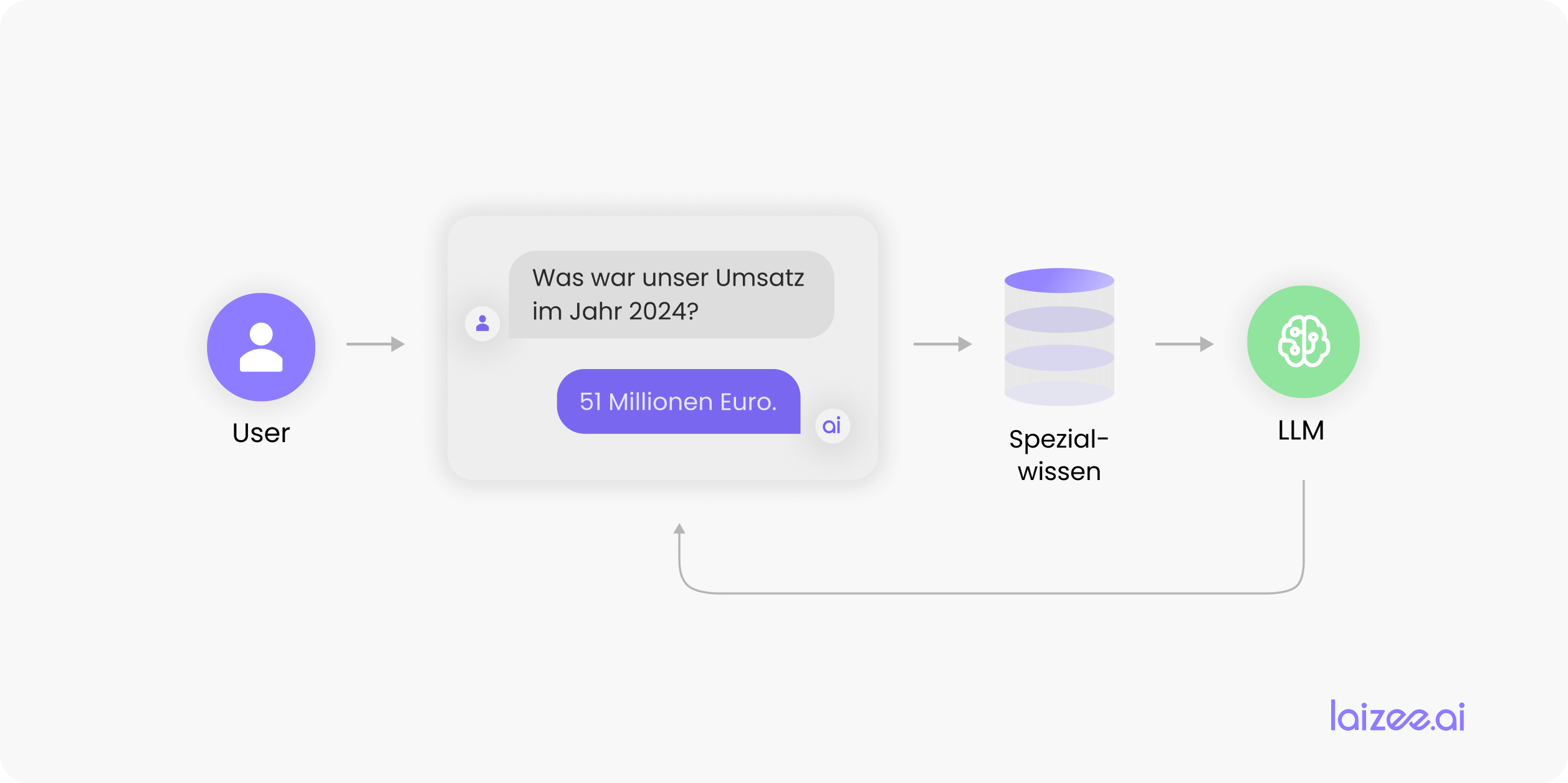
Hoe kan een bedrijf toch de voordelen van LLM’s benutten en de kennis daarvan uitbreiden met bedrijfsinterne informatie? Een manier om ontbrekende kennis snel en kostenefficiënt in het eigen systeem of model te integreren, is RAG.
Wat is RAG en hoe werkt het?
RAG staat voor Generatie ondersteund door opvraging. In het Nederlands zou je dit kunnen vertalen als „generatie uitgebreid met query’s“. RAG is een proces voor het optimaliseren en specialiseren van LLM-uitvoer. In wezen gaat het erom dat we de impliciet aangeleerde kennis van een LLM uitbreiden met toepassingsspecifieke informatie. Het LLM is vervolgens in staat om toepassingsspecifieke vragen van een gebruiker correct te beantwoorden op basis van deze kennisuitbreiding.
