1. Introduzione
Le piccole e medie imprese (PMI) riconoscono sempre più il potenziale della comprensione del linguaggio naturale e dell'estrazione di relazioni per digitalizzare i processi e sviluppare nuovi prodotti software. Molte visioni di prodotto prevedono l'estrazione di insiemi di menzioni concettuali di dimensioni variabili come relazioni da testi in cui i modelli di dati esistenti definiscono una serie di potenziali attributi per ciascuna relazione. Tuttavia, la maggior parte degli approcci attuali si concentra sull'estrazione di relazioni binarie. Ad esempio, il numero di molte migliaia di pubblicazioni scientifiche biomediche a settimana ha portato al successo dell'automazione della scoperta di conoscenze (Tsujii et al., 2011; Kim et al., 2011a; Kim et al., 2011b). A differenza di molti altri ambiti, il vincolo strutturale della binarietà sembra essere ragionevole a causa delle relazioni di causa-effetto. L’estrazione di relazioni semantiche più complesse richiede attualmente la costruzione di sistemi sofisticati basati su classificazioni binarie. Il campo dell’estrazione di eventi copre tali approcci. Gli eventi sono relazioni multi-attributo con le cosiddette annotazioni trigger. Ad esempio, nel seguente messaggio relativo a un ostacolo al traffico: A1 tra Köln-Mühlheim e Köln-Dellbrück oggetti sulla strada, entrambe le direzioni chiuse. Secondo (Consortium, 2005) "chiusa" innesca l'evento ma non fornisce informazioni specifiche sull'evento. Gli attributi assegnati a tali trigger costruiscono le relazioni dell'evento. Il ruolo centrale dell'annotazione del trigger comporta requisiti di alta qualità e un maggiore sforzo di annotazione.
La presente ricerca introduce l'estrazione di relazioni multi-attributo (MARE), una nuova definizione del problema che mira a semplificare l'applicazione degli approcci di estrazione delle relazioni nella pratica. Relazioni multi-attributo:
- disporre di una serie ben definita di possibili ruoli per gli attributi,
- non dare nulla per scontato riguardo alla molteplicità degli attributi quando si crea un'istanza di relazione, e
- non basarti sul concetto di "trigger", che indica la presenza di una relazione.
Presentiamo un approccio basato sul tagging di sequenze e sull’etichettatura di span per il riconoscimento di entità e l’estrazione di relazioni multi-attributo tra di esse in un modello congiunto. Analizziamo le prestazioni dei nostri approcci sul corpus Smart-Data (Schiersch et al., 2018). Questo corpus è l’unica risorsa disponibile per l’estrazione di relazioni su testi in lingua tedesca. Le annotazioni di questo corpus includono entità denominate e relazioni multi-attributo tra di esse. Pubblichiamo tutti i dati e il codice sorgente relativi alla ricerca in un repository GitHub¹. I nostri principali contributi possono essere riassunti come segue:
- Formaliamo l'estrazione di relazioni multi-attributo e introduciamo due approcci specifici per il problema.
- Dimostriamo che gli approcci non basati su trigger ottengono in generale risultati migliori sulle relazioni multi-attributo presenti nel corpus SmartData.
- Presentiamo la prima valutazione riproducibile di un approccio non binario all'estrazione di relazioni su un corpus in lingua tedesca.
¹https://github.com/MSLars/mare
2. Lavori correlati
L'estrazione delle relazioni analizza le relazioni reciproche tra le entità denominate presenti nei testi al fine di trasferire le informazioni non strutturate in schemi predefiniti. La maggior parte dei set di dati di riferimento prende in considerazione solo le relazioni binarie (Mintz et al., 2009; Hendrickx et al., 2010).
Gli approcci tradizionali all'estrazione delle relazioni binarie utilizzano la classificazione delle parti del discorso, l'analisi sintattica delle dipendenze e ulteriori passaggi per calcolare le rappresentazioni degli input per i modelli di apprendimento automatico (Xu et al., 2013). I modelli all'avanguardia attualmente disponibili utilizzano reti Transformer per calcolare rappresentazioni altamente contestualizzate delle relazioni binarie candidate e le combinano con livelli decisionali specializzati in una rete neurale combinata (Li e Tian, 2020; Eberts e Ulges, 2019).
