1. Inleiding
Kleine en middelgrote ondernemingen (KMO’s) zien steeds vaker het potentieel in van het begrijpen van natuurlijke taal en het extraheren van relaties voor het digitaliseren van processen en het ontwikkelen van innovatieve softwareproducten. Veel productvisies omvatten het extraheren van sets van conceptvermeldingen van variabele omvang als relaties uit teksten, waarbij bestaande datamodellen een reeks potentiële attributen per relatie definiëren. Maar de meeste huidige benaderingen richten zich op de extractie van binaire relaties. Zo heeft het grote aantal van vele duizenden biomedische wetenschappelijke publicaties per week geleid tot de succesvolle automatisering van kennisontdekking (Tsujii et al., 2011; Kim et al., 2011a; Kim et al., 2011b). In tegenstelling tot veel andere domeinen lijkt de structurele beperking van binaire relaties redelijk vanwege oorzaak-gevolgrelaties. Het extraheren van complexere semantische relaties vereist momenteel de bouw van geavanceerde systemen op basis van binaire classificaties. Het gebied van gebeurtenis-extractie omvat dergelijke benaderingen. Gebeurtenissen zijn relaties met meerdere attributen en zogenaamde trigger-annotaties. Bijvoorbeeld in het volgende bericht over een verkeersbelemmering: A1 tussen Köln-Mühlheim en Köln-Dellbrück voorwerpen op de weg, beide rijrichtingen afgesloten. Volgens (Consortium, 2005) leidt ‘afgesloten’ tot de gebeurtenis, maar biedt het geen gebeurtenisspecifieke informatie. Attributen die aan dergelijke triggers worden toegewezen, vormen gebeurtenisrelaties. De centrale rol van triggerannotatie leidt tot hoge kwaliteitseisen en een verhoogde annotatie-inspanning.
Dit onderzoek introduceert multi-attribute relation extraction (MARE), een nieuwe probleemformulering die tot doel heeft de benaderingen voor het extraheren van relaties in de praktijk te vereenvoudigen. Relaties met meerdere attributen:
- beschikken over een bekende reeks mogelijke rollen voor attributen,
- ga niet uit van de multipliciteit van attributen bij het opbouwen van een relatie-instantie, en
- Vertrouw niet op het trigger-concept, dat de aanwezigheid van een relatie aangeeft.
We introduceren een methode voor sequentietagging en span-labeling om entiteiten te herkennen en relaties met meerdere attributen tussen deze entiteiten te extraheren in één gezamenlijk model. We analyseren de prestaties van onze methoden op het Smart-Data-corpus (Schiersch et al., 2018). Dit corpus is de enige beschikbare bron voor relatie-extractie in Duitse teksten. De annotaties van dit corpus omvatten benoemde entiteiten en relaties met meerdere attributen tussen deze entiteiten. We publiceren alle gegevens en broncode die verband houden met het onderzoek in een GitHub-repository¹. Onze belangrijkste bijdragen kunnen als volgt worden samengevat:
- We formuleren de extractie van relaties met meerdere attributen en introduceren twee probleemspecifieke benaderingen.
- We tonen aan dat de niet op triggers gebaseerde benaderingen over het algemeen beter presteren bij de relaties met meerdere attributen in het SmartData-corpus.
- Wij presenteren de eerste reproduceerbare evaluatie van een niet-binaire methode voor het extraheren van relaties op basis van een Duits corpus.
¹https://github.com/MSLars/mare
2. Eerdere studies
Bij relatie-extractie wordt de onderlinge relatie tussen benoemde entiteiten in teksten onderzocht om de ongestructureerde informatie om te zetten in vooraf gedefinieerde schema’s. De meeste benchmarkdatasets houden alleen rekening met binaire relaties (Mintz et al., 2009; Hendrickx et al., 2010).
Traditionele benaderingen voor het extraheren van binaire relaties maken gebruik van woordsoortmarkering, afhankelijkheidsontleding en verdere stappen om invoerrepresentaties voor machine learning-modellen te berekenen (Xu et al., 2013). De huidige state-of-the-art modellen maken gebruik van transformatornetwerken om sterk gecontextualiseerde representaties van kandidaten voor binaire relaties te berekenen en combineren deze met gespecialiseerde beslissingslagen in een gecombineerd neuraal netwerk (Li en Tian, 2020; Eberts en Ulges, 2019).
Als uitbreiding op het herkennen van binaire relaties richt het gebied van het herkennen van n-aire relaties zich op het detecteren van relaties met een vast aantal van n argumenten. (Peng et al., 2017) breidden recurrente neurale netwerken uit om op efficiënte wijze syntactische afhankelijkheidsrelaties mee te nemen bij het opbouwen van contextgebonden relatievoorstellingen. (Lai en Lu, 2021) presenteerden een op transformers gebaseerde benadering voor dezelfde experimentele opzet. Beide richten zich op 3-aire relaties.
Bij methoden voor het extraheren van binaire en kleine n-aire relaties worden vaak reeksen voorspelde entiteiten opgesomd als uitgangspunt voor het genereren van relatiekandidaten. Wij extraheren relaties met een willekeurig aantal attributen en vermijden een dergelijke opsomming om een combinatorische explosie te voorkomen.
Om de beperking van een vaste omvang te verruimen, definieert het vakgebied van gebeurtenis-extractie gebeurtenissen als relaties met meerdere attributen, met één noodzakelijk triggerattribuut. De trigger duidt op de aanwezigheid van een gebeurtenis. Aan afzonderlijke triggers kunnen andere entiteiten worden toegewezen om gebeurtenisrelaties te vormen (Consortium, 2005; Aguilar et al., 2014). Benaderingen voor gebeurtenis-extractie zijn gebaseerd op deze triggerannotaties (Xiang en Wang, 2019). Alle entiteiten die aan één trigger zijn toegewezen, vormen een relatie met meerdere attributen. Dit reduceert het probleem tot een reeks binaire relatieclassificaties.
Traditioneel halen systemen voor relatie-extractie in de praktijk entiteiten en hun relaties uit gegevens via een verwerkingspijplijn. Dergelijke systemen hebben te kampen met foutverspreiding. Op het gebied van gezamenlijke relatie-extractie wordt onderzoek gedaan naar modellen die entiteiten en relaties in één enkel model extraheren. Een veelgebruikte manier om een gezamenlijk model te bouwen, is door de inbeddingslaag te delen tussen meerdere downstream-taken. (Wadden et al., 2019) introduceerden een systeem dat inbeddingen deelt om benoemde entiteiten te extraheren, binaire relatiekandidaten opbouwt en de relatie daartussen classificeert. (Zheng et al., 2017; Liu et al., 2019) introduceren sequentielabelingsschema's om attributen en hun relaties expliciet te extraheren in één enkele classificatiestap. Onze modellen extraheren op vergelijkbare wijze complexere structuren zonder een opsomming van relatiekandidaten. Dit voorkomt een combinatorische explosie voor MARE. We passen een nieuw transformatornetwerk toe om gecontextualiseerde tekst-embeddings te ontvangen (Devlin et al., 2019; Clark et al., 2020).
(Schiersch et al., 2018) introduceerden het Smart-Data Corpus voor relatie-extractie uit Duitse teksten. De geannoteerde relaties bevatten een wisselend aantal verplichte en optionele argumenten. In paragraaf 3 wordt het corpus uitvoerig geanalyseerd. Het oorspronkelijke artikel bevat resultaten van het relatie-extractiesysteem DARE (Xu et al., 2013). Bij deze evaluatie wordt alleen gekeken naar de verplichte attribuutrollen voor elke relatie. We houden ook rekening met optionele attributen en analyseren de resultaten in een meer geavanceerde probleemsetting. (Roller et al., 2018) onderzoekt de extractie van benoemde entiteiten en binaire relaties uit Duitse klinische rapporten. Hun corpus is niet gepubliceerd.
3. Gegevensanalyse
We trainen en evalueren onze methoden op het Smart-Data2-corpus (Schiersch et al., 2018), een Duits corpus dat door het DFKI3 ter beschikking is gesteld. Het corpus bevat handmatig geannoteerde entiteiten en relaties op het gebied van verkeer en industrie in nieuwsberichten, RSS-feeds en tweets.
