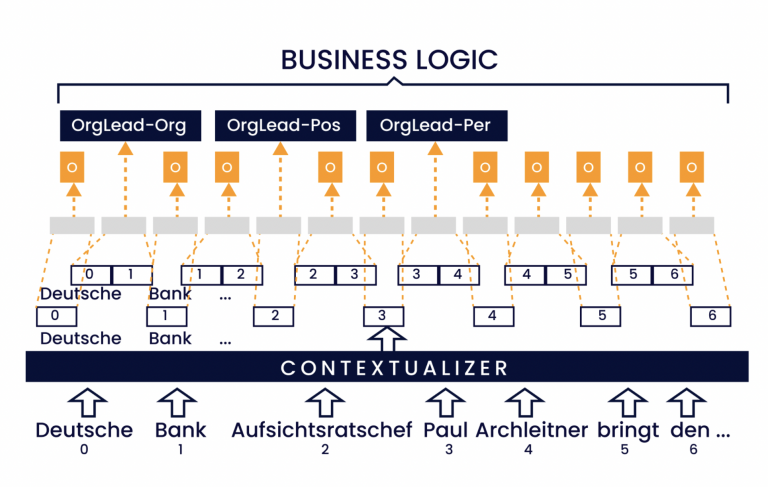
Pochi settori dell'informatica sono attualmente così popolari come l'apprendimento automatico (ML) e, in particolare, l'elaborazione del linguaggio naturale (NLP). Chi non conosce il funzionamento dello smartphone o della radio tramite assistente vocale (Siri, Alexa ecc.)? Quanto è comodo pronunciare semplicemente l’indirizzo verso cui si desidera essere guidati? È persino possibile il riconoscimento automatico delle richieste dei clienti durante l’elaborazione automatizzata della corrispondenza.
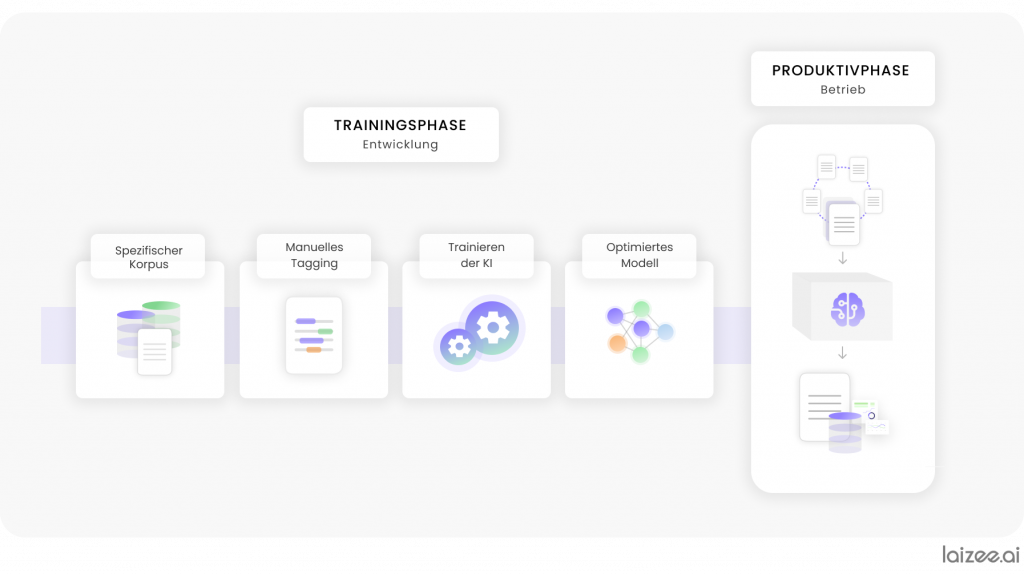
Nonostante l'esistenza di strumenti di supporto e di modelli di processo e procedure consolidati, come ad esempio STAMP4NLP [1], la creazione di un'applicazione di questo tipo comporta ancora un notevole dispendio di risorse. Per poter addestrare i modelli statistici necessari, in grado di individuare modelli all'interno dei dati ai fini dell'estrazione di informazioni, è necessario innanzitutto identificare e preparare dati adeguati. Ciò include sia la correzione degli errori ortografici, sia il tagging manuale, ovvero l'evidenziazione di elementi nel testo. Sulla base del corpus annotato, il modello viene addestrato nella fase di training e, una volta completata l'ottimizzazione, integrato in un sistema di IA che può essere utilizzato in modo produttivo (vedi Figura 1).
