De technologische vooruitgang heeft de manier waarop computers worden gebruikt de afgelopen jaren ingrijpend veranderd. Bijna geen enkele andere sector heeft de manier waarop mensen werken zo sterk veranderd. Digitale communicatie is zowel in de privé- als in de professionele omgeving effectief en vanzelfsprekend. Achtergebleven sectoren hebben te lijden onder hun verouderde communicatievormen en investeren in verbetering.
Op dit moment zijn er veel oplossingen in gebruik die menselijke communicatie in natuurlijke taal tussen mensen mogelijk maken, en oplossingen die formele datacommunicatie tussen IT-systemen realiseren. De eerste categorie valt onder e-mail, sociale media en chat. Veel bedrijven ontvangen via de hierboven beschreven kanalen een groot aantal communicatieverzoeken in natuurlijke taal. Tot nu toe vormt een groot aandeel aan doorlopende tekst een belemmering voor digitalisering en leidt dit tot hoge kosten door overwegend handmatige verwerking.
Natuurlijke taal wordt vooral gekenmerkt door een grote diversiteit, variabiliteit en meerduidigheid. Deze factoren maken geautomatiseerde verwerking met klassieke methoden uit de informatica, zoals grammatica’s, woordenboeken of parsers, vrijwel onmogelijk. Mensen hebben daarentegen een genetische aanleg om informatie uit de context van de taal te halen en zo met deze factoren om te gaan.
Het onderzoeksgebied Natuurlijke taalverwerking (NLP) onderzoekt het raakvlak tussen computers en natuurlijke taal. In principe wordt in dit vakgebied niet geprobeerd om oplossingsalgoritmen te implementeren op basis van louter operationeel geformuleerde regels (programmacode enz.). In plaats daarvan worden regels aangeleerd op basis van bestaande gegevens, waardoor een statistisch model ontstaat (Machine learning, ML). Zodra het statistische model in deze vorm voldoende is getraind, kunnen ook onbekende teksten met een hoge waarschijnlijkheid correct worden verwerkt. De combinatie van handmatig opgestelde en aangeleerde regels leidt tot een effectieve algoritmische aanpak voor de verwerking van natuurlijke taal, die als basis dient voor talrijke toepassingen.

De methoden van machine learning zijn al sinds de jaren vijftig onderwerp van onderzoek. Met de doorbraak van deep learning op het gebied van beeld- en taalverwerking in de jaren 2010 hebben deze methoden steeds meer hun weg gevonden naar het bedrijfsleven.
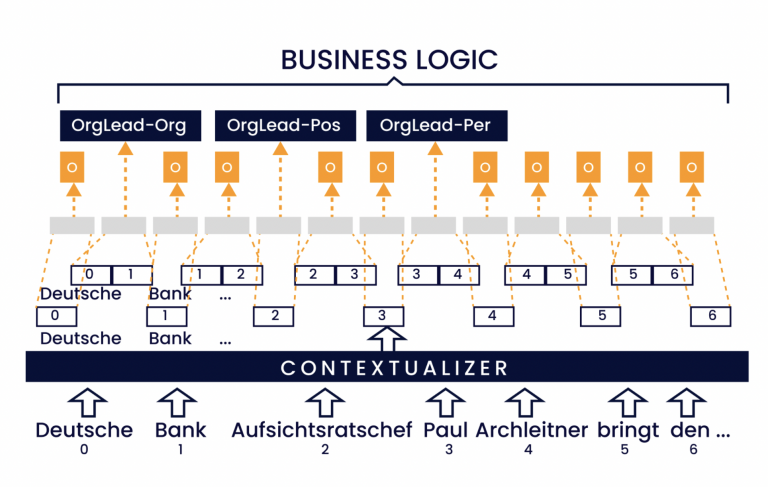
Figuur 1 illustreert het ontwikkelingsproces van NLP-toepassingen. Om een zo representatief en groot mogelijke trainingsdataset te verkrijgen, wordt er handmatig gewerkt (tagging) om een referentieoplossing te creëren. Deze dataset (geannoteerd corpus) vormt de basis voor het trainen van het model, dat wil zeggen de statistische verdeling. Na eventuele optimalisatiestappen is het ontwikkelingsproces voltooid.
Tijdens de daaropvolgende productiefase worden op basis van dit model nu onbekende teksten geanalyseerd. Afhankelijk van de specifieke toepassing vindt er bijvoorbeeld informatie-extractie plaats, dat wil zeggen het identificeren van bekende semantische structuren in de tekst, of een analyse van de gemoedstoestand van de auteur tijdens het schrijven. Van buitenaf gezien werkt het getrainde model als een menselijke medewerker en kan het in bestaande processen worden geïntegreerd. De volgende casestudy illustreert dit proces.
Casestudy
De Deutsche Bahn, een voorbeeld van een grote mobiliteitsaanbieder, wil haar klantcommunicatie effectiever maken. Om de inzet van haar servicemedewerkers zo efficiënt mogelijk te maken, moeten met name veelvoorkomende vragen, zoals
„Mijn verbinding van Aken naar Keulen aanstaande woensdag is geannuleerd. Welke vervangende verbinding kan ik nemen?“
automatisch worden beantwoord. Allereerst valt op dat de relevante parameters van de aanvraag in dit voorbeeld concreet worden genoemd:
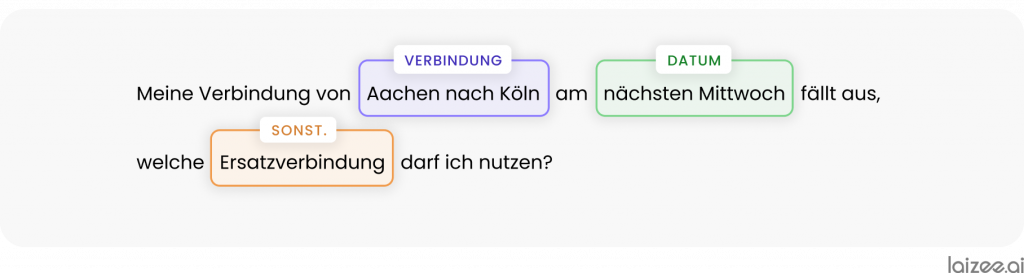
Door deze bekende concepten automatisch te extraheren, wordt de tekstuele aanvraag automatisch omgezet in een gestructureerde aanvraag, waardoor deze in bestaande digitale processen kan worden geïntegreerd.