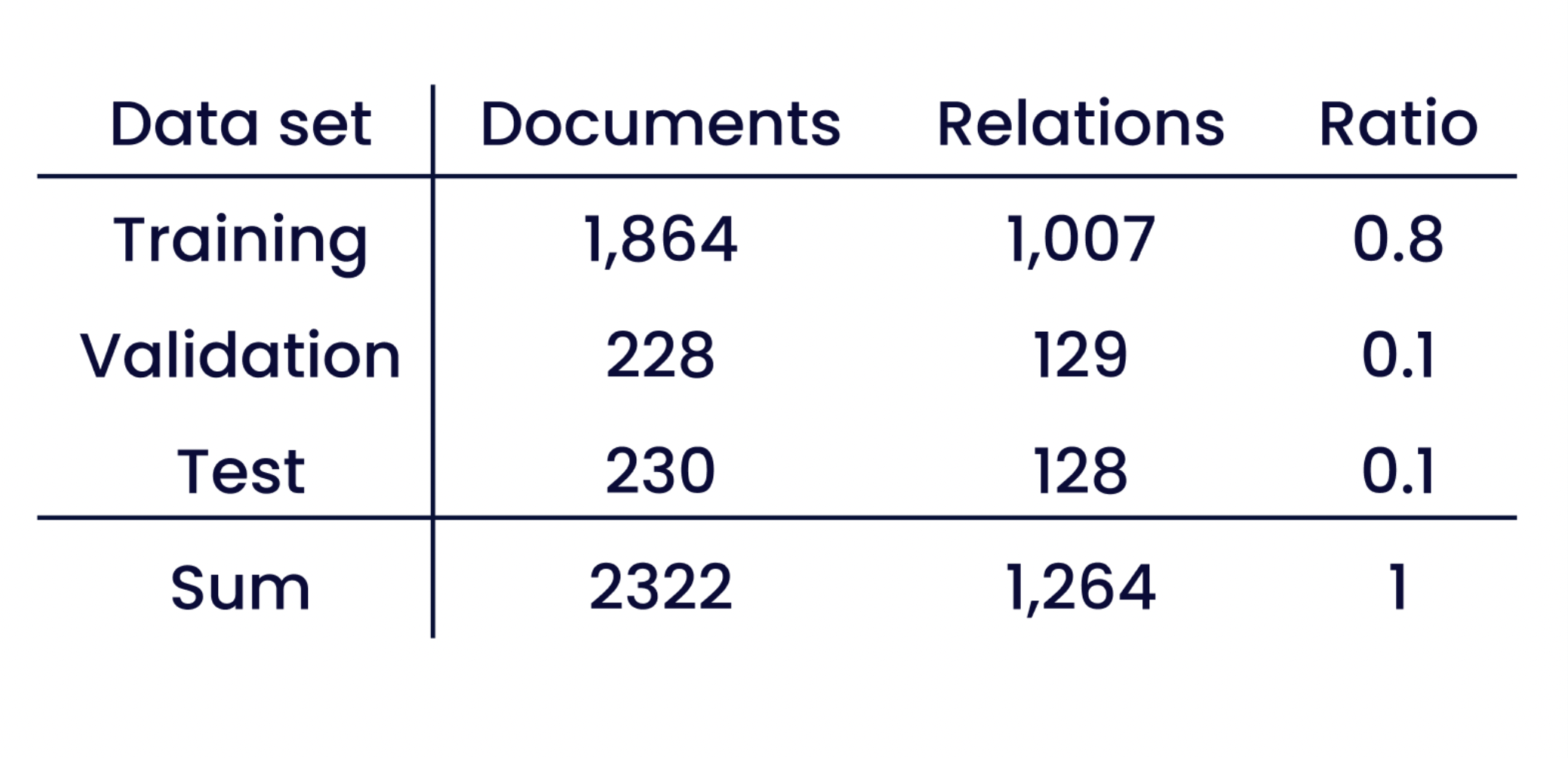
De derde versie van het corpus bevat 19.116 entiteiten en 1.264 relaties in 2.322 documenten, met in totaal 141.344 woorden⁴. Tabel 1 toont de door SmartData verstrekte verdeling tussen trainings- en testgegevens.
De overeenstemming tussen de annotatoren is matig (Viera et al., 2005), met een Cohen’s kappa-coëfficiënt van 0,58 voor entiteiten en 0,51 voor relaties.
Tabel 1: De verdeling van het SmartData-corpus in trainings- en testdatasets, met het aantal relaties en het percentage documenten in elke subset.
DFKI beschrijft hun voorbewerkingsstappen in (Schiersch et al., 2018) en op GitHub.
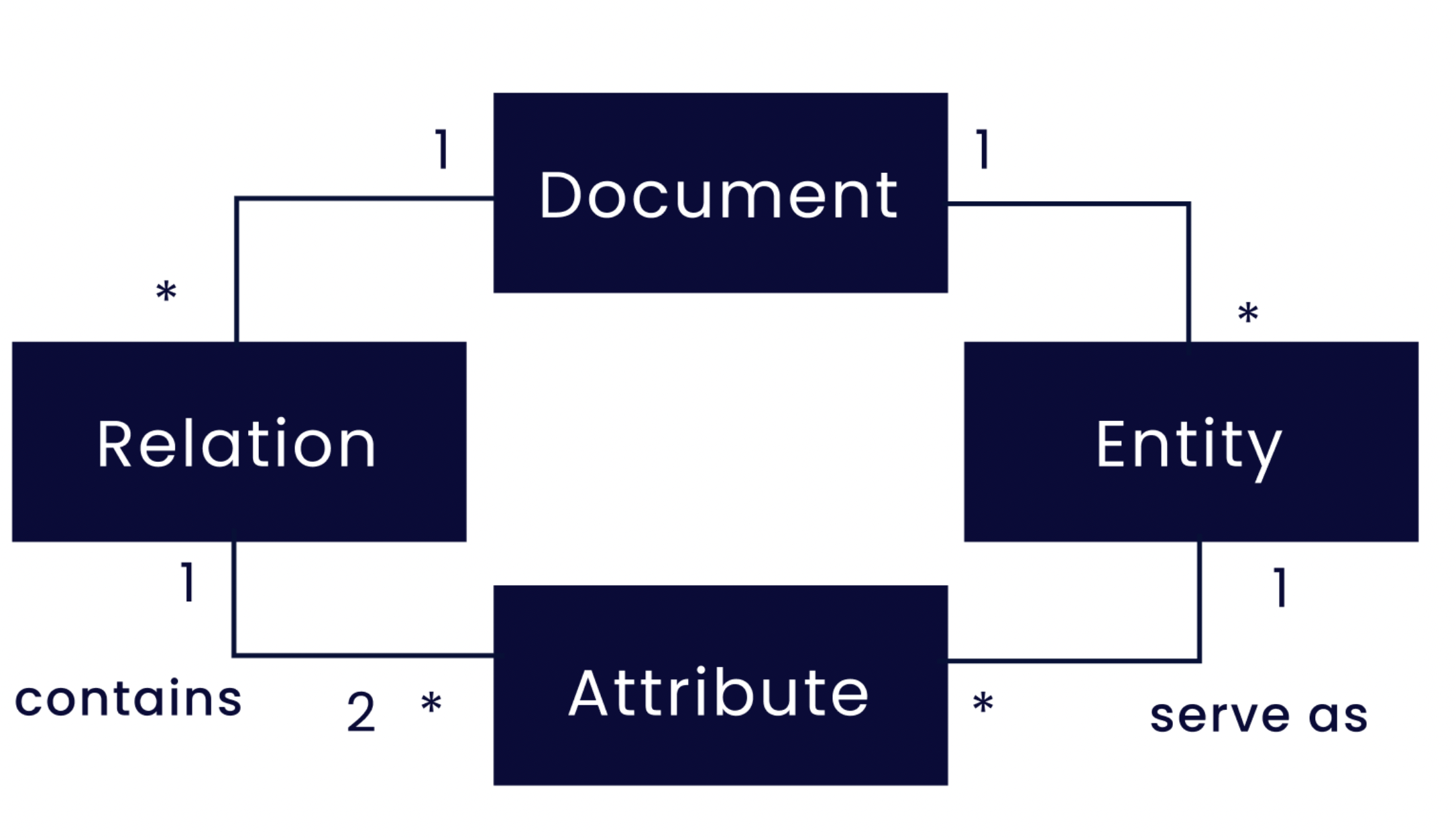
Figuur 1: Structuur van instanties in het SmartData-corpus. Documenten bevatten relaties en entiteiten. Een relatie heeft ten minste twee verplichte attributen. Elk attribuut bevat een entiteitsvermelding. Entiteiten kunnen in nul of meerdere relaties als attribuut fungeren. Zo kan de entiteit ‘Locatie’ bijvoorbeeld tegelijkertijd als attribuut in de relaties ‘Ongeval’ en ‘Belemmering’ voorkomen.