Un aspetto che sta assumendo sempre maggiore rilevanza nella creazione di sistemi di intelligenza artificiale è la protezione dei dati [2]. A causa dell'elevata complessità nella creazione di applicazioni NLP, molte aziende dipendono dall'aiuto di società e sviluppatori esterni. Tuttavia, ciò comporta la necessità di fornire dati che contengono anche informazioni sensibili dal punto di vista della protezione dei dati, sulla base dei quali vengono addestrate le nuove applicazioni. Questo è il punto in cui, finora, la maggior parte di queste aziende ha rinunciato all'introduzione dell'NLP nella propria attività, poiché l'anonimizzazione dei dati comporta un notevole dispendio di risorse.
In particolare, grazie al Regolamento generale sulla protezione dei dati (GDPR) dell'UE, il tema dell'anonimizzazione dei dati nel rispetto della normativa sulla privacy ha acquisito nuovo slancio [3]. A causa delle pesanti sanzioni previste in caso di violazione, la protezione dei dati rappresenta attualmente un ostacolo particolarmente rilevante all'introduzione della NLP.
Le procedure esistenti, che sostituiscono in modo relativamente semplice le informazioni sensibili dal punto di vista della protezione dei dati con dati fittizi, non sono immediatamente applicabili. Ciò è dovuto, da un lato, al rispettivo ambito di applicazione. Nel contesto assicurativo, ad esempio, i codici delle polizze, i nomi, i dati relativi agli eventi e gli indirizzi sono sicuramente da considerarsi informazioni sensibili. Nel contesto dei dati medici, invece, occorre prestare particolare attenzione ad attributi quali altezza, peso, sintomi e diagnosi. Di conseguenza, per ogni ambito è necessario innanzitutto identificare gli attributi critici.
Occorre inoltre tenere presente che le informazioni devono essere rese anonime in misura sufficiente. Se, sulla base delle informazioni rimanenti e integrandole con un’ulteriore fonte di dati, è ancora possibile risalire ai dati originali, non si ha un’anonimizzazione che impedisca qualsiasi risalita. Un esempio è la rimozione del nome e dell'indirizzo, ma il contemporaneo mantenimento della data di nascita e del sesso in una cartella clinica. Se ora si aggiunge il registro anagrafico e lo si limita al bacino di utenza dell'ospedale, è possibile identificare la persona interessata con uno sforzo minimo [4].
D'altra parte, occorre inoltre tenere conto della scelta dei metodi disponibili. A titolo esemplificativo, esistono varianti che sostituiscono i nomi in modo casuale con i 100 nomi più frequenti in Germania. È tuttavia ipotizzabile anche una sostituzione schematica 1:1, oppure sono possibili procedure più complesse. In questo contesto, non va trascurato l'impatto dell'anonimizzazione sul modello da addestrare. Se durante il funzionamento produttivo dell'applicazione NLP compare un documento con un nome che non rientra tra i 100 più frequenti, in alcune circostanze questo potrebbe non essere riconosciuto. Di conseguenza, occorre tenere conto del mantenimento della varianza dei dati all'interno degli attributi anonimizzati.
A ciò si aggiunge il fatto che, nel processo di anonimizzazione, è importante anche preservare le relazioni tra i dati. In caso contrario, non sarebbe possibile riconoscere, tra le diverse righe, che si fa riferimento alla stessa persona o che i processi descritti sono collegati tra loro. Nel complesso, i metodi utilizzati finora limitano eccessivamente l'addestramento dei modelli su dati anonimizzati a causa della perdita di informazioni.
L'obiettivo è quello di trovare un equilibrio tra il rispetto delle norme sulla protezione dei dati e lo sviluppo di un'applicazione di alta qualità. Il seguente schema illustrativo mostra un possibile percorso per rendere fattibile l'introduzione del NLP attraverso l'anonimizzazione.
