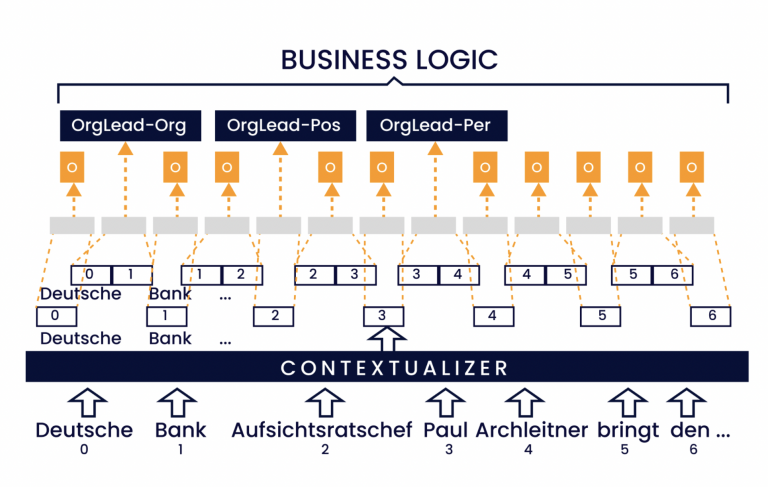
Da novembre 2021, il tema di ChatGPT e della tecnologia alla base dei modelli linguistici di grandi dimensioni (LLM) è onnipresente. Da un punto di vista puramente tecnico, il funzionamento degli LLM si basa sulla previsione della parola successiva. Ciò significa che la previsione di una parola avviene sulla base delle parole precedenti. Grazie all'enorme quantità di dati di addestramento e ai parametri del modello – GPT 3.5, ad esempio, è costituito da 175 miliardi di parametri – gli LLM sono in grado di «comprendere» diversi contesti e di riconoscere/riprodurre modelli linguistici e semantici più complessi.
Limiti
Ma al di là di tutto il clamore che circonda i modelli di linguaggio di grandi dimensioni (LLM), ci sono anche critiche fondate e problemi di prestazioni:
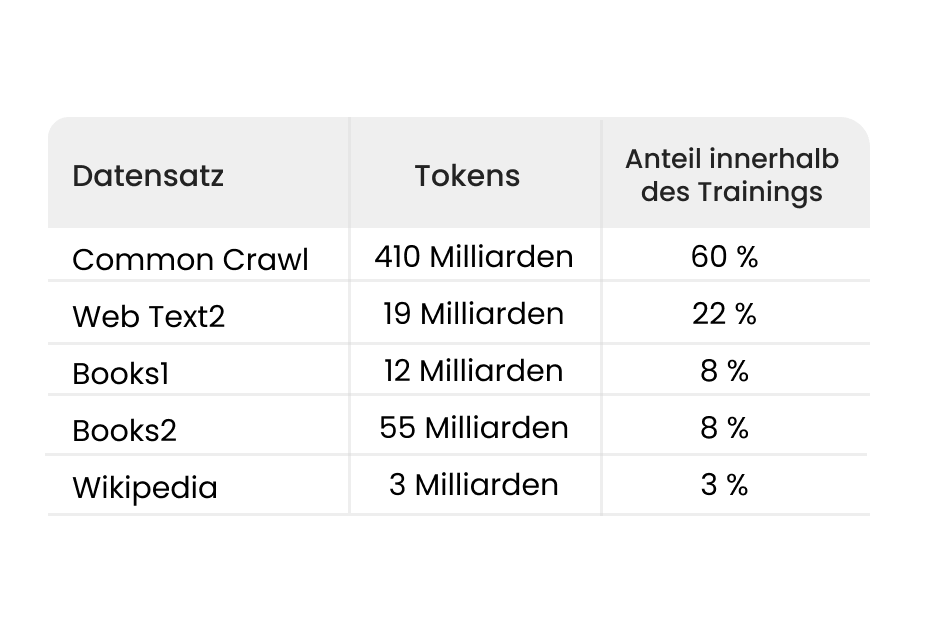
I modelli di linguaggio di grandi dimensioni (LLM) vengono addestrati su un volume di dati enorme. A tal fine vengono utilizzati, ad esempio, testi tratti da Wikipedia, notizie o dal cosiddetto CommonCrawl. I contenuti di questi set di dati sono nella maggior parte dei casi molto generici e poco specifici. Non vi si trovano argomenti di nicchia né informazioni provenienti, ad esempio, da libri meno conosciuti o protetti da licenze.