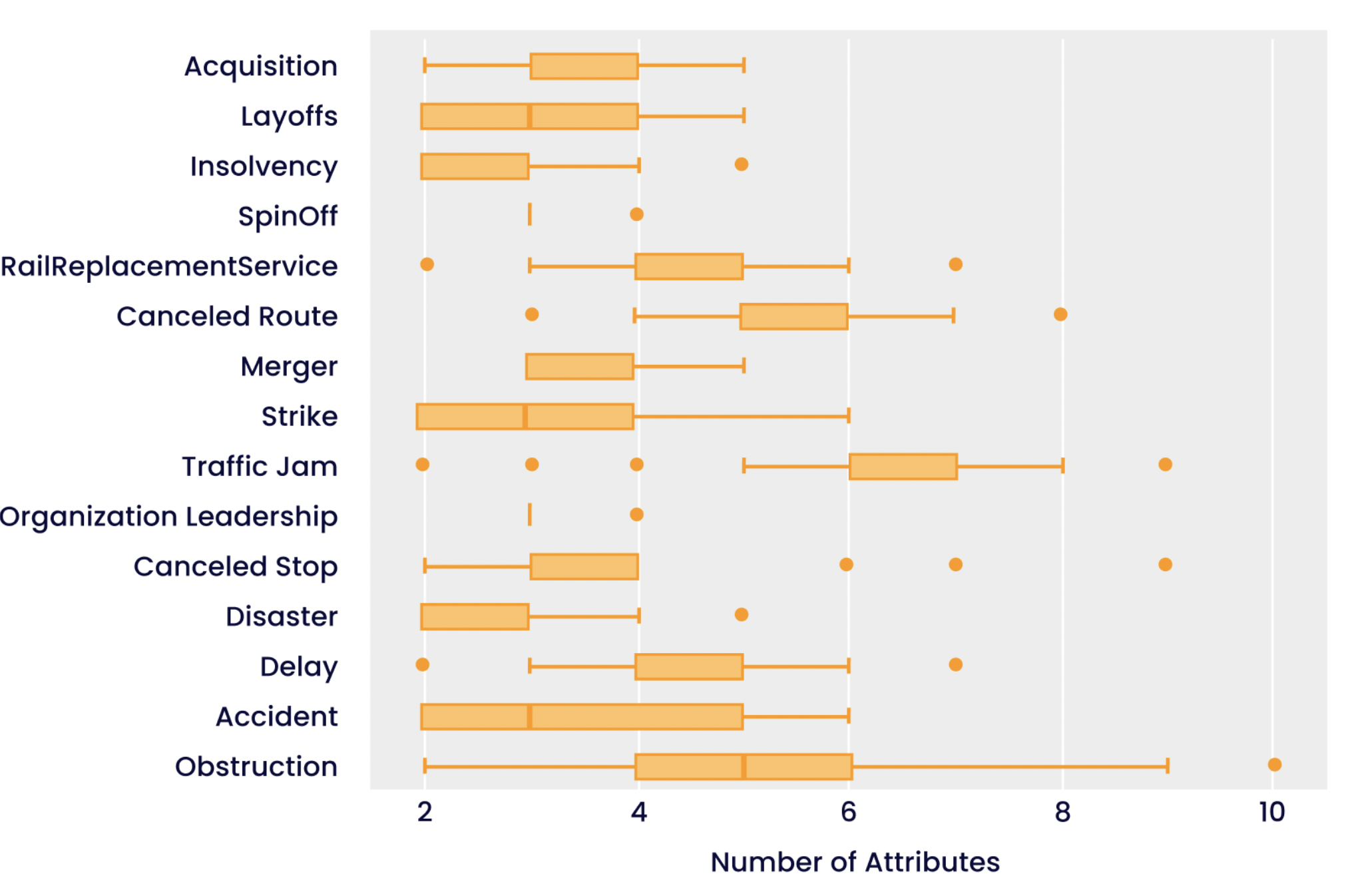
Figuur 2: Boxplot die de verdeling van het aantal attributen per relatie weergeeft. Zo varieert het aantal attributen van de relatie ‘Belemmering’ bijvoorbeeld van twee tot tien, terwijl andere relaties, zoals ‘Insolventie’, niet dezelfde spreiding vertonen. De stippen geven uitschieters aan.
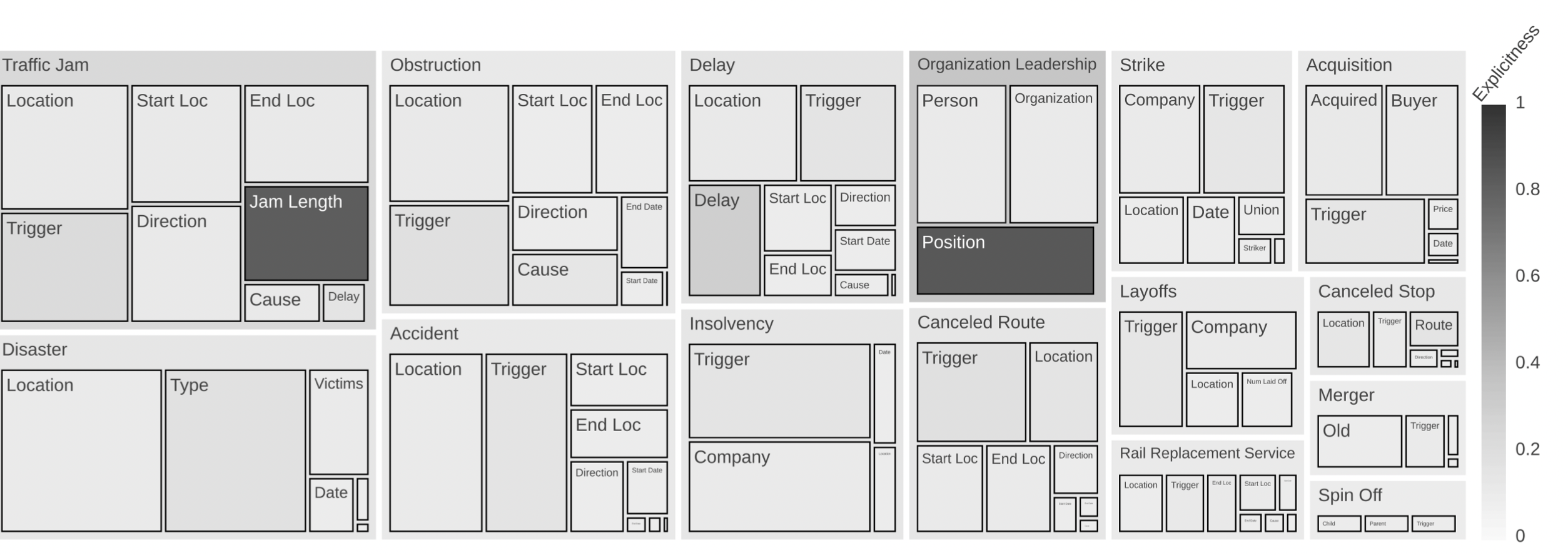
Figuur 3: Verdeling van relaties en attributen. De grootte van de rechthoeken is evenredig aan de frequentie van de relatie of het attribuut. De explicietheid is het quotiënt van de frequentie van het attribuut en het totale aantal entiteiten met een entiteitstype dat geschikt is voor de specifieke rol van het attribuut. Deze maatstaf geeft aan hoe betrouwbaar een entiteitstype een relatieattribuut weergeeft.
Figuur 1 geeft het datameta-model weer. Merk op dat een relatie een variabel aantal attributen kan hebben en niet beperkt is tot een vast aantal. Voor de rol van elk attribuut kan een vaste reeks entiteitstypen geschikt zijn: zo kunnen entiteitstypen als Location-Street, Location-City of Location-Route door elkaar worden gebruikt als attribuut met de rol Location.
Hieronder lichten we de belangrijkste kenmerken van het SmartData-corpus toe.
Relaties. Het corpus bevat 15 relatietypen met twee verplichte en een aantal optionele attributen. Figuur 3 geeft een overzicht van de verdeling van de relaties en de attributen.
Entiteiten. SmartData biedt 16 gedetailleerde entiteitstypen. Zie (Schiersch et al., 2018) voor een volledige lijst. We introduceren explicietheid als maatstaf om aan te tonen dat slechts enkele entiteitstypen een sterke indicator zijn voor een relatie (zie bijvoorbeeld ‘Jam Length’ of ‘Position’ in figuur 3). Daarom moeten MARE-modellen een gecombineerd beeld van entiteitscombinaties leren.
Variabel aantal relatieattributen. Elke relatie bevat ten minste één exemplaar van elk verplicht attribuut. Ze kunnen al dan niet aanvullende optionele attributen bevatten. Het voorbeeld van betwistbare verschillen in figuur 5 toont een RSS-feed met een Obstruction-relatie. Alleen de attributen trigger en location zijn verplicht. StartLoc en EndLoc zijn optionele attributen.
