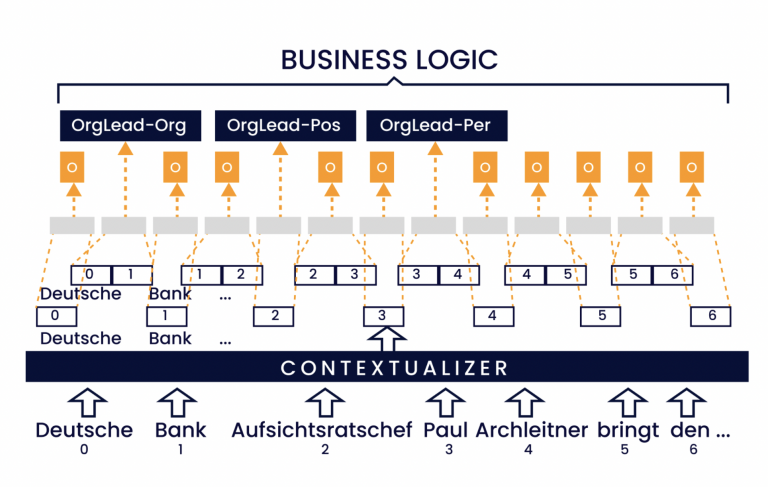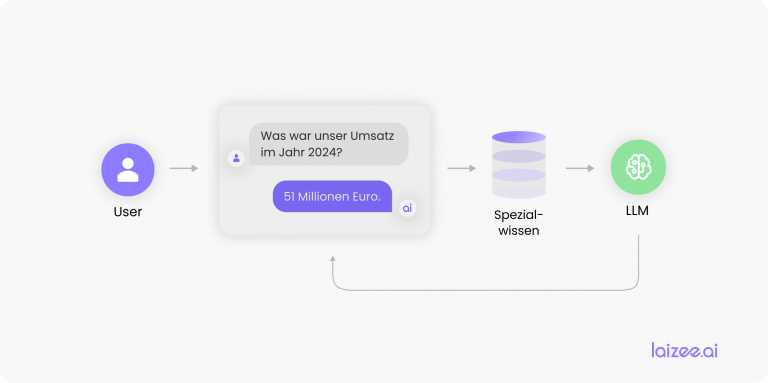
Er zijn momenteel maar weinig gebieden binnen de informatica die zo populair zijn als machine learning (ML) en met name het gebied van Natural Language Processing (NLP). Wie kent het niet: je smartphone of radio bedienen via een spraakassistent (Siri, Alexa, enz.)? Hoe fijn is het om gewoon het adres in te spreken waar je naartoe wilt? Zelfs het automatisch herkennen van klantvragen bij de automatische verwerking van brieven is mogelijk.
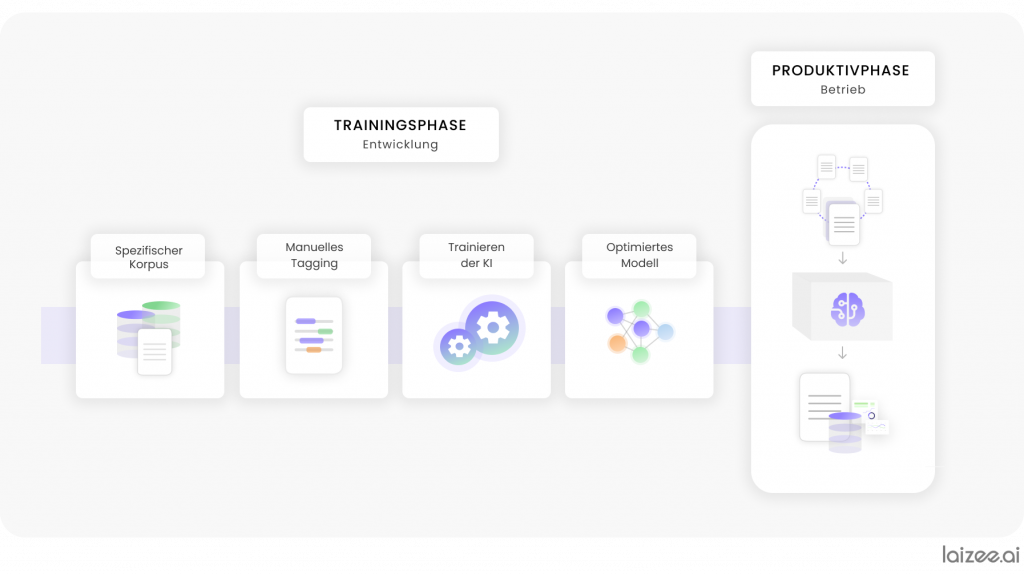
Ondanks de reeds beschikbare hulpmiddelen en gevestigde proces- en werkwijzemodellen, zoals bijvoorbeeld STAMP4NLP [1], blijft het ontwikkelen van een dergelijke toepassing nog steeds veel werk met zich meebrengen. Om de benodigde statistische modellen te kunnen trainen die patronen in gegevens kunnen herkennen voor informatie-extractie, moeten eerst geschikte gegevens worden geïdentificeerd en opgeschoond. Dit omvat zowel het corrigeren van spelfouten als het handmatig taggen, dat wil zeggen het markeren van elementen in de tekst. Op basis van het geannoteerde corpus wordt het model in de trainingsfase getraind en na voltooiing van de optimalisatie geïntegreerd in een AI-systeem dat productief kan worden ingezet (zie Figuur 1).
Een aspect dat bij de ontwikkeling van AI-systemen steeds meer in de belangstelling komt te staan, is gegevensbescherming [2]. Vanwege de grote complexiteit bij het ontwikkelen van NLP-toepassingen zijn veel bedrijven aangewezen op de hulp van externe bedrijven en ontwikkelaars. Daarbij moeten echter gegevens worden verstrekt die ook informatie bevatten die vanuit het oogpunt van gegevensbescherming gevoelig is, en op basis waarvan de nieuwe toepassingen worden getraind. Dit is het punt waarop het merendeel van deze bedrijven tot nu toe afziet van de invoering van NLP in hun eigen bedrijf, aangezien het anonimiseren van de gegevens veel moeite kost.
Met name door de Algemene Verordening Gegevensbescherming (AVG) van de EU heeft het onderwerp van gegevensanonymisering in overeenstemming met de privacywetgeving opnieuw aan belang gewonnen [3]. Vanwege de dreigende hoge boetes bij overtreding vormt gegevensbescherming momenteel een bijzonder groot obstakel voor de invoering van NLP.