Al più tardi quando si sottopongono a un chatbot come ChatGPT delle richieste su argomenti di propria competenza – note anche come «prompt» – ci si rende conto che questi sistemi raggiungono rapidamente i propri limiti. Poiché i modelli di IA sottostanti non sono stati addestrati a sufficienza con informazioni relative a determinati argomenti, essi inventano risposte che a prima vista sembrano molto plausibili. Nel campo dell'IA, questo fenomeno viene definito "allucinazione". In altre parole, si potrebbe anche dire che il modello convincente Inventa fatti e genera così disinformazione.
Un altro problema è che i modelli di linguaggio di grandi dimensioni (LLM) vengono addestrati solo con dati che coprono un periodo fino a una determinata data di riferimento. Nel caso di GPT-3.5, ad esempio, tale data è giugno 2021. Di conseguenza, tutte le informazioni e i testi pubblicati dopo tale data non sono disponibili per il modello di IA. Un addestramento periodico dei modelli con ulteriori dati può aiutare a colmare questa lacuna, ma è molto costoso e richiede molto tempo.
I limiti e i problemi dei modelli di linguaggio di grandi dimensioni (LLM) ne limitano fortemente l'utilizzabilità per molti utenti, in particolare in ambiti altamente specializzati.
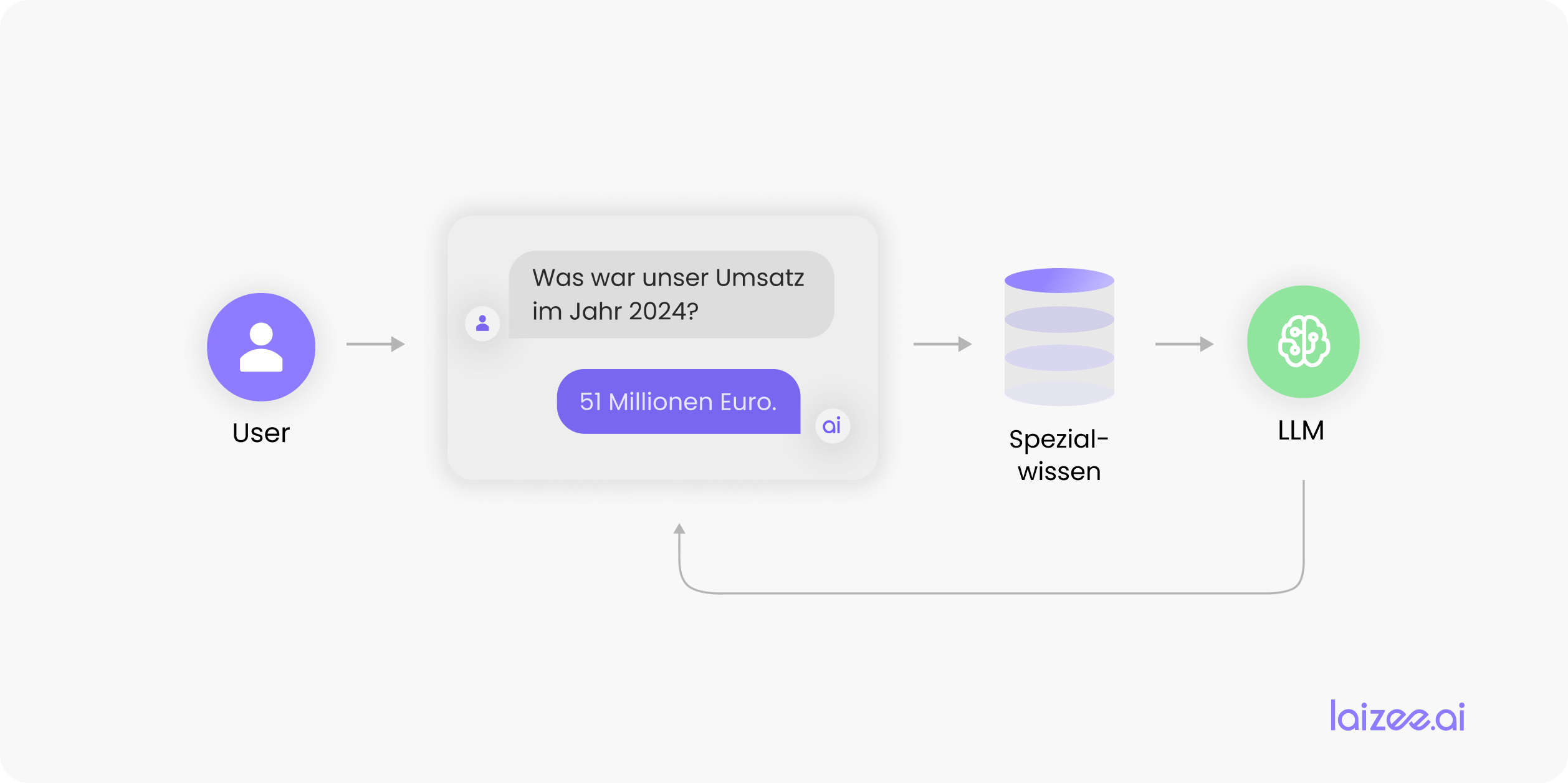