Onevenwichtig. Onevenwichtige datasets vormen een uitdaging om de essentiële structuur te achterhalen voor zowel de ondervertegenwoordigde gegevenspunten als de andere, beter vertegenwoordigde gegevenspunten (Mountassir et al., 2012). De dataset is zowel wat betreft relaties als wat betreft attributen onevenwichtig (zie figuur 3): Traffic Jam komt ongeveer 10 keer vaker voor dan Spin Off. Terwijl de frequenties van de attributen van Spin Off vrijwel gelijk zijn, vertonen de attributen van Traffic Jam een verschil in de verdeling van de attributen, wat overeenkomt met verplichte en optionele attributen.
Onjuiste triggers. In andere corpora voor gebeurtenis-extractie zijn de triggers strikt gedefinieerd als één enkel verplicht token of span, vanwege de essentiële rol ervan als relatie-indicator (Consortium, 2005; Aguilar et al., 2014). SmartData volgt deze beperkingen niet: de triggers zijn optioneel en niet gebonden aan opeenvolgende tokens of een specifiek lemma of woordsoort. Dit corpus belemmert dus de toepassing van huidige benaderingen voor gebeurtenis-extractie vanwege hun aanname dat er één trigger-token/span bestaat.
Relaties en entiteiten. In één document kunnen meerdere relaties voorkomen. De entiteiten van de betreffende relaties hoeven niet los van elkaar te staan: zo komen bijvoorbeeld ‘Verkeersopstopping’ en ‘Belemmering’ vaak samen voor en delen ze locatiekenmerken.
Verschillende taalregisters. SmartData maakt gebruik van verschillende gegevensbronnen, wat leidt tot uiteenlopende distributies en patronen die modellen moeten leren. Terwijl nieuwsartikelen uit samenhangende en grammaticaal correcte teksten bestaan, bestaan Twitter- en RSS-feeds vaak uit zinsfragmenten.
Het SmartData-corpus bevat relaties met een variabel aantal attributen en zonder vaste triggerdefinitie, waardoor het corpus voldoet aan de MARE-definitie. Er zijn aanpassingen nodig om de huidige methoden voor relatie- of gebeurtenis-extractie toe te passen.
2 https://github.com/DFKI-NLP/smartdata-corpus
3 Duits Onderzoekscentrum voor Kunstmatige Intelligentie (Vertaling: German Research Center for Artificial Intelligence)
4 De cijfers wijken af van die in het oorspronkelijke artikel vanwege verschillende versies
4. GROOT
In dit hoofdstuk wordt het concept van multi-attribute relatie-extractie formeel geïntroduceerd en worden twee MARE-benaderingen besproken. We beschrijven onze evaluatiemethodologie, die onder meer bestaat uit de aanpassing van een benadering voor de extractie van gebeurtenissen en binaire relaties. We vergelijken beide benaderingen met de MARE-benaderingen.
4.1 Definitie
Voor een bepaalde tekst t = (t1,…,tn) met n tokens,
S = {(ti,…,tj) | voor alle i, j ∈ {1,…,n}, waarbij i ≤ j}
duidt de verzameling van alle tekstfragmenten aan. Stel dat L een verzameling van relatielabels is en Al een verzameling van attribuutrollen voor elk relatielabel l ∈ L. De taak bestaat erin een relatieverzameling R te voorspellen voor een gegeven tekst t. Elk relatie-exemplaar r ∈ R
r = (l, {α_i | voor alle i ∈ {1,…,m}})
bestaat uit een relatielabel l en een variabel aantal
0 < m ≤ |S| attributen
αi = (s,a) ∈ S×Al voor alle i ∈ {1,…,m}.
Elke span s ∈ S kan in elke relatie r ∈ R aan hoogstens één attribuut bijdragen. Een span kan echter bijdragen aan attributen in meerdere relaties. We staan expliciet relaties met één attribuut toe. We duiden tekstspans si j aan met i en j als begin- en eindindex. Verder,
A = ∪₍₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎��
is de verzameling van alle attribuutrollen.
De formele definitie maakt geen onderscheid tussen verplichte en optionele attributen, zoals in paragraaf 3. We hanteren dit onderscheid nog steeds bij de modelevaluatie, aangezien een hogere frequentie van een attribuutrol duidt op betere extractieresultaten.
4.2 Benaderingen
Alle benaderingen, met uitzondering van de basislijnen, maken gebruik van transformatornetwerken als contextuele inbedders. Dergelijke netwerken berekenen contextuele representaties door middel van een combinatie van meerdere self-attention- en feed-forward-lagen. Ze worden op een onbegeleide manier getraind (Devlin et al., 2019). We passen een Duitse versie van ELECTRA5 toe (May en Reißel, 2020). De pretrainingstaken daarvan richten zich op het vermogen van de modellen om de semantische structuur van teksten te beschrijven (Clark et al., 2020). Alle benaderingen maken gebruik van de versie van het Adam-optimalisatiealgoritme met gewichtsverval, geïntroduceerd in (Loshchilov en Hutter, 2019).
Hieronder hanteren we de definities die in paragraaf 4.1 zijn geïntroduceerd.
4.2.1 Sequentietagging
Het onbekende aantal attributen in MARE vereist modellen die niet alle mogelijke relaties hoeven op te sommen. (Zheng et al., 2017) introduceerden een tagging-schema om de extractie van binaire relaties te formuleren als een sequentie-taggingprobleem.
T = {b, i} × L × A ∪ {o}
beschrijft onze set van tags. Tags die beginnen met b en i markeren tokens als het begin of het binnenste deel van een entiteit. Voor de resulterende entiteitsspannen bepaalt het label l ∈ L de relatie, en bepaalt a ∈ Al de attribuutrol voor een relatie die door l wordt bepaald. o markeert tokens die niet tot een attribuut behoren.
Uit elke gemarkeerde reeks tokens halen we een reeks niet-coherente relatieattributen. Deze attributen worden op basis van hun relatielabel samengevat tot relatie-instanties.
De ingebedde en gecontextualiseerde invoerreeks vormt de invoer voor een feed-forward-laag, die deze reeks omzet in labelkansen. Een conditioneel willekeurig veld bepaalt het verlies en de meest waarschijnlijke labelreeks. (Huang et al., 2015) beschrijft de details van conditionele willekeurige velden voor sequentietagging.
Ons model voor sequentietagging vermijdt het opsommen van alle mogelijke relatiekandidaten. Dit brengt echter ook de volgende twee beperkingen met zich mee:
1. Gemeenschappelijke attributen in relaties. Meerdere relaties kunnen attributen hebben met overlappende tekstfragmenten. Ons tagging-schema kan elk fragment aan hooguit één relatie toewijzen.
2. Meerdere relaties met hetzelfde label. Een steekproef kan meerdere relaties met hetzelfde relatielabel bevatten. Bijvoorbeeld twee ongevalsbeschrijvingen in één steekproef. Door op basis van het label te groeperen, ontstaat er één enkele relatie in plaats van meerdere exemplaren.
We introduceren een laag met bedrijfslogica om dergelijke situaties op te vangen. Wanneer een attribuut zich over meerdere relaties uitstrekt, controleren we of er in de huidige relaties verplichte attributen ontbreken. Als dat het geval is, zoeken we naar attribuuttypen die wijzen op gedeelde argumenten. Als een dergelijk attribuut binnen de maximale relatiebreedte6 valt, gebruiken we het om de relatie aan te vullen.
Hieronder gaan we ervan uit dat de attributen van een relatie gesorteerd zijn op basis van hun span-indexen. Om meerdere relaties met hetzelfde label in één steekproef te verwerken, splitsen we een gegroepeerde relatie α1,…,αn op index i < n, mits de deelverzamelingen α1,…,αi en αi+1,…,αn alle verplichte attributen bevatten en de afstand tussen αi en αi+1 groter is dan de maximale relatiebreedte.