Bestaande methoden waarmee gegevens die cruciaal zijn voor de privacy relatief eenvoudig door kunstmatige gegevens worden vervangen, zijn niet zonder meer bruikbaar. Dit wordt enerzijds verklaard door het betreffende toepassingsdomein. In de context van verzekeringen moeten bijvoorbeeld polisnummers, namen, gebeurtenisgegevens en adressen zeker als cruciaal worden beschouwd. In de context van medische gegevens moet daarentegen veel aandacht worden besteed aan kenmerken zoals lengte, gewicht, symptomen en diagnoses. Bijgevolg moeten voor elk domein eerst de kritieke kenmerken worden geïdentificeerd.
Daarnaast moet er rekening mee worden gehouden dat voldoende informatie wordt geanonimiseerd. Als het met de overgebleven informatie en door toevoeging van een andere gegevensbron weer mogelijk is om conclusies te trekken over de oorspronkelijke gegevens, is er geen sprake van een conclusievrije anonimisering. Een voorbeeld hiervan is het verwijderen van de naam en het adres, maar tegelijkertijd het behouden van de geboortedatum en het geslacht in een medisch rapport. Als men nu het bevolkingsregister erbij neemt en dit beperkt tot het verzorgingsgebied van het ziekenhuis, is identificatie van de betrokken persoon met weinig moeite mogelijk [4].
Anderzijds moet ook rekening worden gehouden met de keuze aan methoden. Hierbij zijn er bijvoorbeeld varianten beschikbaar die namen willekeurig vervangen door de 100 meest voorkomende namen in Duitsland. Een schematische 1:1-vervanging is echter ook denkbaar, of er zijn complexere methoden mogelijk. Daarbij mag de invloed van de anonimisering op het te trainen model niet buiten beschouwing worden gelaten. Als er tijdens de productieve werking van de NLP-toepassing een document opduikt met een naam die niet tot de 100 meest voorkomende behoort, kan deze onder bepaalde omstandigheden niet worden herkend. Bijgevolg moet rekening worden gehouden met het behoud van de gegevensvariatie binnen de geanonimiseerde attributen.