Come può un'azienda, pur operando in determinati settori, sfruttare comunque i punti di forza dei modelli di linguaggio generico (LLM) e integrare le loro conoscenze con le informazioni interne all'azienda? Una possibilità per integrare in modo rapido ed economico le conoscenze mancanti nel proprio sistema o modello è rappresentata dalla tecnologia RAG.
Che cos'è RAG e come funziona?
RAG sta per Generazione potenziata dal recupero. In italiano si potrebbe tradurre come «generazione ampliata tramite query». RAG è un processo volto all’ottimizzazione e alla specializzazione dei risultati dei modelli di linguaggio di grandi dimensioni (LLM). In sostanza, si tratta di ampliare le conoscenze apprese implicitamente da un LLM con informazioni specifiche per l'applicazione. L'LLM è quindi in grado di rispondere correttamente alle richieste specifiche di un utente sulla base di queste conoscenze ampliate.
Nella sua forma più semplice, il processo RAG si basa su tre elementi:
- Un database vettoriale in cui vengono memorizzati blocchi di informazioni specifici per l'applicazione.
- Un sistema di recupero che effettua ricerche nel database vettoriale alla ricerca di informazioni pertinenti alla richiesta.
- L'LLM, che genera risposte intuitive sulla base delle informazioni trovate.
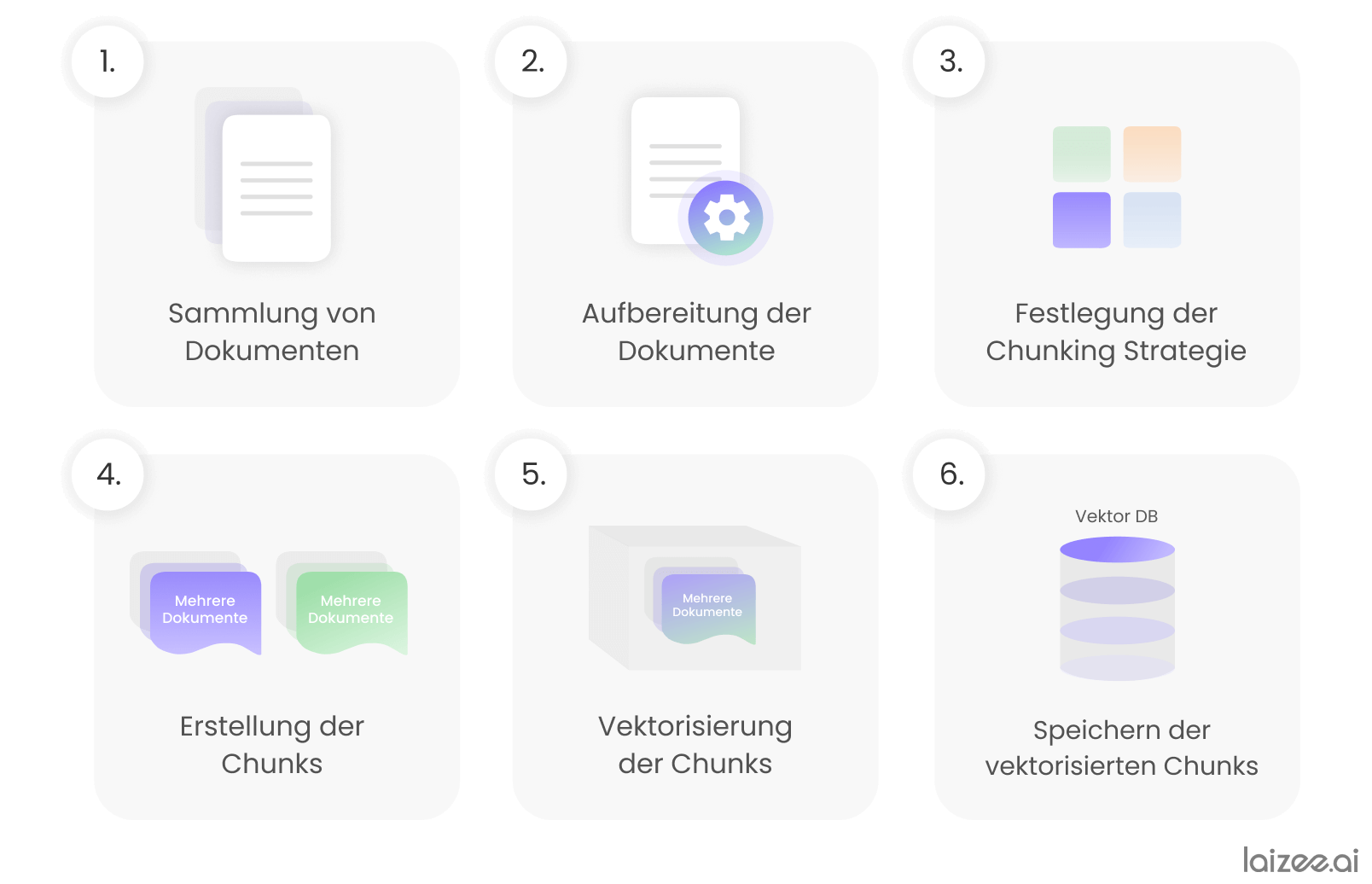
La spina dorsale di un sistema RAG è costituita dal database vettoriale, nel quale sono memorizzate le informazioni necessarie per rispondere alle richieste specifiche dell'applicazione. Per realizzarlo, vengono essenzialmente eseguiti i seguenti sei passaggi:
- Raccolta di documenti (ad es. documenti PDF) contenenti informazioni e dati specifici per l'applicazione.
- Elaborazione dei documenti, ad esempio la conversione di documenti PDF in testo leggibile da computer.
- Definizione di una cosiddetta strategia di chunking, grazie alla quale i documenti vengono suddivisi in blocchi di informazioni.
- Generazione dei blocchi di informazioni («chunk») sulla base della strategia precedentemente definita.
- Trasformazione dei chunk in sequenze numeriche (vettori). Questa fase è nota anche come embedding.
- Salvataggio dei chunk trasferiti nel database vettoriale.
Come funziona il sistema di recupero?
Le parole vengono convertite in vettori numerici. Ogni singola parola viene quindi rappresentata come una sequenza di numeri. L'aspetto interessante dei vettori è che consentono di calcolare le somiglianze semantiche e le relazioni tra le parole. Poiché i vettori possono essere confrontati molto rapidamente, un sistema di recupero permette di individuare documenti simili dal punto di vista dei contenuti.
Processo RAG
L'utente invia una richiesta al sistema. Tale richiesta viene convertita in un vettore utilizzando la stessa procedura descritta al punto 5.
Sulla base del vettore della richiesta, vengono cercate le informazioni pertinenti nel database vettoriale.