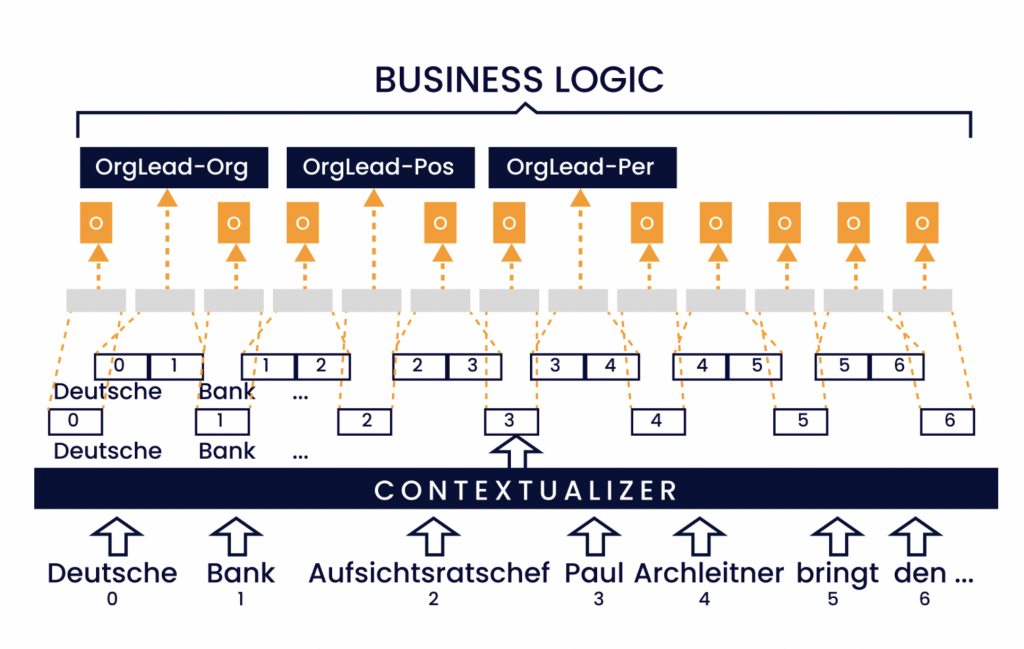
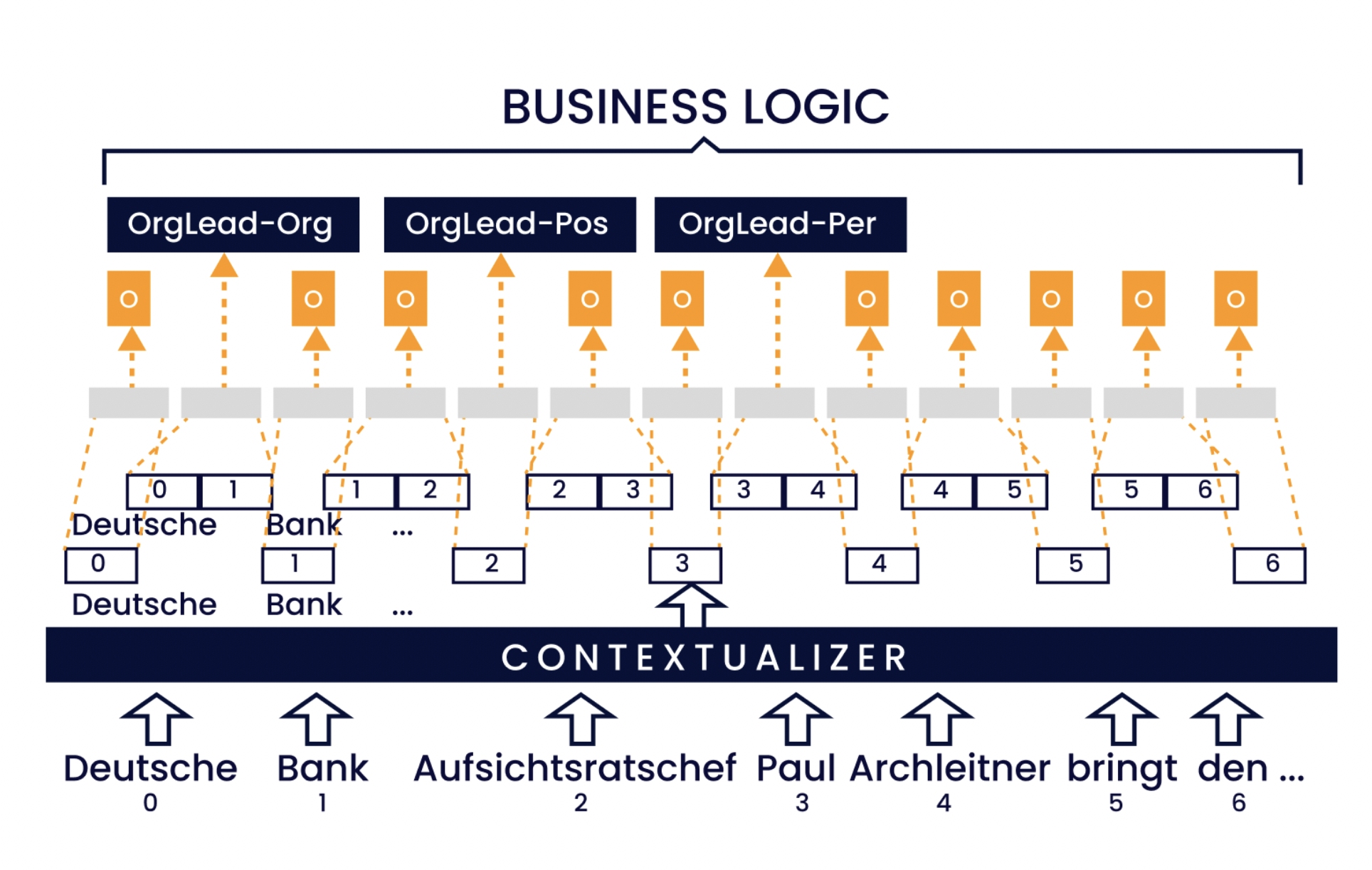
Figuur 4: Illustratie van de benadering met span-labels. De invoerreeks wordt ingebed en in context geplaatst. Elke tekst-span binnen een maximale span-breedte (in dit voorbeeld 2) wordt omgezet in een weergave met vaste lengte, voorzien van een combinatie van een relatielabel en een argumentrol. Ten slotte groepeert de bedrijfslogica de attributen bij de relaties.
4.2.2 Aanduiding van overspanningen
Onze tweede benadering is geïnspireerd op (Liu et al., 2019). Zij pasten een benadering met sequentielabeling toe in plaats van sequentietagging. Met labeling kunnen aan elk tekstfragment meerdere attribuutlabels worden toegekend. Wij passen deze benadering aan en voorspellen voor elk mogelijk tekstfragment in een bepaalde steekproef een relatie-attribuutlabel. Net als bij onze benadering met sequentietagging hoeft bij deze benadering niet alle mogelijke relaties te worden opgesomd, en wordt de beperking van gedeelde attributen tussen relaties opgelost.
Laat T = L×A een verzameling labels zijn die de relatielabel en de attribuutrol voor een bepaald tekstfragment aangeven. Het model voorspelt een waarschijnlijkheid P(t|s) voor elk label t ∈T en elk fragment s ∈S. Een hyperparameter voor de maximale fragmentbreedte bepaalt het maximale aantal tokens per fragment in S. We passen een binaire kruisentropieverliesfunctie toe, waardoor per fragment meerdere labels kunnen worden toegewezen.
Figuur 4 illustreert de architectuur van ons model. De span-representaties worden berekend met een op self-attention gebaseerde module uit AllenNLP7. Voor een gegeven tekst met lengte n berekenen we gecontextualiseerde embeddings (c1,…,cn) van dimensie d. Voor elke span sij hebben we j−i+1 embeddings (ci,…,cj). Om een span-representatie met vaste lengte en dimensie d te verkrijgen, berekenen we een lineaire combinatie van deze embeddings. Een parametermatrix M ∈ Rd×1 berekent globale aandachtsscores ai = ci ·M voor alle i ∈ {1,…,n}. Deze worden gebruikt om gewichten wi,…,wj te berekenen voor een span sij, met
piek
wk = a voor alle k in {i,…,j}.
De som van de gehele getallen van i tot en met j is
De softmax-functie zorgt ervoor dat de gewichten voor elke span samen 1 opleveren. De uiteindelijke span-representaties zijn een lineaire combinatie van deze gewichten en de inbeddingen.
Een feedforward-laag in combinatie met de elementgewijze sigmoïde functie berekent de labelkansen voor elke span. Net als bij de vorige aanpak leidt dit tot een reeks gegroepeerde relatie-instanties. We passen dezelfde bedrijfslogica toe als in paragraaf 4.2.1, aangezien de beperking van meerdere relaties met hetzelfde label blijft bestaan.
4.2.3 Gebeurtenis-extractie
Om methoden voor gebeurtenis-extractie toe te passen, moeten we voor elke relatie met meerdere attributen een gebeurtenistrigger specificeren. Zoals in paragraaf 3 wordt aangetoond, zijn sommige instanties in de
Het SmartData-corpus bevat dergelijke annotaties niet. Als een relatiedefinitie geen verplicht triggerattribuut heeft, hebben we voor elke relatie één verplicht attribuuttype als trigger gedefinieerd. In het geval van meerdere en niet-samenhangende trigger-spans kiezen we de eerste span als trigger. We hebben geen complexere logica toegepast, aangezien de set relaties met meerdere triggers (78 van de 1264) relatief klein is. De eerste foutsituatie in paragraaf 4.2.1 is onopgelost als relaties triggers delen. Andere attributen kunnen door relaties worden gedeeld.