Come estensione dell'estrazione delle relazioni binarie, il campo dell'estrazione delle relazioni n-arie mira a individuare relazioni con un numero fisso di n argomenti. (Peng et al., 2017) hanno esteso le reti neurali ricorrenti per includere in modo efficiente i legami di dipendenza sintattica, al fine di costruire rappresentazioni contestualizzate delle relazioni. (Lai e Lu, 2021) hanno presentato un approccio basato sui Transformer per lo stesso contesto sperimentale. Entrambi si concentrano sulle relazioni triari.
Gli approcci all'estrazione di relazioni binarie e a n-ari spesso elencano insiemi di entità previste come base per la creazione di relazioni candidate. Noi estraiamo relazioni con un numero arbitrario di attributi evitando tale enumerazione, al fine di prevenire un'esplosione combinatoria.
Per estendere il vincolo della dimensione fissa, il campo dell’estrazione degli eventi definisce gli eventi come relazioni multi-attributo con un unico attributo trigger necessario. Il trigger indica la presenza di un evento. Ad ogni singolo trigger possono essere assegnate altre entità per formare relazioni di evento (Consortium, 2005; Aguilar et al., 2014). Gli approcci di estrazione degli eventi si basano su queste annotazioni dei trigger (Xiang e Wang, 2019). Tutte le entità assegnate a un trigger formano una relazione multi-attributo. Ciò riduce il problema a una sequenza di classificazioni di relazioni binarie.
Tradizionalmente, i sistemi di estrazione delle relazioni nel mondo reale estraggono le entità e le loro relazioni attraverso una pipeline di elaborazione. Tali sistemi sono soggetti alla propagazione degli errori. Il campo dell’estrazione congiunta delle relazioni studia modelli che estraggono entità e relazioni all’interno di un unico modello. Un approccio comune per costruire un modello congiunto consiste nel condividere il livello di embedding tra più attività a valle. (Wadden et al., 2019) hanno introdotto un sistema che condivide gli embedding per estrarre entità denominate, costruire candidati di relazioni binarie e classificare la relazione tra questi. (Zheng et al., 2017; Liu et al., 2019) introducono schemi di etichettatura di sequenze per estrarre esplicitamente attributi e le loro relazioni in un unico passaggio di classificazione. I nostri modelli estraggono in modo simile strutture più complesse senza un'enumerazione di candidati di relazione. Ciò evita un'esplosione combinatoria per MARE. Applichiamo una nuova rete di trasformatori per ricevere embedding di testo contestualizzati (Devlin et al., 2019; Clark et al., 2020).
(Schiersch et al., 2018) hanno introdotto lo Smart-Data Corpus per l'estrazione di relazioni da testi in lingua tedesca. Le relazioni annotate contengono un numero variabile di argomenti obbligatori e facoltativi. La sezione 3 analizza il corpus in modo approfondito. L'articolo originale include i risultati del sistema di estrazione di relazioni DARE (Xu et al., 2013). La presente valutazione prende in considerazione solo i ruoli degli attributi obbligatori per ciascuna relazione. Prendiamo in considerazione anche gli attributi opzionali e analizziamo i risultati in un contesto problematico più sofisticato. (Roller et al., 2018) indaga l'estrazione di entità denominate e relazioni binarie da referti clinici in tedesco. Il loro corpus non è stato pubblicato.
3. Analisi dei dati
Addestriamo e valutiamo i nostri approcci sul corpus Smart-Data2 (Schiersch et al., 2018), un corpus in lingua tedesca fornito dal DFKI3. Il corpus contiene entità e relazioni relative al traffico e al settore industriale annotate manualmente, tratte da notizie, feed RSS e tweet.