Questi dati vengono quindi recuperati (retrieved) e valutati in base a diversi fattori, classificati e infine i risultati migliori vengono consolidati. Questi dati e documenti costituiscono il Contesto con cui viene arricchita la richiesta dell'utente.
La richiesta, insieme al contesto precedentemente identificato, viene quindi trasmessa al modello di linguaggio di grandi dimensioni (LLM). Quest'ultimo, avvalendosi delle informazioni aggiuntive, genera una risposta adeguata e la restituisce infine all'utente.
Panoramica dell'architettura e dei processi RAG
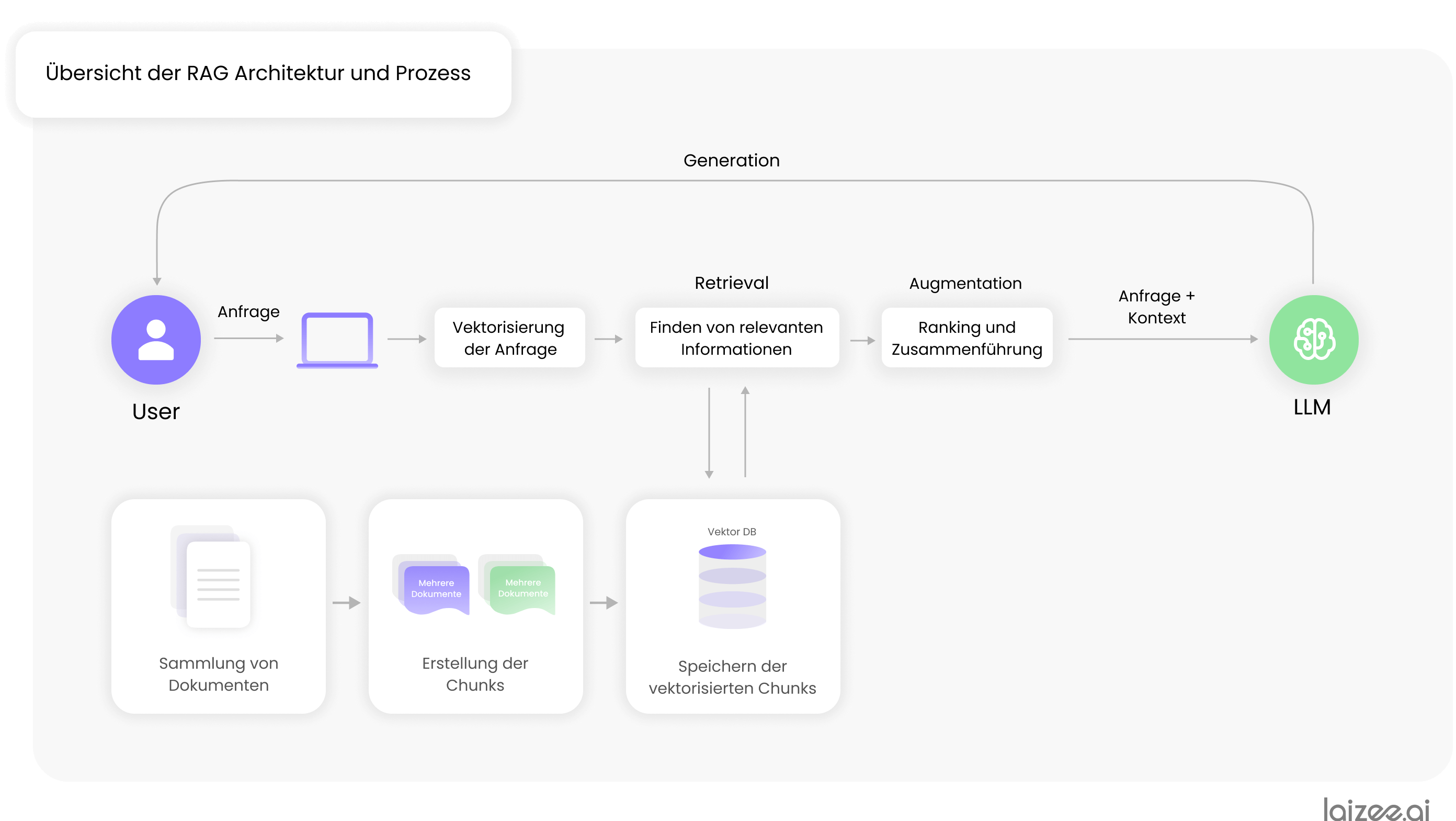
RAG contro messa a punto
Un altro modo per arricchire un modello LLM con informazioni specifiche per un'applicazione è quello del cosiddetto Messa a punto. A tal fine, si prende un LLM già pre-addestrato e lo si addestra ulteriormente sulla base di informazioni specifiche dell'applicazione. Nel corso di questo addestramento successivo, i parametri del modello esistenti vengono ottimizzati. Grazie alla messa a punto dei parametri del modello, il modello addestrato successivamente è in grado, a differenza del modello originale, di risolvere anche compiti specifici dell'applicazione. La messa a punto degli LLM esistenti è di norma molto più costosa e dispendiosa in termini di tempo rispetto all'approccio RAG.