We passen Dygie++8 toe als methode voor het extraheren van gebeurtenissen. Zoals beschreven in (Wadden et al., 2019) maakt Dygie++ gebruik van contextgebonden span-representaties, vergelijkbaar met paragraaf 4.2.2. Bij het detecteren van triggers en het verduidelijken van attributen wordt gebruikgemaakt van deze gedeelde span-representaties.
4.2.4 Extractie van binaire relaties
Veel methoden voor het extraheren van binaire relaties classificeren alle mogelijke paren van entiteiten als relatiekandidaten, zoals SpERT (Eberts en Ulges, 2019). In combinatie met multi-class labeling lost dit beide foutgevallen uit paragraaf 4.2.1 op.
We passen SpERT toe om binaire relaties te extraheren uit 1.717 van de 1.864 voorbeelden in de trainingsset die relaties bevatten met precies twee verplichte attributen. In de volgende paragraaf worden verschillende evaluatiestrategieën besproken. We introduceren een strategie voor het extraheren van binaire relaties om de prestaties van SpERT te vergelijken met die van alle andere benaderingen op de subset van geldige binaire relaties.
4.3 Proefopstelling
We hebben AllenNLP (Gardner et al., 2017) en PyTorch gebruikt om de methode voor sequentietagging en spanlabeling te implementeren. Onze GitHub-repository bevat aangepaste versies van Dygie++ en SpERT. Deze aanpassingen waren nodig om beide methoden in onze experimentele infrastructuur te integreren.
Onze GitHub-repository bevat een overzicht van alle hyperparameters en hun waarden in de uiteindelijke modellen. Alle hyperparameters zijn bepaald met Optuna9. We hebben voor elk model 50 optimalisatierondes uitgevoerd. We hebben de leersnelheid voor de embeddinglaag van het transformatornetwerk vastgesteld op 5 · 10−5 en op 10−3 voor alle andere netwerkcomponenten. We hebben voor alle MARE-benaderingen een batchgrootte van 6 gekozen, en voor SpERT en Dygie++ een batchgrootte van 1.
We maken gebruik van verschillende evaluatiestrategieën om de voorspellingen te analyseren. Deze strategieën zijn erop gericht om de uitdagingen van MARE op verschillende complexiteitsniveaus weer te geven.
• Attribuutherkenning (AR) De evaluatie vindt per attribuut plaats. Een attribuut wordt als correct beschouwd als de grenzen, het relatielabel en de attribuutrol ervan correct zijn voorspeld, zonder rekening te houden met de indeling in een relatie.
• Classificatie (Cl) Een voorspelling is correct als het voorspelde label overeenkomt met een referentielabel.
• Verplichte relatie-extractie (MRE) Een voorspelling is correct als alle verplichte attributen en het relatielabel overeenkomen met de referentie-annotatie. Het is dus van essentieel belang dat de verplichte attributen tot één relatie worden gegroepeerd.
• Complete Relation Extraction (CRE) meet het vermogen van het model om de relatie met alle attributen als geheel te extraheren. Een voorspelling wordt dus als correct beschouwd als het model alle attributen extraheert en deze correct groepeert in een relatie met het juiste relatielabel.
• Extractie van binaire relaties (BRE) Dit is de MRE-strategie toegepast op de deelverzameling van voorbeelden die uitsluitend relaties bevat met precies twee verplichte argumenten. Deze strategie maakt een vergelijking mogelijk tussen SpERT en alle andere benaderingen.
We nemen de baseline (DARE) uit (Schiersch et al., 2018) mee, die zich richt op de verplichte argumenten en gebruikmaakt van ‘gold’ entiteitsannotaties. Onze eigen baseline is een aanpassing van de sequentietagging-benadering. We vervangen het vooraf getrainde transformator-netwerk door een combinatie van GloVe10-woordvectoren (Pennington et al., 2014) en een CNN op tekenniveau als inbeddingslaag. Een Bi-GRU-laag geeft de inputs context.
Onze computeropstelling bestaat uit twee knooppunten met Intel Xeon Platinum 8168-processoren, Nvidia Quadro P5000-grafische kaarten met 16 GB RAM en het besturingssysteem Ubuntu 18.04. Het doorzoeken van de hyperparameters nam ongeveer 24 uur in beslag.
5 https://huggingface.co/german-nlp-group/ electra-base-german-uncased
6 De maximale relatiebreedte is een hyperparameter en wordt bepaald door middel van een hyperparameterzoekproces. De GitHub-repository bevat de zoekconfiguratie en de uiteindelijke waarden.
7 http://docs.allennlp.org/main/api/modules/ span-extractors/zelflerende span-extractor/
8 https://github.com/dwadden/dygiepp
9 https://optuna.org/
5. Resultaten
De statistieken in tabel 2 meten verschillende capaciteiten die nodig zijn om alle attributen, hun rollen en het relatielabel in combinatie te extraheren. Over het algemeen geldt dat naarmate de eisen van de statistieken strenger worden, de waarden van de statistieken dalen.
De benadering met span-labeling verhoogt de F1-scores voor gebeurtenis-extractie met 0,06 voor AR en met 0,04 voor Cl. We constateren dat beide MARE-benaderingen op de volledige dataset beter presteren dan Dygie++. De vergelijkbare MRE-score en de hogere AR- en CRE-scores geven aan dat MARE-modellen optionele en mogelijk minder vaak voorkomende argumenten betrouwbaarder extraheren. Een beperking tot de subset van documenten met precies twee verplichte argumenten leidt tot hogere algemene scores, maar een veel grotere stijging voor Dygie++ dan voor de MARE-modellen. Beide observaties geven aan dat modelarchitecturen met minder structurele aannames beter geschikt zijn voor de unieke kenmerken van het corpus, zoals beschreven in paragraaf 3.
Tabel 2: Modelevaluatie op de testdataset op basis van verschillende strategieën, zie paragraaf 4.3. Precisie, recall en F1-score dienen als vergelijkingsmaatstaven.
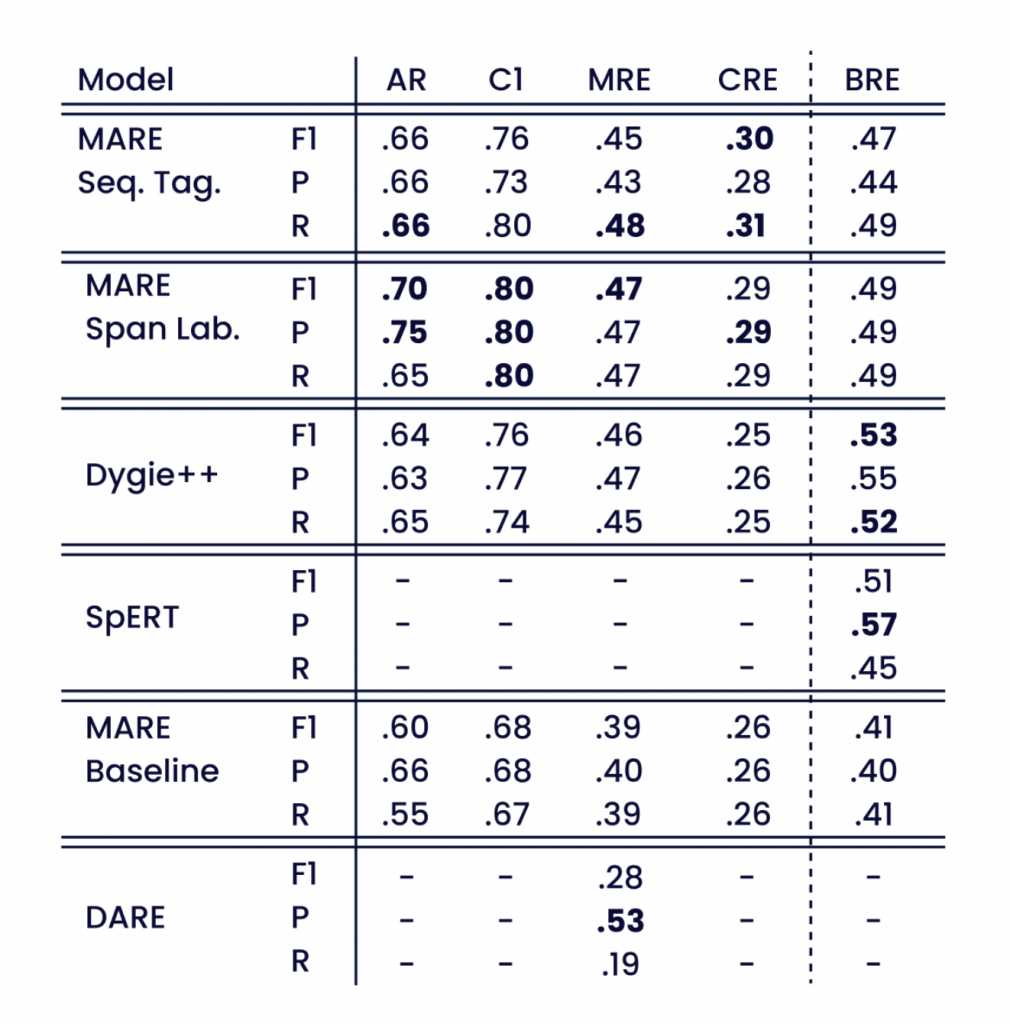
Het verschil tussen de MARE-baseline en beide MARE-benaderingen toont het positieve effect van vooraf getrainde transformatornetwerken aan. Ondanks de over het algemeen zwakkere prestaties van DARE, dat gebruikmaakt van een automatisch geselecteerde regelset, behaalt de oorspronkelijke benchmark de hoogste MRE-precisiescore. Dit duidt op een hoge mate van zekerheid wat betreft de geëxtraheerde relaties en een groot aantal valse negatieven als gevolg van de lage recall-score.