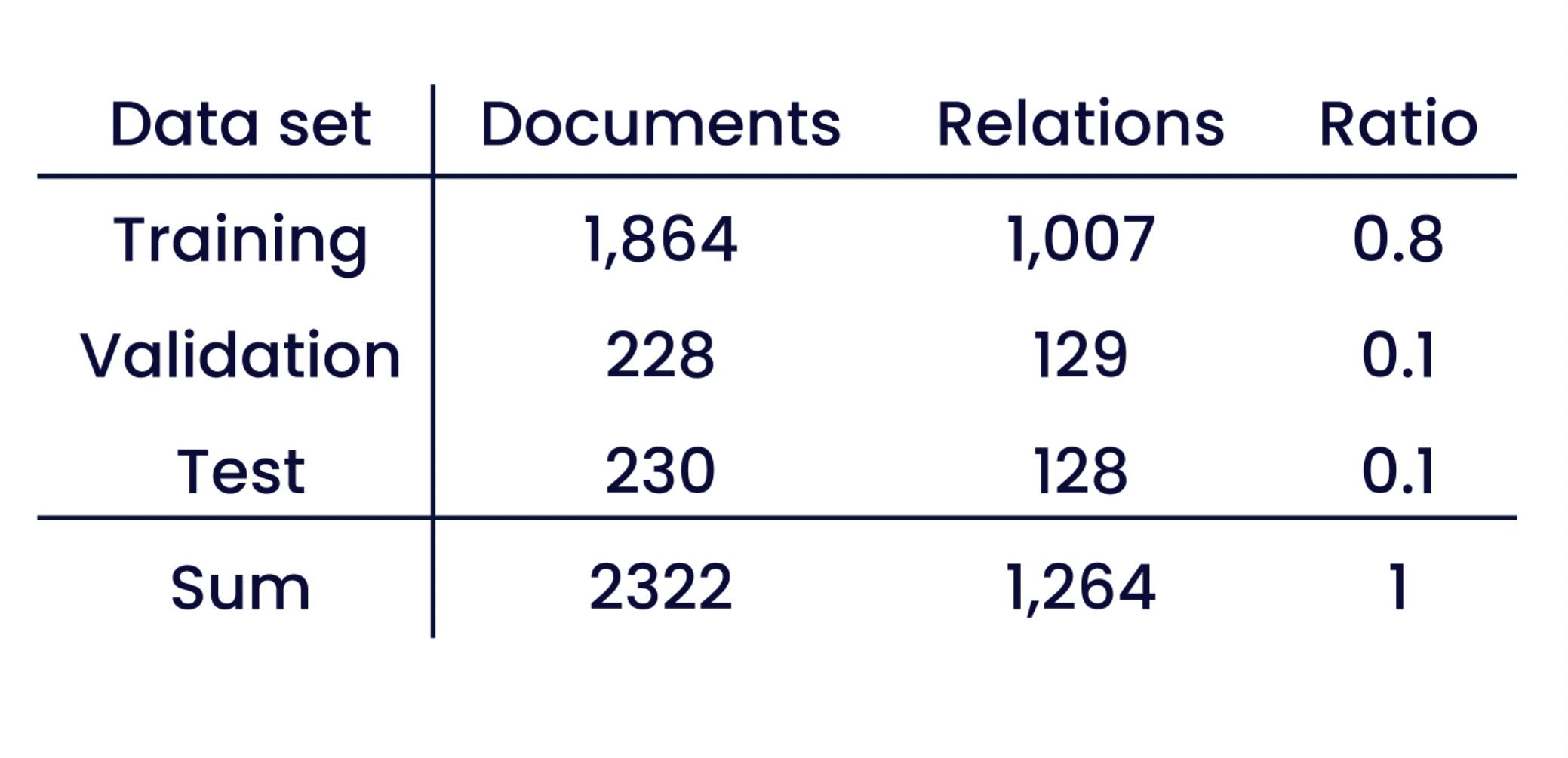
La terza versione del corpus contiene 19.116 entità e 1.264 relazioni distribuite su 2.322 documenti, per un totale di 141.344 parole⁴. La tabella 1 mostra la suddivisione tra set di addestramento e set di valutazione fornita da SmartData.
La concordanza tra gli annotatori è di livello moderato (Viera et al., 2005), con un coefficiente kappa di Cohen pari a 0,58 per le entità e a 0,51 per le relazioni.
Tabella 1: Suddivisione in set di addestramento e di valutazione del corpus SmartData, con il numero di relazioni e la percentuale di documenti in ciascun sottoinsieme.
Il DFKI descrive le proprie fasi di pre-elaborazione in (Schiersch et al., 2018) e su GitHub.