Daarnaast is het bij anonimisering ook belangrijk dat de onderlinge verbanden binnen de gegevens behouden blijven. Anders wordt er tussen de verschillende records niet herkend dat er naar dezelfde persoon wordt verwezen of dat de beschreven processen met elkaar verband houden. Over het geheel genomen beperken de huidige methoden het trainen van modellen op geanonimiseerde gegevens te sterk door het verlies van informatie.
Het doel is om een evenwicht te vinden tussen de naleving van de voorschriften inzake gegevensbescherming en het ontwikkelen van een hoogwaardige toepassing. In het volgende stappenplan wordt een mogelijke werkwijze weergegeven waarmee de invoering van NLP door middel van anonimisering haalbaar is.
Overzicht van de procedure
Laten we als voorbeeld een bedrijf nemen dat via een contactformulier met zijn klanten communiceert. Om te voorkomen dat elk bericht handmatig moet worden verwerkt, moeten deze zo veel mogelijk automatisch worden verwerkt.
De ontwikkeling van een dergelijke NLP-toepassing wordt uitgevoerd door een externe NLP-dienstverlener, die hiervoor de klantberichten opvraagt die het bedrijf heeft ontvangen. Aangezien deze berichten echter persoonsgegevens bevatten die onder de wetgeving inzake gegevensbescherming vallen, mag het bedrijf deze niet vrijgeven.
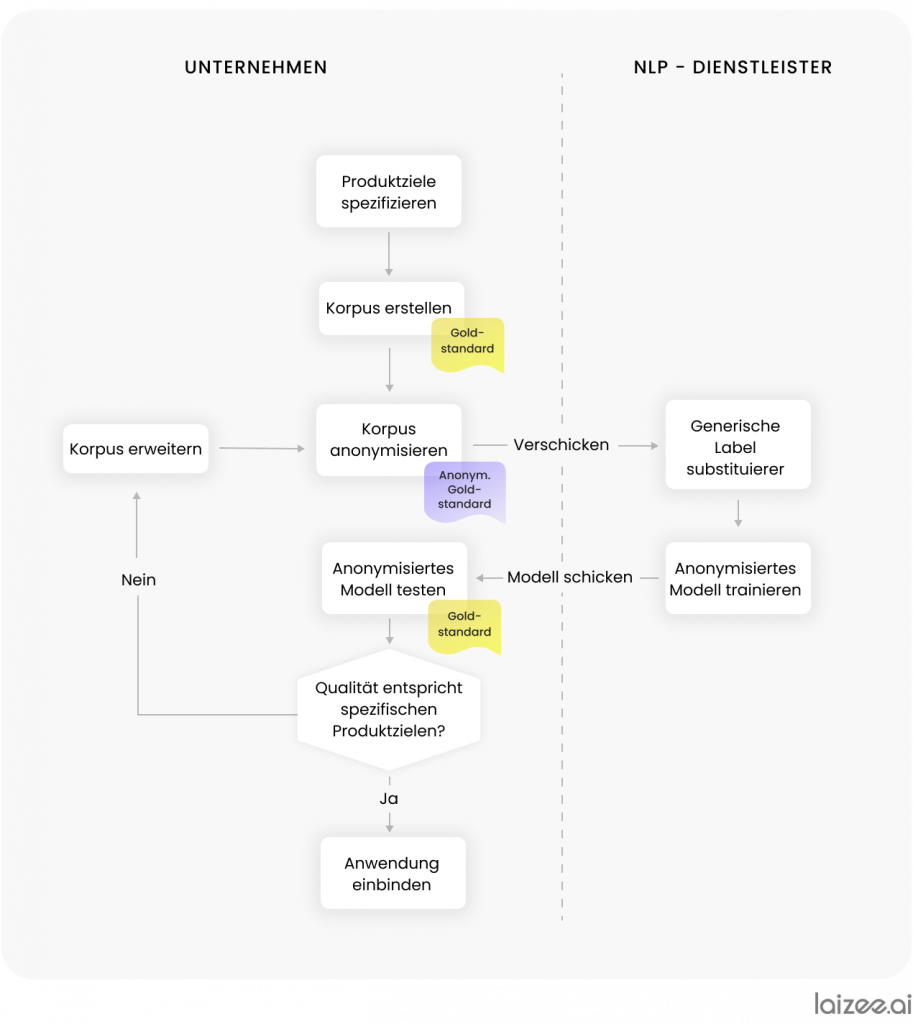
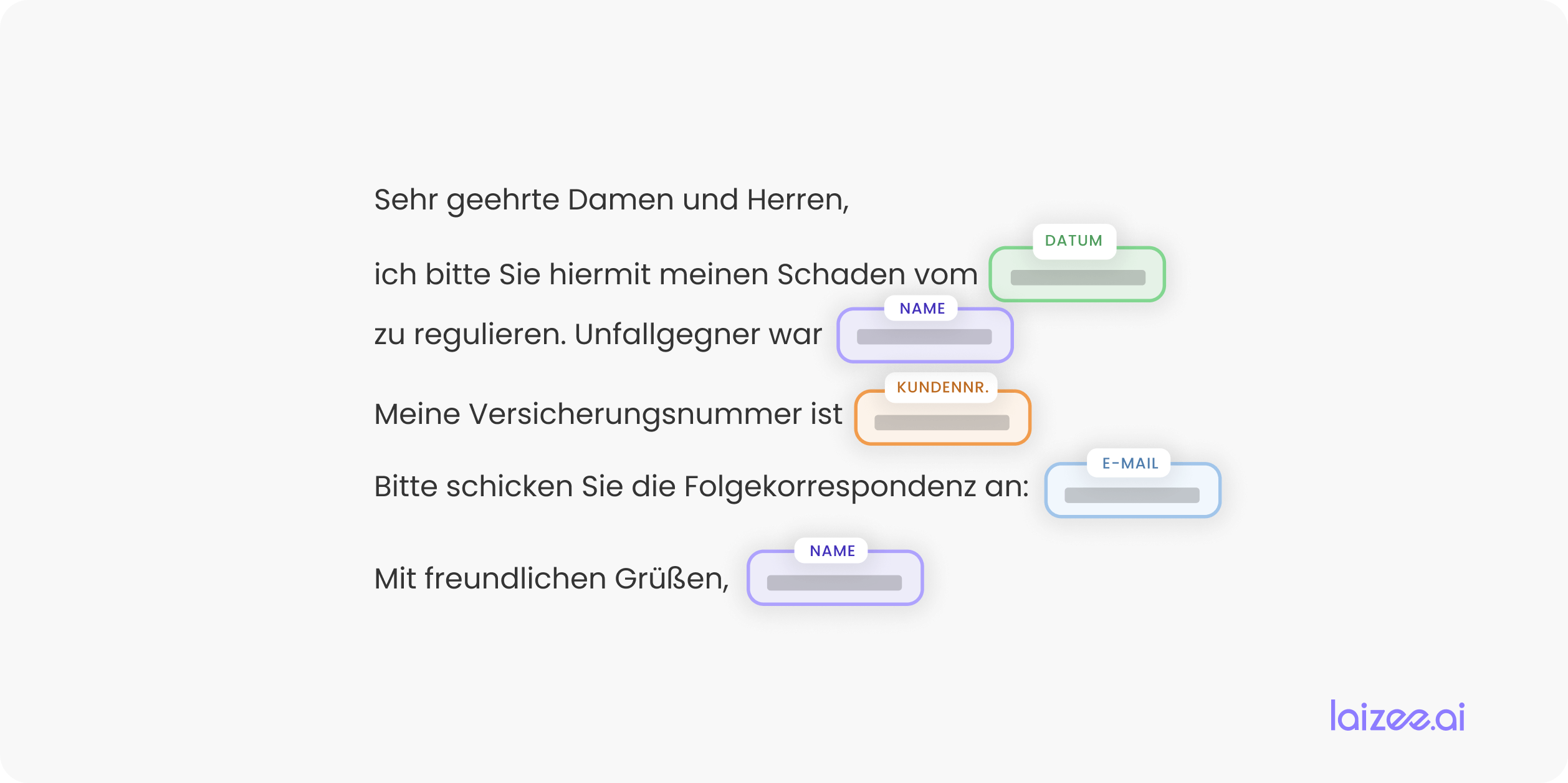
In overeenstemming met Figuur 2 Daarom wordt de volgende werkwijze toegepast: eerst stelt het bedrijf een corpus samen en voorziet dit van annotaties. Dit corpus wordt als gouden standaard opgeslagen. Vervolgens moet het corpus worden geanonimiseerd. Een veelgebruikte oplossing is dat medewerkers van het bedrijf de kritieke passages in de berichten markeren en deze vervangen door de bijbehorende labels.