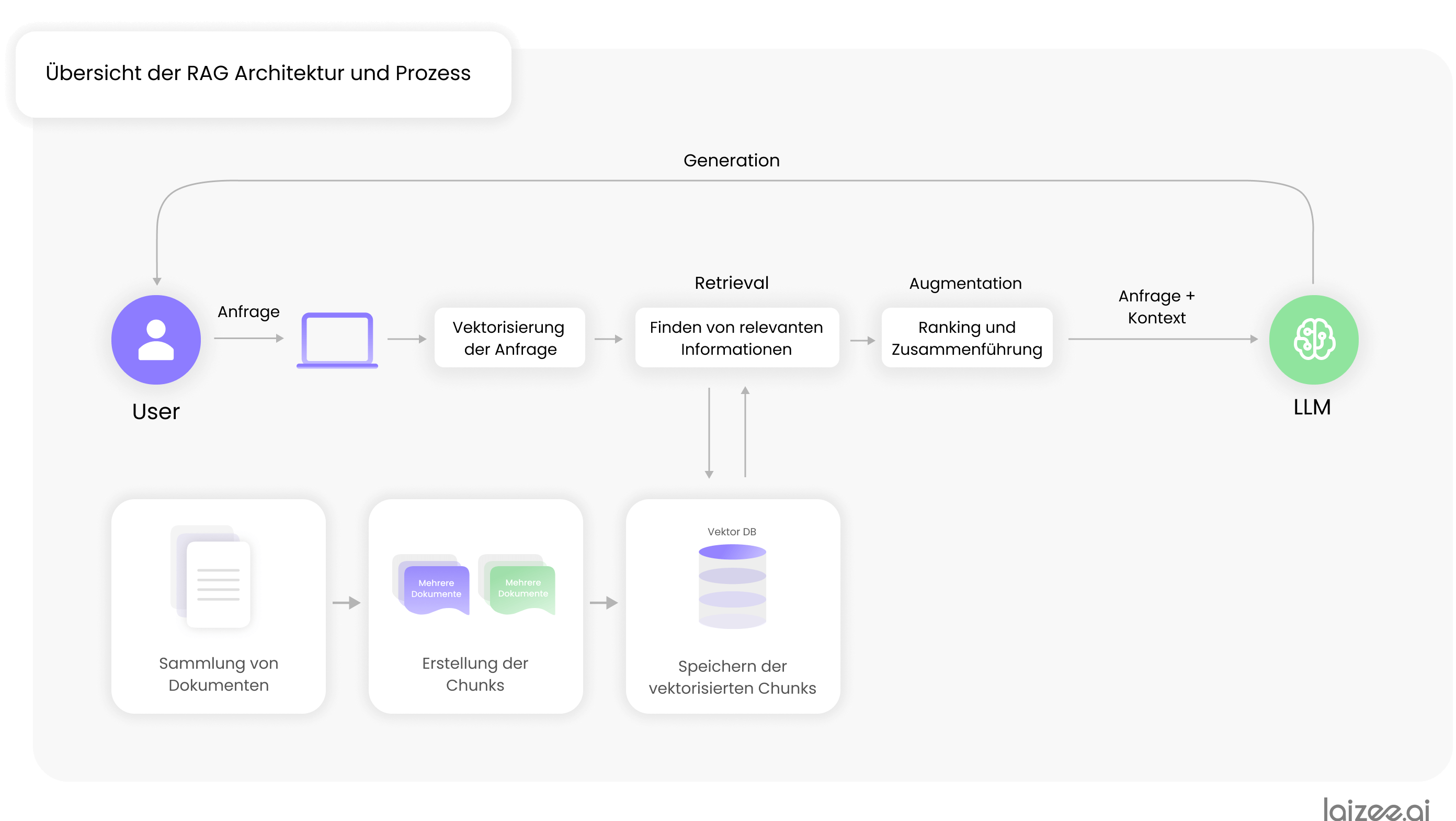
In zijn eenvoudigste vorm bestaat het RAG-proces uit drie onderdelen:
- Een vector-database waarin toepassingsspecifieke informatieblokken worden opgeslagen.
- Een opzoeksysteem dat de vector-database doorzoekt op informatie die relevant is voor de zoekopdracht.
- De LLM, die op basis van de gevonden informatie gebruiksvriendelijke antwoorden genereert.