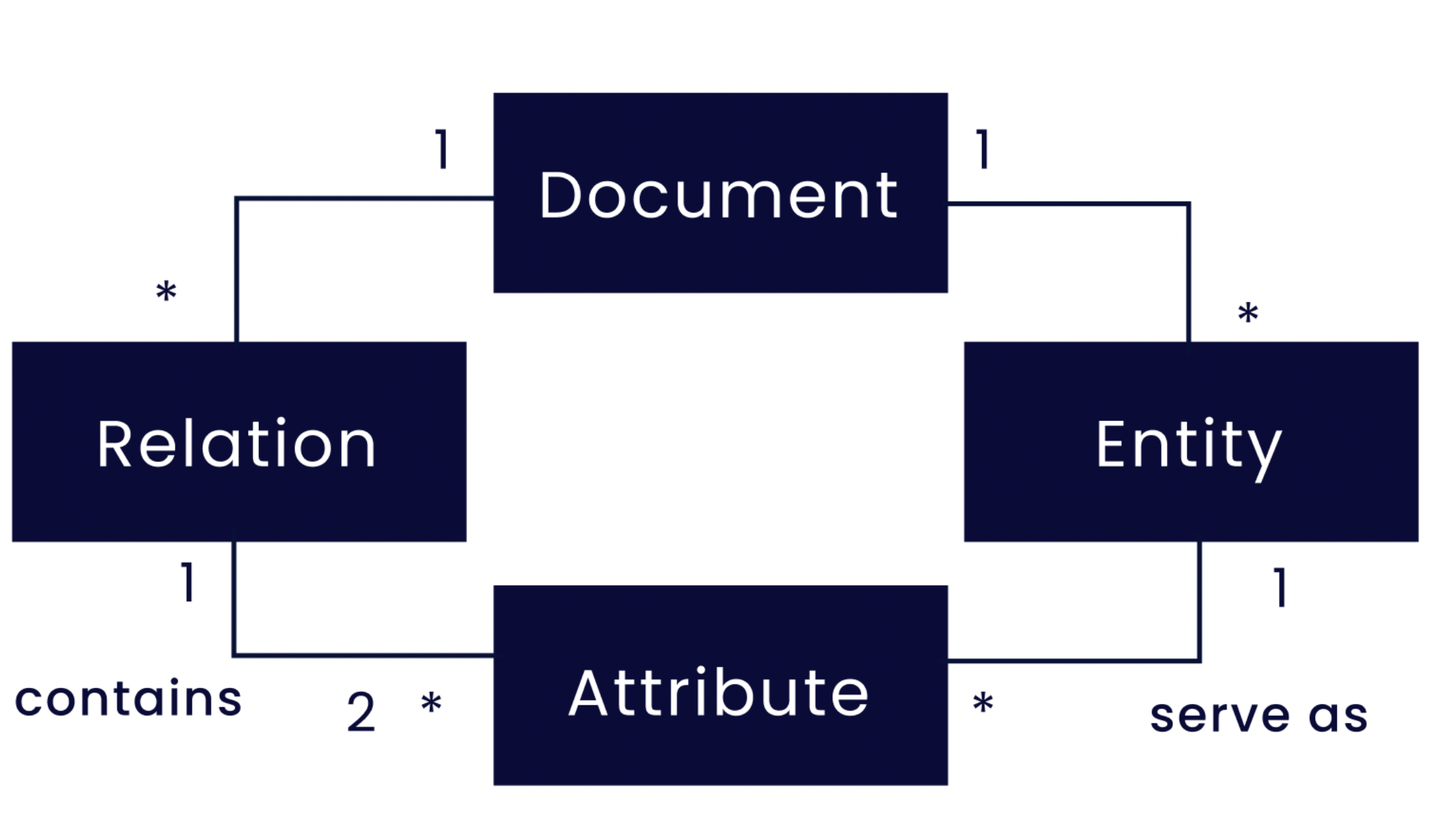
Figura 1: Struttura delle istanze nel corpus SmartData. I documenti contengono relazioni ed entità. Una relazione presenta almeno due attributi obbligatori. Ogni attributo contiene una menzione di entità. Le entità possono fungere da attributi in una o più relazioni. Ad esempio, l'entità "Location" può fungere da attributo contemporaneamente nelle relazioni "Accident" e "Obstruction".