Hiervoor moeten eerst alle domeinspecifieke categorieën van kritieke informatie worden geïdentificeerd. We nemen hier de verzekeringssector als voorbeeld. Dienovereenkomstig moeten naam, datum, klantnummer en e-mailadres, evenals eventuele andere kenmerken, worden uitgewisseld (zie Figuur 3).
Zodra de anonimisering is uitgevoerd, wordt het gegevensbestand met de geanonimiseerde e-mails naar de NLP-dienstverlener verzonden. Deze vervangt de labels door kunstmatige gegevens en genereert zo een gegevensbestand dat voldoet aan de privacywetgeving, dat verder mag worden gebruikt en een geanonimiseerde gouden standaard vormt. Vervolgens traint de dienstverlener een statistisch model voor informatie-extractie en ontwikkelt hij een passende NLP-AI-dienst.
De dienst en het model worden vervolgens overgedragen aan de opdrachtgever, waar ze worden getest op de verwerkingskwaliteit van e-mails. Hierbij wordt gebruikgemaakt van de in het begin vastgelegde gouden standaard. Met behulp van verschillende statistieken wordt de extractienauwkeurigheid van de applicatie afgemeten aan de vooraf gespecificeerde productdoelstellingen. Mocht de kwaliteit onvoldoende zijn, dan wordt geëvalueerd of het anonimisatieproces moet worden aangepast of het corpus moet worden uitgebreid, en wordt de applicatie opnieuw herzien.
Als de kwaliteit van de implementatie aan alle criteria voor productief gebruik voldoet, wordt de applicatie in de bestaande processen geïntegreerd. Er moet regelmatig worden gecontroleerd of de implementatie nog steeds probleemloos functioneert of dat er een aanpassing nodig is.
Een alternatief voor het inschakelen van dienstverleners?
Als alternatief voor het inschakelen van externe dienstverleners zijn er moderne low-code-platforms die ‘on premise’ worden gehost. Met ‘low-code’ wordt hier bedoeld dat ook leken in staat worden gesteld om hoogwaardige NLP-modellen te ontwikkelen. Open-platformoplossingen, zoals die van de start-up TaggingMatters van de FH Aachen (https://taggingmatters.de/), houden rekening met gegevensbescherming en verbergen tegelijkertijd de complexiteit van de gebruikte frameworks. Daardoor hoeven medewerkers in bedrijven geen experts te worden in de uitgebreide NLP- of ML-tools, zoals spaCy of TensorFlow, en de wiskunde achter moderne methoden, maar kunnen ze zich concentreren op de activiteiten die waarde toevoegen.
Dergelijke platforms maken het mogelijk om, naast het voorbereiden van de gegevens (“tagging”), de AI op een geoptimaliseerde manier te ontwikkelen en AI-diensten aan te bieden. Hierdoor kunnen de hierboven beschreven iteraties vele malen sneller worden doorlopen, zelfs zonder ervaring met NLP. Uiteindelijk profiteert het bedrijf van lagere ontwikkelingskosten en een sneller rendement op de investering, want het eigenlijke doel, de verbetering van bedrijfsprocessen, mag niet uit het oog worden verloren.