Schema procedurale
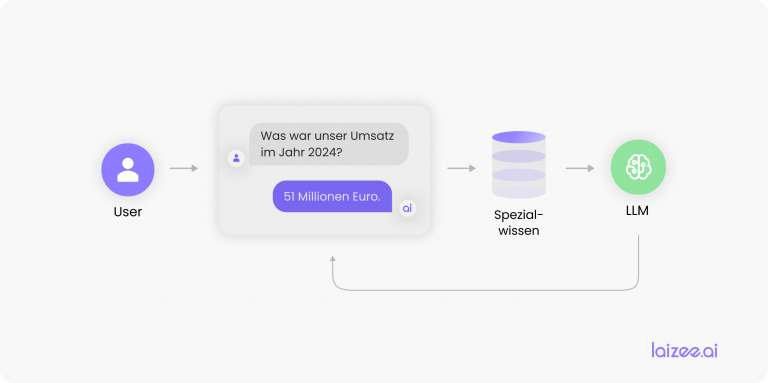
Prendiamo ad esempio un'azienda che comunica con i propri clienti tramite un modulo di contatto. Per evitare di dover elaborare manualmente ogni singolo messaggio, è opportuno che questi vengano gestiti in modo il più possibile automatico.
Lo sviluppo di un'applicazione NLP adeguata è affidato a un fornitore di servizi NLP esterno, il quale richiede i messaggi dei clienti ricevuti dall'azienda a tale scopo. Tuttavia, poiché tali messaggi contengono dati personali soggetti alla normativa sulla protezione dei dati, l'azienda non è autorizzata a divulgarli.