Uit de evaluatie van SpERT blijkt een duidelijke verbetering ten opzichte van onze MARE-referentie. SpERT presteert ook beter dan onze MARE-modellen op BRE.
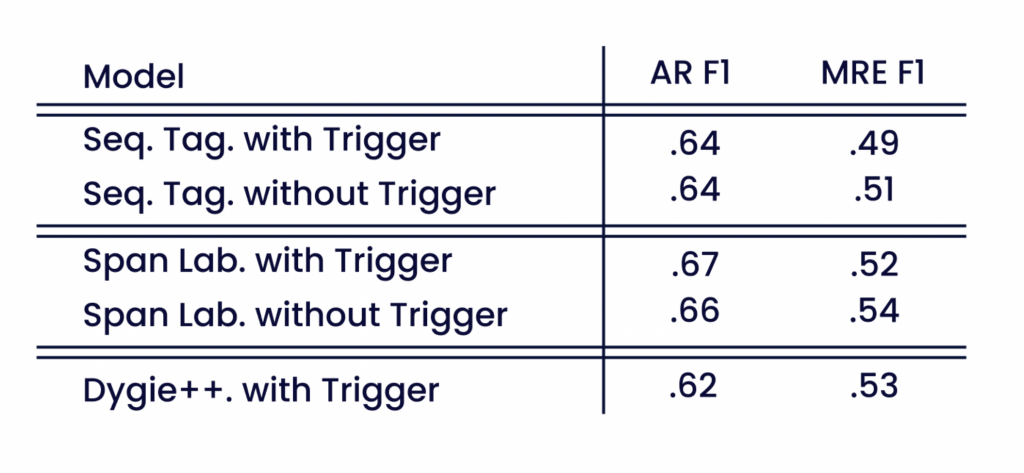
Tabel 3 laat zien hoe triggerannotaties de prestaties van MARE-modellen beïnvloeden. Uit evaluaties op de beperkte set van niet-triggerattributen van MARE-modellen die zowel met als zonder triggerannotaties zijn getraind, blijkt geen significant verschil in AR- en MRE-scores. De prestaties van onze modellen zonder triggerannotaties zijn vergelijkbaar met de state-of-the-art gebeurtenis-extractie op multi-attribuutrelaties uit het Smart-Data-corpus. De AR-score van de MARE-modellen is beter dan die van Dygie++. Dat bewijst het vermogen van MARE om optionele en minder frequente attributen te extraheren.
In vergelijking met tabel 2 dalen de AR-scores, wat erop wijst dat de modellen de triggerattributen betrouwbaar identificeren. Zonder triggerattributen blijven veel relaties met slechts één attribuut over. Dit vereenvoudigt de MRE-taak en leidt tot hogere MRE-scores.
Aangezien het extraheren van relaties een taak op hoog semantisch niveau is en de referentie-annotaties van SmartData een zekere mate van inconsistentie vertonen, voeren we een handmatige foutanalyse uit om de voorspellingskenmerken van onze modellen beter te begrijpen.
5.1 Foutcontrole
We hebben de verschillen tussen de gouden annotaties en de voorspellingen van de modellen handmatig vergeleken. Uit onze handmatige controle komen de volgende foutklassen naar voren. Alle voorbeelden die in de onderstaande opsomming worden genoemd, hebben betrekking op figuur 5.
1. Betwistbare verschillen De voorspellingen van de modellen zijn vaak redelijk, zelfs als de referentiegegevens afwijkende annotaties bevatten. Het voorbeeld toont een Obstruction-relatie, waarbij de marathon de Obstruction-Cause vertegenwoordigt. De referentie-annotatie geeft deze situatie niet weer. Betwistbare verschillen wijzen erop dat onze modellen bepaalde semantische concepten hebben geleerd. Sommige generalisaties in de voorspellingen leiden tot valse positieven, waardoor de evaluatiestatistieken dalen.
2. Relatieklassen met een sterke semantische band Bepaalde relatieklassen, zoals Ongeval en Belemmering, hebben een sterke semantische band. Daarom zijn instanties van deze relaties vaak genest en delen ze entiteitsbereiken als attributen. De annotaties van deze gedeelde attributen zijn vaak gebrekkig. Het voorbeeld toont een Obstructie veroorzaakt door een Ramp. De gouden annotatie bevat twee afzonderlijke relaties en drukt deze afhankelijkheid niet uit. De aanleiding van de Ramp zou ook kunnen worden geïnterpreteerd als de oorzaak van de Obstructie. Dit onderscheid vormt een uitdaging voor de modellen.
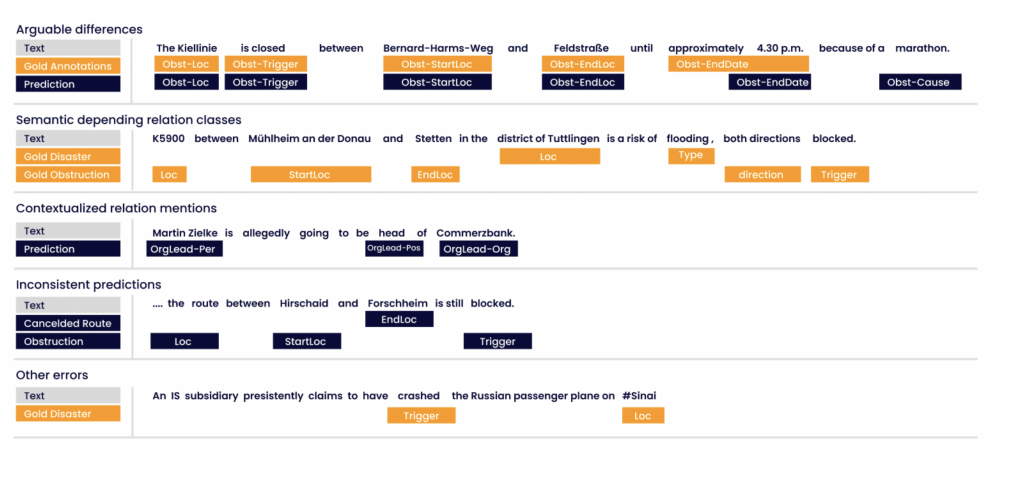
Figuur 5: Voorbeelden van foutklassen. De gekleurde vakjes geven de relaties en hun kenmerken weer. De rol van de kenmerken is tekstueel aangegeven. Voorspellingen op basis van de span-labeling-methode.
3. Relatievermeldingen in een contextuele context Veel vermeende relatievoorbeelden komen voor in een context waarin veronderstellingen worden gedaan. Woorden als ‘naar verluidt’ duiden op veronderstellingen in plaats van feiten. Het voorbeeld illustreert een veronderstelling over het leiderschap van een organisatie. In veel van deze gevallen voorspelden de modellen relatievoorbeelden.
4. Inconsistente voorspellingen Het voorbeeld toont een Obstruction-relatie, waarbij het model alle rollen correct heeft voorspeld. Het relatielabel voor de eindlocatie behoort tot een vergelijkbare semantische relatie. Als de ontbrekende attributen niet verplicht zijn, kunnen dergelijke situaties niet door de bedrijfslogica worden opgelost.
5. Overige fouten Veel relaties worden door de modellen niet herkend. Dergelijke fouten komen vaak voor in zinnen met een minder strakke grammaticale structuur en in zinnen die veel speciale tekens bevatten, zoals ’@’, ’#’ of typische triggerzinnen die bij geen enkele relatie horen. Het voorbeeld toont een ramp die door geen enkel model werd voorspeld.