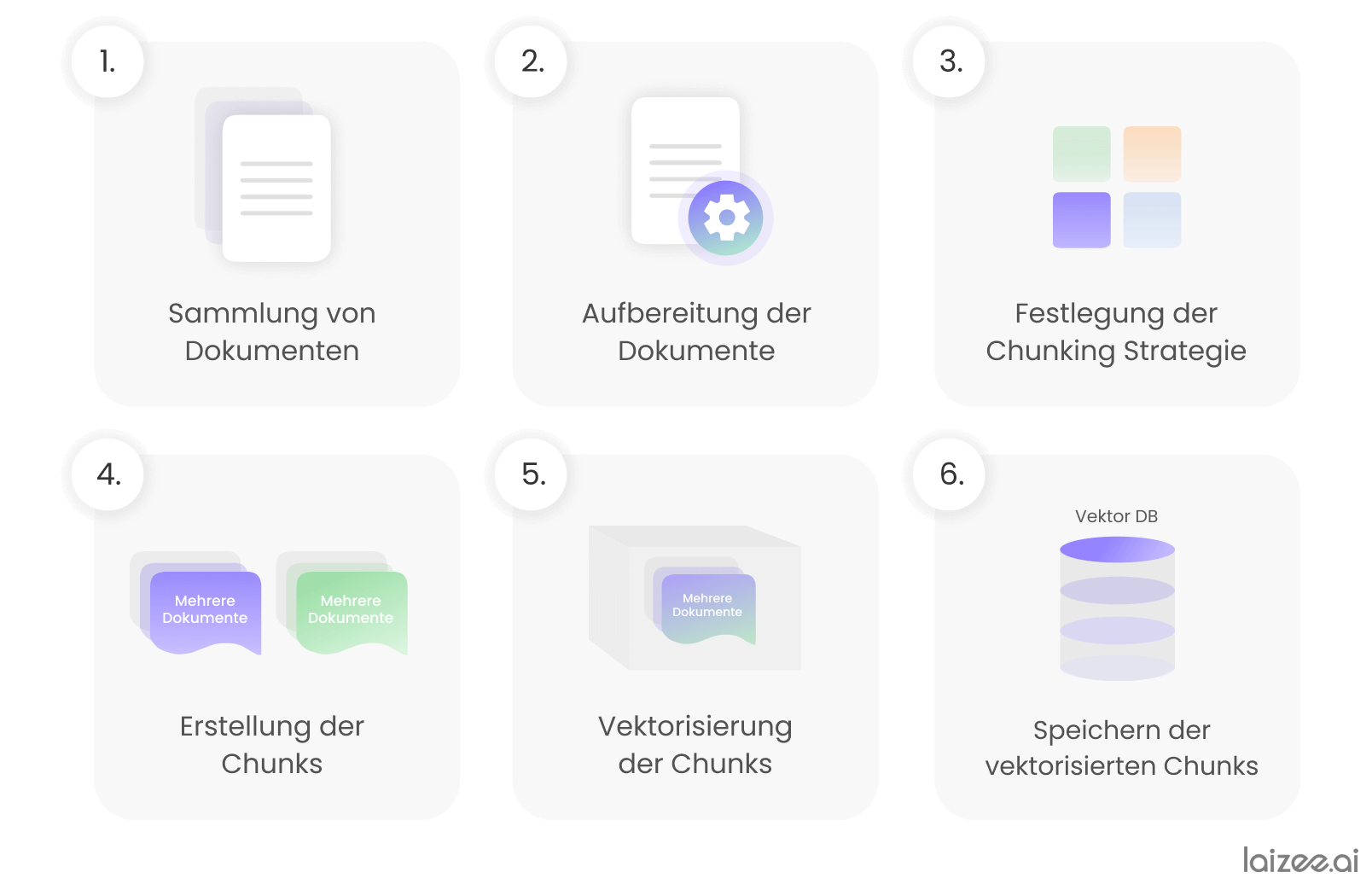
De ruggengraat van een RAG-systeem wordt gevormd door de vector-database, waarin de informatie is opgeslagen die nodig is om toepassingsspecifieke vragen te beantwoorden. Om deze op te bouwen, worden in hoofdzaak de volgende zes stappen doorlopen:
- Verzameling van documenten (bijv. pdf-bestanden) met toepassingsspecifieke informatie en gegevens.
- Verwerking van documenten, bijvoorbeeld het omzetten van pdf-documenten naar machinaal leesbare tekst.
- Het vaststellen van een zogenaamde chunking-strategie, waarmee de documenten in informatieblokken worden opgedeeld.
- Het genereren van de informatieblokken („chunks“) op basis van de eerder vastgestelde strategie.
- Omzetting van de chunks in reeksen getallen (vectoren). Deze stap wordt ook wel ‘embedding’ genoemd.
- De overgebrachte chunks opslaan in de vector-database.
Hoe werkt het opvraagsysteem?
Woorden worden omgezet in numerieke vectoren. Een enkel woord wordt dus weergegeven als een reeks getallen. Het interessante aan vectoren is dat ze kunnen worden gebruikt om semantische overeenkomsten en verbanden tussen woorden te berekenen. Omdat vectoren zeer snel met elkaar kunnen worden vergeleken, is het mogelijk om met een zoekmachine documenten te vinden die qua inhoud op elkaar lijken.