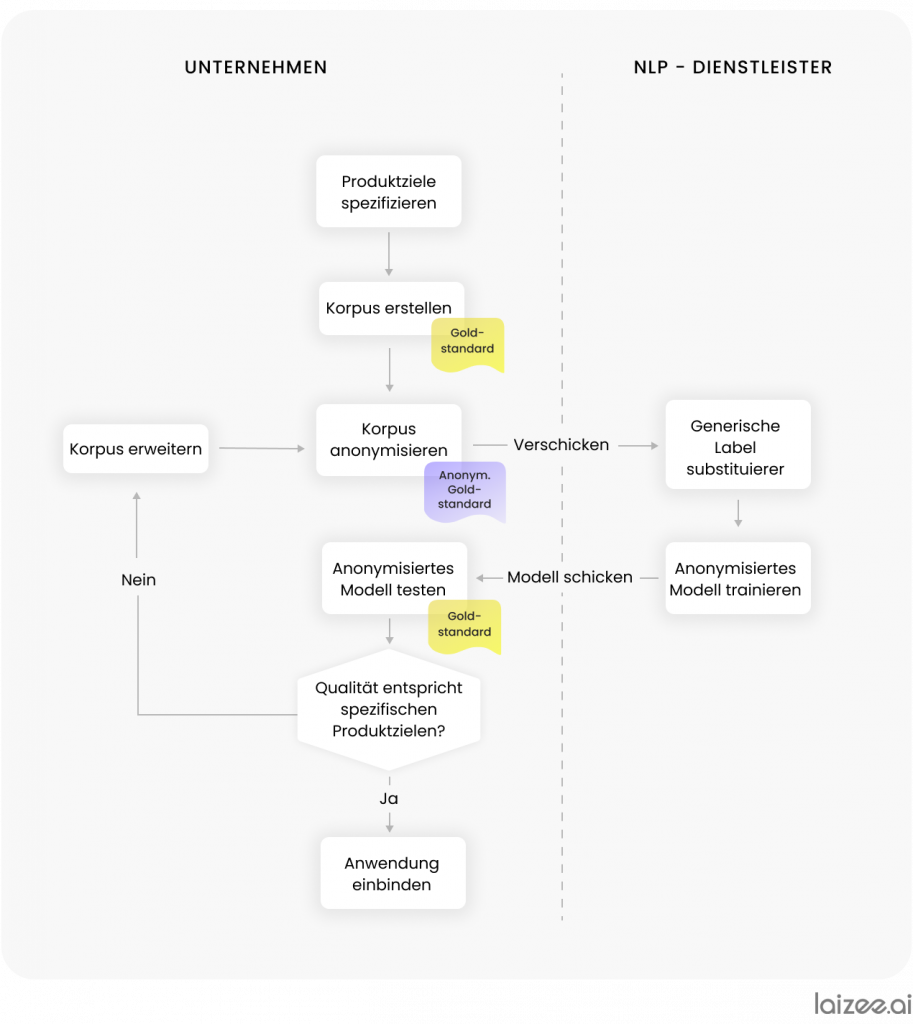
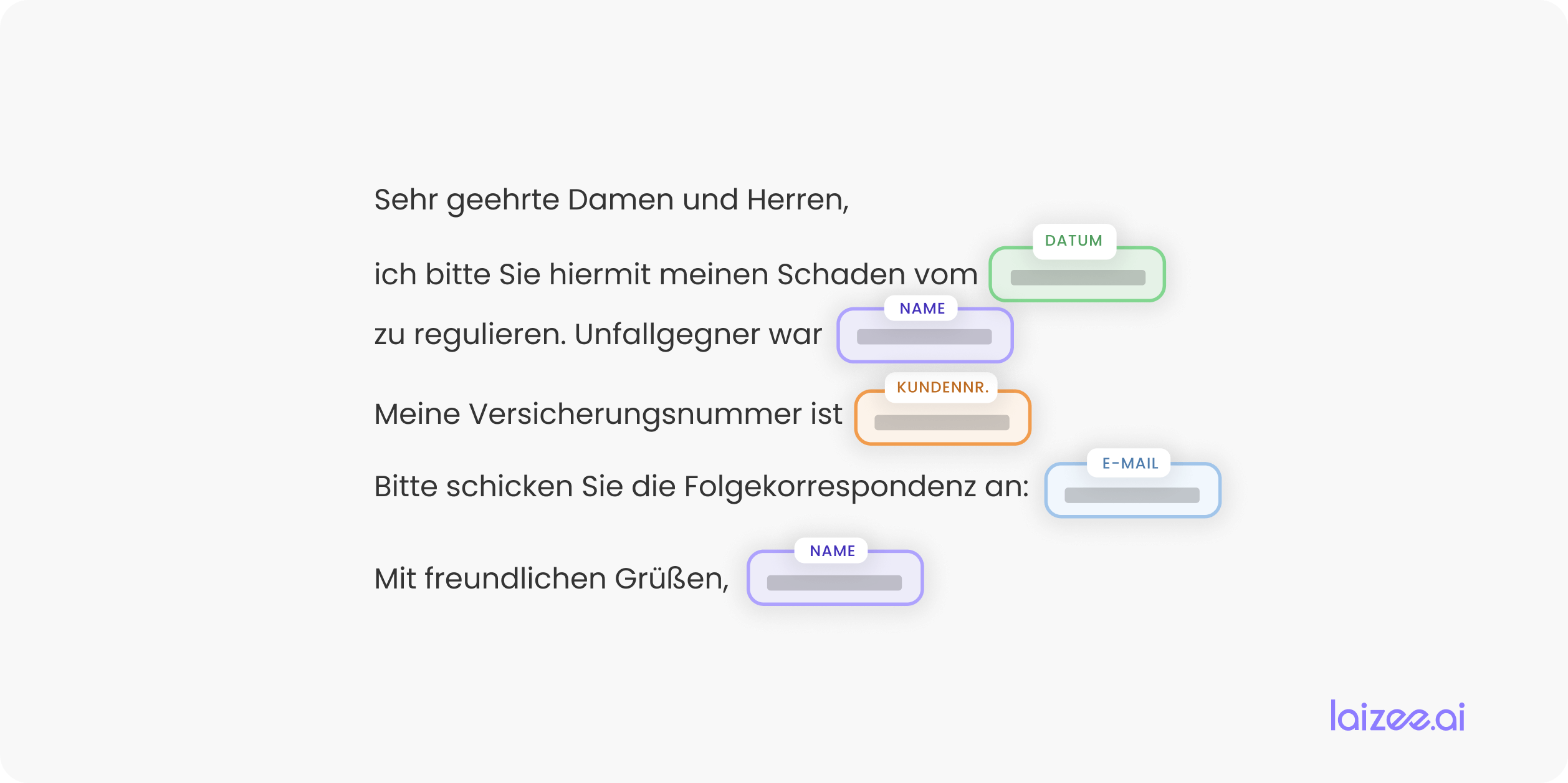
In linea con Figura 2 Si procede quindi nel modo seguente: innanzitutto l'azienda crea un corpus e lo annota. Questo viene salvato come "gold standard". Successivamente, il corpus deve essere reso anonimo. Una soluzione comune consiste nel far contrassegnare ai dipendenti dell'azienda i passaggi critici all'interno dei messaggi e sostituirli con le etichette corrispondenti.