Samenvatting
De invoering en aanscherping van gegevensbeschermingsrechten bemoeilijken de implementatie van NLP bij talrijke bedrijven in de meest uiteenlopende sectoren. Anonimisering voordat gegevens aan externe softwarebedrijven worden verstrekt of het gebruik van een low-code-platform kan hier uitkomst bieden. Een kritiek punt is de haalbare kwaliteit van de modellen die op geanonimiseerde gegevens zijn getraind en de meting daarvan door het opdrachtgevende bedrijf. Een iteratief optimalisatieproces voor het opstellen en optimaliseren van modellen met herhaaldelijke feedback is hierbij onontbeerlijk.
Met het oog op de toekomst zullen geautomatiseerde processen in de digitale context steeds belangrijker worden. Met name in het kader van de wet op de online-toegang (OZG) zullen steeds meer bedrijven er belang bij hebben hun processen te optimaliseren. Hiervoor zal steeds vaker externe ondersteuning nodig zijn, die kan worden gerealiseerd aan de hand van het hier getoonde stappenplan of door gebruik te maken van low-code-platforms.
Auteurs
Prof. dr. rer. nat. Bodo Kraft
Prof. dr. Bodo Kraft is oprichter en hoofd van het laboratorium Business Programming. Daar doet hij al meer dan tien jaar, samen met momenteel vijf promovendi, toepassingsgericht onderzoek op het gebied van computerlinguïstiek. De verschillende projecten hebben als gemeenschappelijk uitgangspunt de uitdaging om grote hoeveelheden documenten in natuurlijke taal efficiënt en geautomatiseerd te verwerken.
Het succesvol afstemmen van de oplossingen op het betreffende domein is hierbij van fundamenteel belang. Een ander aandachtspunt is een flexibele, kwaliteitsgerichte aanpak voor het ontwikkelen van softwaresystemen die in de praktijk bruikbaar en onderhoudbaar zijn.
Prof. dr. Matthias Meinecke
Prof. dr. Matthias Meinecke (hoogleraar Operations Management, bestuurslid van het Institut für Digitalisierung Aachen, FH Aachen) geeft les, doet onderzoek en adviseert op het gebied van de optimalisatie en automatisering van bedrijfsprocessen.
Samen met prof. dr. Kraft is hij coach van de start-up laizee.ai, die producten en diensten ontwikkelt voor de efficiënte, geautomatiseerde verwerking van menselijke taal ter optimalisatie van bedrijfsprocessen.
M.Sc. Ines Larissa Siebigteroth
M.Sc. Ines Larissa Siebigteroth heeft technomathematica gestudeerd aan de FH Aachen en de University of Wisconsin-Milwaukee en promoveert momenteel bij prof. dr. Bodo Kraft. Mevrouw Siebigteroth maakt deel uit van het Labor Business Programming. Haar focus ligt op NLP en in het bijzonder op het opstellen van hoogwaardige corpora die voldoen aan de privacywetgeving, met het oog op de geautomatiseerde verwerking van natuurlijke taal.
Verwijzingen
| [1] | P. Kohl, O. Schmidts, L. Klöser, H. Werth, B. Kraft en A. Zündorf, „STAMP 4 NLP – Een flexibel raamwerk voor de snelle ontwikkeling van kwaliteitsgerichte NLP-toepassingen,“ [Online]. Beschikbaar: https://link.springer.com/chapter/10.1007%2F978-3-030-85347-1_12. |
| [2] | Commissie voor gegevensethiek, „Aanbevelingen van de Commissie voor gegevensethiek voor de strategie inzake kunstmatige intelligentie van de Duitse regering,” [online]. Beschikbaar op: https://www.bmjv.de/SharedDocs/Downloads/DE/Ministerium/ForschungUndWissenschaft/DEK_Empfehlungen.pdf?__blob=publicationFile&v=2. |
| [3] | S. C. A. Probst Eide, „De huidige stand van zaken bij tools voor gegevensanonimisering,“ [online]. Beschikbaar op: https://www.it-finanzmagazin.de/entwicklungsstand-daten-anonymisierung-73373/. |
| [4] | D. Barth-Jones, „De ‘heridentificatie’ van de medische gegevens van gouverneur William Weld: een kritische heroverweging van de risico’s van identificatie op basis van gezondheidsgegevens en de bescherming van de privacy, toen en nu,“ [online]. Beschikbaar op: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2076397. [Geraadpleegd op 15-12-2021]. |