Tijdens het trainingsproces worden deze concepten toegepast op bestaande klantvragen. Met de resulterende trainingsdataset wordt een statistisch model getraind, zodat het patronen in onbekende lopende tekst kan ontdekken en voorbeelden van de getrainde conceptklassen kan extraheren. De combinatie van het NLP-model met de bijbehorende bedrijfslogica kan nu worden gebruikt om een deel van de vragen automatisch te beantwoorden.
We willen de voordelen van ML in dit verband illustreren aan de hand van het voorbeeld van het datumconcept. Om een datum uit zoekopdrachten te halen, zouden we een reguliere expressie kunnen gebruiken, bijvoorbeeld
^\d{1,2}[ \.]{1,2}\d{0,2}[ \.]{0,2}((19|20|21)?\d{0,2})?$in combinatie met een woordenboek (maandag, …, zondag, morgen, volgende …) gebruiken. Deze klassieke vorm van gegevensverwerking werkt in veel gevallen al goed. De kleinste afwijkingen van het hier gedefinieerde schema leiden er echter toe dat een datum in de tekst niet meer wordt herkend. Bovendien brengt deze aanpak het risico van verschillende ernstige foutensituaties met zich mee. Allereerst blijkt dat fouten, zoals typefouten, spelfouten enz., niet in aanmerking worden genomen. Daarnaast zijn er gevallen waarin woorden uit het woordenboek niet in de context van een datum worden gebruikt.
„… ik heb de trein gemist en wacht nu op de volgende; mijn weekendkaart is maandag namelijk niet meer geldig.“
Dit voorbeeld laat zien dat 'de volgende' ook een verwijzing naar een trein kan zijn. Hier bemoeilijken ontbrekende leestekens, naast het ontbreken van hoofdletters en kleine letters, het opstellen van algemeen geldende regels. Een op dergelijke gegevens getraind ML-gebaseerd NLP-model herkent de verwijzing en kan zo alleen 'maandag' als datum aangeven.
Het ontwikkelings- en DevOps-proces van dit NLP-model wordt, net als bij conventionele softwareontwikkeling, ondersteund door een probleemspecifieke toolstack. Zo bieden NLP-frameworks zoals spaCy alle methoden om NLP-modellen te genereren op basis van bestaande gegevens. Het aanmaken van de trainingsgegevens wordt ondersteund door taakspecifieke annotatietools en ML-specifieke versiebeheertools, zoals DVC. Aangemaakte modellen kunnen efficiënt in de cloud worden geïmplementeerd, beheerd en gemonitord door middel van containertechnologieën zoals Docker, in combinatie met systemen voor het beschikbaar stellen van softwarecontainers zoals Amazon EC² of Kubernetes.
Samenvatting
Het onderzoek op het gebied van NLP heeft de afgelopen jaren grote vooruitgang geboekt. De enorme toename van de beschikbare rekenkracht leidt tot steeds krachtigere modellen en steeds betere NLP-systemen (Google Translate is daar slechts één positief voorbeeld van).
Volgens een onderzoek van Gartner[1]NLP is momenteel bezig de overstap te maken van de onderzoekswereld naar de industrie. De mogelijkheden die ML-gestuurde NLP biedt, hebben in veel bedrijven het potentieel om IT-processen fundamenteel en kostenefficiënt te optimaliseren en tegelijkertijd te voldoen aan de steeds hogere eisen van klanten op het gebied van beschikbaarheid door middel van volledige of gedeeltelijke automatisering.
Auteurs
Prof. dr. Bodo Kraft
Prof. dr. Bodo Kraft is oprichter en hoofd van het laboratorium Business Programming. Daar doet hij al meer dan tien jaar, samen met momenteel vijf promovendi, toepassingsgericht onderzoek op het gebied van computerlinguïstiek. De verschillende projecten hebben als gemeenschappelijk uitgangspunt de uitdaging om grote hoeveelheden documenten in natuurlijke taal efficiënt en geautomatiseerd te verwerken.
Het succesvol afstemmen van de oplossingen op het betreffende domein is hierbij van fundamenteel belang. Een ander aandachtspunt is een flexibele, kwaliteitsgerichte aanpak voor het ontwikkelen van softwaresystemen die in de praktijk bruikbaar en onderhoudbaar zijn.
Lars Klöser, M.Sc.
Lars Klöser heeft informatica gestudeerd aan de RWTH Aachen en promoveert momenteel bij prof. dr. Bodo Kraft; hij maakt deel uit van het Labor Business Programming. Zijn onderzoek richt zich op NLP en in het bijzonder op het extraheren van complexe semantische structuren uit juridische teksten.
[1] https://www.gartner.com/smarterwithgartner/top-trends-on-the-gartner-hype-cycle-for-artificial-intelligence-2019/