Vantaggi dell'approccio di messa a punto
- Il modello ottimizzato può essere utilizzato per tutte le attività relative ai modelli di linguaggio di grandi dimensioni (LLM) (ad esempio, analisi del sentiment, riconoscimento delle entità) e non solo per i sistemi di domande e risposte, ovvero le attività di Q&A
- Costi una tantum (a meno che non sia necessario aggiornare regolarmente le informazioni)
- Nessun costo aggiuntivo a lungo termine per le infrastrutture
Sfide nell'approccio di messa a punto
- In linea di principio, ciò non è possibile con fornitori di modelli di terze parti a codice chiuso come OpenAI
- Il processo di formazione tende ad essere costoso e dispendioso in termini di tempo
- non è funzionale quando occorre tenere conto di dati in tempo reale o dinamici
- Le allucinazioni continuano a rappresentare un problema
- La fonte delle risposte non è rintracciabile/non è identificabile
Vantaggi del processo RAG
- Un modo rapido per arricchire i modelli di linguaggio di grandi dimensioni (LLM) con conoscenze interne e specifiche del settore
- Configurazione iniziale conveniente
- Supporta l'integrazione dinamica dei dati in tempo reale
- Consente di indicare le fonti e di garantirne la tracciabilità
- Non richiede dati etichettati
- Gestione degli accessi alle fonti
Sfide del processo RAG
- Il processo di «ricerca e recupero» ha un forte impatto sulla qualità dei risultati
- RAG è rilevante soprattutto per i sistemi di domande e risposte
- La creazione e la gestione a lungo termine della banca dati vettoriale comportano costi ricorrenti
- Il numero di token di input trasmessi al modello di linguaggio di grandi dimensioni (LLM) aumenta grazie al contesto
Casi d'uso
RAG offre prestazioni eccezionali soprattutto nelle attività di domande e risposte (Q&A) e nell'estrazione di informazioni, ovvero in quei compiti in cui ci aspettiamo che il sistema di IA fornisca una risposta chiara a una domanda. La risposta può inoltre essere corredata dai riferimenti alle fonti che il modello di linguaggio (LLM) ha utilizzato per elaborarla. Ciò consente all'utente di verificare le informazioni o di reperire ulteriori dettagli.
Esempi concreti in ambito aziendale sono l'integrazione di un chatbot nell'intranet aziendale o in una banca dati di conoscenze, con cui i dipendenti possono interagire facilmente e porre domande. Il chatbot RAG consente ai collaboratori di accedere rapidamente alle conoscenze interne all'azienda. Inoltre, il chatbot elabora le informazioni trovate e le presenta in forma sintetica. Ciò consente un utilizzo efficiente delle conoscenze aziendali, aumenta la qualità del lavoro dei collaboratori e può contribuire ad assicurare un vantaggio competitivo a lungo termine.
Esempi di casi d'uso e applicazioni di prodotto per un chatbot RAG sono:
- Inserimento dei nuovi dipendenti
- Utilizzo quotidiano e acquisizione di informazioni aziendali
- I chatbot come ulteriore canale di accesso ai contenuti didattici digitali
… oppure potete crearvi un alter ego digitale alla Tom Riddle con le pagine del vostro diario.