Uit de resultaten blijkt dat de huidige methoden voor het extraheren van gebeurtenissen of binaire relaties beter presteren dan MARE-modellen bij het extraheren van binaire relaties. Wanneer we de structurele eisen echter versoepelen, komen MARE-modellen als betere keuze naar voren. De geïntroduceerde MARE-methoden maken het mogelijk om complexe relaties met meerdere kenmerken uit onbewerkte tekst te extraheren zonder dat alle mogelijke relaties moeten worden opgesomd. De beperkingen van onze methoden (zie paragraaf 4.2) hadden geen ernstige gevolgen voor het smart data-corpus.
10 https://deepset.ai/german-word-embeddings
6. Conclusie
We hebben de extractie van relaties met meerdere attributen geïntroduceerd en deze definitie onderscheiden van de gangbare terminologie, namelijk n-aire relatie-extractie en gebeurtenis-extractie. Onze probleemstelling leidt tot vereenvoudigde benaderingen voor het extraheren van relaties met een willekeurig aantal attributen, doordat we het gebruik van het opsommen van kandidaten en het triggerconcept vermijden.
MARE-modellen zijn superieur wanneer de relaties niet in een binair of gebeurtenisschema passen. Ze omzeilen structurele beperkingen en presteren beter dan de huidige geavanceerde methoden voor relatie- en gebeurtenis-extractie op het SmartData-corpus.
We zijn van plan om de resultaten van de handmatige analyse in de toekomst te gebruiken bij de ontwikkeling van verbeterde MARE-benaderingen. We willen vooral de beperkingen van de MARE-benaderingen aanpakken en de relatiespecifieke context daarin verwerken.
7. Bronnen
Aguilar, J., Beller, C., McNamee, P., Van Durme, B., Strassel, S., Song, Z., en Ellis, J. (2014). Een vergelijking van de gebeurtenissen en relaties in de annotatiestandaarden ACE, ERE, TAC-KBP en FrameNet. In Proceedings of the Second Workshop on EVENTS: Definition, Detection, Coreference, and Representation, pagina's 45–53, Baltimore, Maryland, VS. Association for Computational Linguistics.
Clark, K., Luong, M.-T., Le, Q. V., en Manning, C. D. (2020). ELECTRA: Tekstencoders vooraf trainen als discriminatoren in plaats van als generatoren. arXiv:2003.10555 [cs]. arXiv: 2003.10555.
Consortium, L. D. (2005). Ace (automatische inhoudsextractie): richtlijnen voor het annoteren van gebeurtenissen in het Engels. pagina 77.
Devlin, J., Chang, M.-W., Lee, K. en Toutanova, K. (2019). BERT: Voortraining van diepe bidirectionele transformers voor taalbegrip. arXiv:1810.04805 [cs]. arXiv: 1810.04805.
Eberts, M. en Ulges, A. (2019). Op span gebaseerde gezamenlijke entiteit- en relatie-extractie met Transformer-voortraining. arXiv:1909.07755 [cs]. arXiv: 1909.07755.
Gardner, M., Grus, J., Neumann, M., Tafjord, O., Dasigi, P., Liu, N. F., Peters, M., Schmitz, M., en Zettlemoyer, L. S. (2017). Allennlp: een platform voor diepgaande semantische verwerking van natuurlijke taal.
Hendrickx, I., Kim, S. N., Kozareva, Z., Nakov, P., Ó Seághdha, D., Pado, S., Pennacchiotti, M., Romano, L., en Szpakowicz, S. (2010). SemEval-2010 Taak 8: Multi-Way Classificatie van Semantische Relaties tussen Paren van Zelfstandige Naamwoorden. In Proceedings of the 5th International Workshop on Semantic Evaluation, pagina's 33–38, Uppsala, Zweden. Association for Computational Linguistics.
Huang, Z., Xu, W. en Yu, K. (2015). Bidirectionele LSTM-CRF-modellen voor sequentietagging. arXiv:1508.01991 [cs]. arXiv: 1508.01991.
Kim, J.-D., Pyysalo, S., Ohta, T., Bossy, R., Nguyen, N. en Tsujii, J. (2011a). Overzicht van de BioNLP Shared Task 2011. In: Proceedings of BioNLP Shared Task 2011 Workshop, blz. 1–6, Portland, Oregon, VS. Association for Computational Linguistics.
Kim, J.-D., Wang, Y., Takagi, T. en Yonezawa, A. (2011b). Overzicht van de Genia-taak in de BioNLP Shared Task 2011. In: Proceedings of BioNLP Shared Task 2011 Workshop, blz. 7–15, Portland, Oregon, VS. Association for Computational Linguistics.
Lai, P.-T. en Lu, Z. (2021). BERT-GT: Extractie van n-aire relaties tussen zinnen met behulp van BERT en de Graph Transformer. Bioinformatics.
Li, C. en Tian, Y. (2020). Ontwerp van een downstream-model voor een vooraf getraind taalmodel voor het extraheren van relaties. arXiv:2004.03786 [cs]. arXiv: 2004.03786 versie: 1.
Liu, Y., Li, A., Huang, J., Zheng, X., Wang, H., Han, W. en Wang, Z. (2019). Gezamenlijke extractie van entiteiten en relaties op basis van multi-labelclassificatie. In: 2019 IEEE Fourth International Conference on Data Science in Cyberspace (DSC), blz. 106–111.
Loshchilov, I. en Hutter, F. (2019). Decoupled Weight Decay Regularization. arXiv:1711.05101 [cs, math]. arXiv: 1711.05101.
May, P. en Reißel, P. (2020). German Electra: de onthulling.
Mintz, M., Bills, S., Snow, R. en Jurafsky, D. (2009). Distant supervision voor relatie-extractie zonder gelabelde gegevens. In Proceedings of the Joint Conference of the 47th Annual Meeting of the ACL and the 4th International Joint Conference on Natural Language Processing of the AFNLP: Volume 2 – ACL-IJCNLP ’09, deel 2, pagina 1003, Suntec, Singapore. Association for Computational Linguistics.
Mountassir, A., Benbrahim, H., en Berrada, I. (2012). Een empirisch onderzoek naar het probleem van onevenwichtige datasets bij sentimentclassificatie. In: 2012 IEEE International Conference on Systems, Man, and Cybernetics (SMC), blz. 3298–3303.
Peng, N., Poon, H., Quirk, C., Toutanova, K. en Yih, W.-t. (2017). Extractie van N-aire relaties tussen zinnen met behulp van grafische LSTM’s. Transactions of the Association for Computational Linguistics, 5:101–115.
Pennington, J., Socher, R. en Manning, C. (2014). GloVe: Global vectors for word representation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), blz. 1532–1543, Doha, Qatar. Association for Computational Linguistics.
Roller, R., Rethmeier, N., Thomas, P., Hübner, M., Uszkoreit, H., Staeck, O., Budde, K., Halleck, F., en Schmidt, D. (2018). Detecting Named Entities and Relations in German Clinical Reports. In Rehm, G. en Declerck, T., red., Language Technologies for the Challenges of the Digital Age, Lecture Notes in Computer Science, blz. 146–154, Cham. Springer International Publishing.
Schiersch, M., Mironova, V., Schmitt, M., Thomas, P., Gabryszak, A. en Hennig, L. (2018). Een Duits corpus voor gedetailleerde herkenning van benoemde entiteiten en het extraheren van relaties bij verkeers- en industriële gebeurtenissen. pagina 8.
Tsujii, J., Kim, J.-D. en Pyysalo, S., red. (2011). Verslag van de BioNLP Shared Task 2011-workshop, Portland, Oregon, VS. Association for Computational Linguistics.
Viera, A. J., Garrett, J. M., e.a. (2005). Inzicht in de overeenstemming tussen waarnemers: de kappa-statistiek. Fam Med, 37(5):360–363.
Wadden, D., Wennberg, U., Luan, Y., en Hajishirzi, H. (2019). Entiteit-, relatie- en gebeurtenis-extractie met contextgebonden span-representaties. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), pagina's 5784–5789, Hongkong, China. Association for Computational Linguistics.
Xiang, W. en Wang, B. (2019). Een overzicht van gebeurtenis-extractie uit tekst. IEEE Access, 7:173111–173137. Conferentienaam: IEEE Access.
Xu, F., Uszkoreit, H., Li, H., Adolphs, P. en Cheng, X. (2013). Domeinaanpassende relatie-extractie voor het semantische web.
Zheng, S., Wang, F., Bao, H., Hao, Y., Zhou, P. en Xu, B. (2017). Gezamenlijke extractie van entiteiten en relaties op basis van een nieuw tagging-schema. arXiv:1706.05075 [cs]. arXiv: 1706.05075.