A tal fine, occorre innanzitutto identificare tutte le categorie di informazioni critiche specifiche del settore. Nel caso in questione, ci riferiamo al settore assicurativo. Di conseguenza, devono essere sostituiti nome, data, numero cliente e indirizzo e-mail, nonché eventuali altri attributi (vedi Figura 3).
Una volta completata l'anonimizzazione, il set di dati contenente gli indirizzi e-mail resi anonimi viene inviato al fornitore di servizi NLP. Quest'ultimo sostituisce le etichette con dati fittizi, generando così un set di dati conforme alle norme sulla protezione dei dati, che può essere riutilizzato e costituisce uno standard di riferimento anonimo. Il fornitore di servizi addestra quindi un modello statistico per l'estrazione di informazioni e sviluppa un servizio di IA NLP adeguato.
Il servizio e il modello vengono successivamente consegnati all'azienda committente, dove vengono verificati in termini di qualità di elaborazione delle e-mail. A tal fine viene utilizzato lo standard di riferimento salvato all'inizio. Con l'ausilio di diverse metriche, la precisione di estrazione dell'applicazione viene misurata rispetto agli obiettivi di prodotto specificati in precedenza. Se la qualità non dovesse essere sufficiente, si valuta se sia necessario adeguare la procedura di anonimizzazione o ampliare il corpus, e l'applicazione viene rielaborata.
Se la qualità di elaborazione soddisfa tutti i criteri per l'utilizzo operativo, l'applicazione viene integrata nei processi esistenti. È opportuno verificare a intervalli regolari se l'elaborazione continua a funzionare senza problemi o se è necessario un adeguamento.
Un'alternativa al ricorso a fornitori di servizi?
In alternativa al ricorso a fornitori di servizi esterni, si possono prendere in considerazione moderne piattaforme low-code ospitate «on premise». In questo contesto, «low-code» significa che anche chi non è esperto può sviluppare modelli di NLP altamente performanti. Soluzioni basate su piattaforme aperte, come quella della startup TaggingMatters dell’Università di Scienze Applicate di Aquisgrana (https://taggingmatters.de/), garantiscono la protezione dei dati e, al contempo, nascondono la complessità dei framework utilizzati. In questo modo, i dipendenti delle aziende non devono diventare esperti dei complessi strumenti di NLP o ML, come spaCy o TensorFlow, né della matematica alla base dei moderni algoritmi, ma possono concentrarsi sulle attività che generano valore aggiunto.
Queste piattaforme consentono, oltre alla preparazione dei dati (“tagging”), la creazione ottimizzata di modelli di IA e la fornitura di servizi di IA. In questo modo, le iterazioni sopra descritte possono essere completate molto più rapidamente, anche senza esperienza nel campo del NLP. In definitiva, l’azienda beneficia di costi di sviluppo inferiori e di un ritorno sull’investimento più rapido, poiché non bisogna perdere di vista l’obiettivo reale: il miglioramento dei processi aziendali.
Sintesi
L'esistenza e l'inasprimento delle norme sulla protezione dei dati rendono più difficile l'adozione dell'NLP in numerose aziende operanti nei settori più disparati. L'anonimizzazione prima della consegna dei dati a società di software esterne o l'utilizzo di una piattaforma low-code possono rappresentare una soluzione. Un punto critico è la qualità ottenibile dei modelli addestrati su dati anonimizzati e la sua misurazione da parte dell'azienda committente. In questo contesto è indispensabile un processo di ottimizzazione iterativo per la creazione e l'ottimizzazione dei modelli con feedback multiplo.