RAG-proces
De gebruiker stuurt een verzoek naar het systeem. Dit verzoek wordt met dezelfde methode als in stap 5 omgezet in een vector.
Op basis van de vector van de zoekopdracht wordt in de vector-database naar relevante informatie gezocht.
Deze gegevens worden vervolgens opgehaald (retrieved) en op basis van verschillende factoren beoordeeld en gerangschikt, waarna de beste resultaten worden samengevoegd. Deze gegevens en documenten vormen de Context waarmee het verzoek van de gebruiker wordt aangevuld.
De zoekopdracht en de eerder vastgestelde context worden vervolgens doorgegeven aan het LLM. Dit genereert aan de hand van de aanvullende informatie een passend antwoord en geeft dit vervolgens weer aan de gebruiker.
Overzicht van de RAG-architectuur en het proces
RAG versus fijnafstemming
Een andere manier om een LLM uit te breiden met toepassingsspecifieke informatie is die van de zogenaamde Fijnafstemming. Hiervoor neemt men een reeds voorgetraind LLM en traint men dit verder op basis van toepassingsspecifieke informatie. Tijdens dit verdere trainen worden de bestaande modelparameters geoptimaliseerd. Door het finetunen van de modelparameters is het verder getrainde model, in tegenstelling tot het oorspronkelijke model, in staat om ook toepassingsspecifieke taken uit te voeren. Het finetunen van bestaande LLM's is doorgaans aanzienlijk kostbaarder en tijdrovender dan de RAG-aanpak.
Voordelen van de finetuning-aanpak
- Het geoptimaliseerde model kan worden gebruikt voor alle LLM-taken (bijvoorbeeld sentimentanalyse, entiteitsherkenning) en niet alleen voor vraag-en-antwoord-systemen, oftewel Q&A-taken
- Eenmalige kosten (tenzij er regelmatig nieuwe informatie moet worden ingevoerd)
- Geen blijvende extra kosten voor infrastructuur
Uitdagingen bij de aanpak van finetuning
- In principe niet mogelijk bij aanbieders van closed-source modellen van derden, zoals OpenAI
- Het trainingsproces is doorgaans kostbaar en tijdrovend
- niet functioneel wanneer rekening moet worden gehouden met realtime of dynamische gegevens
- Hallucinaties blijven een probleem
- De bron van de antwoorden is niet traceerbaar/niet achter te halen
Voordelen van het RAG-proces
- Een snelle manier om LLM’s uit te breiden met interne en domeinspecifieke kennis
- Voordelige, flexibele opstelling
- Ondersteunt de dynamische integratie van realtimegegevens
- Maakt het mogelijk bronnen te vermelden en de herkomst ervan te traceren
- Er zijn geen gelabelde gegevens nodig
- Toegangsbeheer van bronnen
Uitdagingen van het RAG-proces
- Het 'Search and Retrieval'-proces heeft een grote invloed op de kwaliteit van de output
- RAG is vooral relevant voor vraag-en-antwoord-systemen
- Het opzetten en continu beheer van de vector-database brengt doorlopende kosten met zich mee
- Het aantal invoertokens dat aan het LLM wordt doorgegeven, neemt toe door de context
Toepassingsvoorbeelden
RAG presteert vooral uitstekend bij Q&A-taken en informatie-extractie, dat wil zeggen bij taken waarbij we van het AI-systeem een duidelijk antwoord op een vraag verwachten. Het antwoord kan bovendien worden onderbouwd met de bronnen die het LLM heeft gebruikt om de vraag te beantwoorden. Dit stelt de gebruiker in staat om het antwoord te verifiëren of aanvullende informatie in te winnen.
Concrete scenario’s in een zakelijke context zijn de uitbreiding van een bedrijfsintranet of een kennisdatabase met een chatbot waarmee medewerkers eenvoudig kunnen communiceren en vragen kunnen stellen. De RAG-chatbot stelt medewerkers in staat om snel toegang te krijgen tot interne bedrijfskennis. Bovendien verwerkt de chatbot de gevonden kennis en presenteert deze in een samenvatting. Dit maakt een efficiënt gebruik van bedrijfskennis mogelijk, verhoogt de werkkwaliteit van de medewerkers en kan op lange termijn bijdragen aan het veiligstellen van een concurrentievoordeel.
Voorbeelden van use cases en producttoepassingen voor een RAG-chatbot zijn:
- Inwerken van nieuwe medewerkers
- Dagelijks gebruik en het verkrijgen van bedrijfsinzichten
- Chatbot als extra toegang tot digitale leerinhoud
… of jullie maken je eigen digitale alter ego à la Tom Riddle met jullie dagboeknotities.