Guardando al futuro, l'elaborazione automatizzata assumerà un'importanza sempre maggiore nel contesto digitale. Soprattutto alla luce della legge sull'accessibilità online (OZG), un numero crescente di aziende sarà interessato a ottimizzare i propri processi. A tal fine sarà sempre più necessario ricorrere a un supporto esterno, che potrà essere realizzato seguendo lo schema procedurale qui illustrato o utilizzando piattaforme low-code.
Autori
Prof. Dr. rer. nat. Bodo Kraft
Il Prof. Dr. Bodo Kraft è fondatore e direttore del laboratorio Business Programming. Da oltre dieci anni, insieme a cinque dottorandi, conduce ricerche orientate alle applicazioni nel campo della linguistica computazionale. Il filo conduttore dei vari progetti è la sfida di elaborare in modo efficiente e automatizzato grandi quantità di documenti in lingua naturale.
In questo contesto, è fondamentale che le soluzioni vengano adattate con successo al rispettivo ambito di applicazione. Un altro punto chiave è costituito da un approccio agile e orientato alla qualità per la realizzazione di sistemi software utilizzabili a livello operativo e di facile manutenzione.
Prof. Dr. Matthias Meinecke
Il Prof. Dr. Matthias Meinecke (docente di Gestione delle operazioni e membro del consiglio direttivo dell’Istituto per la digitalizzazione di Aquisgrana, Università di Scienze Applicate di Aquisgrana) si occupa di insegnamento, ricerca e consulenza in materia di ottimizzazione e automazione dei processi aziendali.
Insieme al Prof. Dr. Kraft, è coach della start-up laizee.ai, che sviluppa prodotti e servizi per l'elaborazione efficiente e automatizzata del linguaggio umano finalizzata all'ottimizzazione dei processi aziendali.
M. Sc. Ines Larissa Siebigteroth
La dott.ssa Ines Larissa Siebigteroth ha studiato tecnomatematica presso l'Università di Scienze Applicate di Aquisgrana e l'Università del Wisconsin-Milwaukee e sta attualmente svolgendo il dottorato di ricerca sotto la supervisione del Prof. Dr. Bodo Kraft. La dott.ssa Siebigteroth fa parte del Laboratorio di Programmazione Aziendale. Il suo lavoro si concentra sull'elaborazione del linguaggio naturale (NLP) e, in particolare, sulla creazione di corpora di alta qualità, nel rispetto della normativa sulla protezione dei dati, destinati all'elaborazione automatizzata del linguaggio naturale.
Riferimenti
| [1] | P. Kohl, O. Schmidts, L. Klöser, H. Werth, B. Kraft e A. Zündorf, «STAMP 4 NLP – Un framework agile per lo sviluppo rapido di applicazioni NLP orientate alla qualità», [Online]. Disponibile all'indirizzo: https://link.springer.com/chapter/10.1007%2F978-3-030-85347-1_12. |
| [2] | Commissione per l'etica dei dati, «Raccomandazioni della Commissione per l'etica dei dati relative alla strategia del governo federale in materia di intelligenza artificiale», [online]. Disponibile all'indirizzo: https://www.bmjv.de/SharedDocs/Downloads/DE/Ministerium/ForschungUndWissenschaft/DEK_Empfehlungen.pdf?__blob=publicationFile&v=2. |
| [3] | S. C. A. Probst Eide, «Lo stato attuale dello sviluppo degli strumenti per l'anonimizzazione dei dati», [online]. Disponibile all'indirizzo: https://www.it-finanzmagazin.de/entwicklungsstand-daten-anonymisierung-73373/. |
| [4] | D. Barth-Jones, «La “re-identificazione” delle informazioni mediche del governatore William Weld: una rivisitazione critica dei rischi legati all’identificazione dei dati sanitari e delle misure di tutela della privacy, ieri e oggi», [online]. Disponibile all’indirizzo: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2076397. [Consultato il 15 dicembre 2021]. |