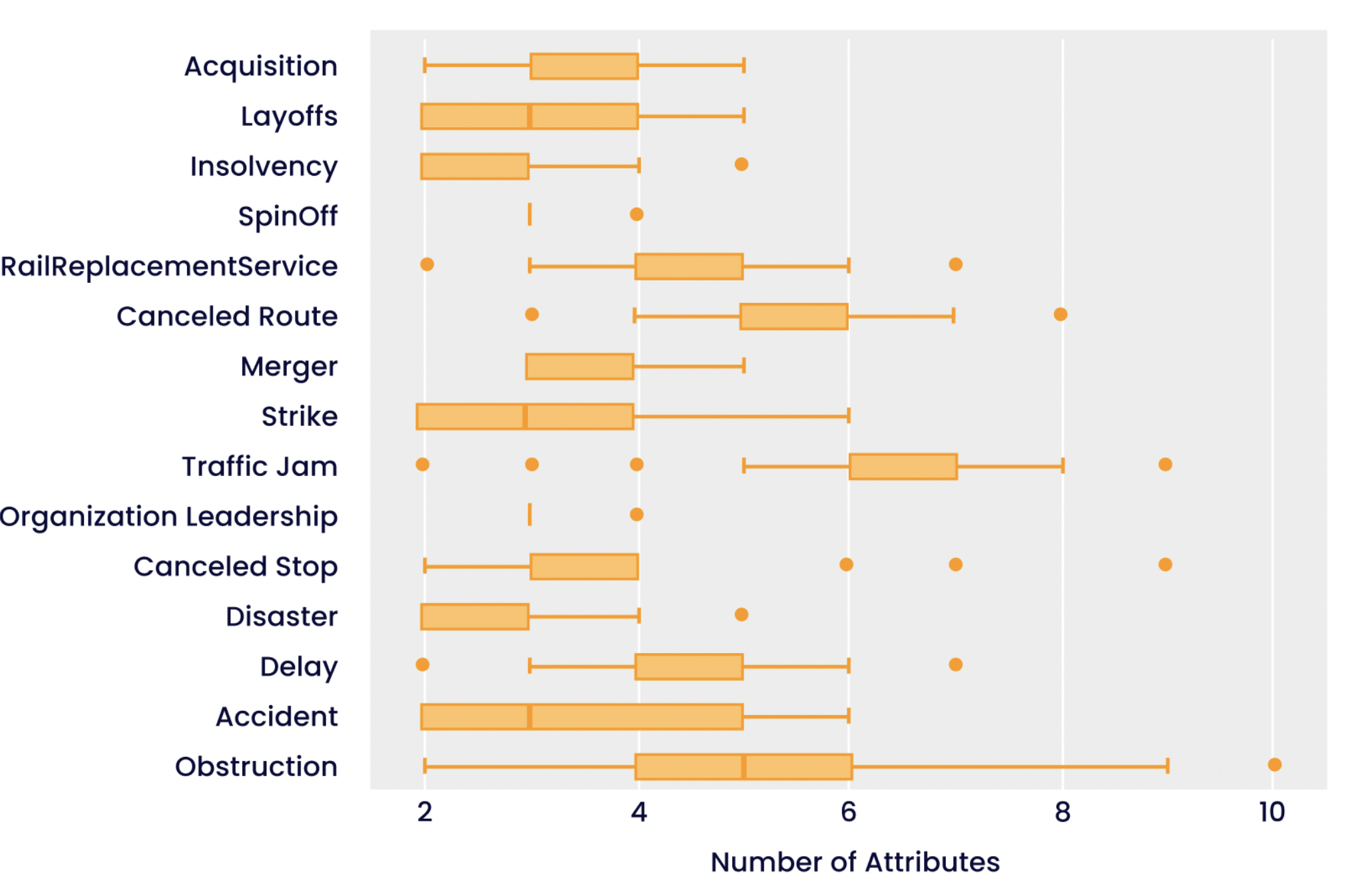
Figura 2: Boxplot che illustra la distribuzione del numero di attributi per relazione. Ad esempio, il numero di attributi della relazione "Ostruzione" varia da due a dieci, mentre altre relazioni, come "Insolvenza", non presentano la stessa varianza. I punti indicano i valori anomali.
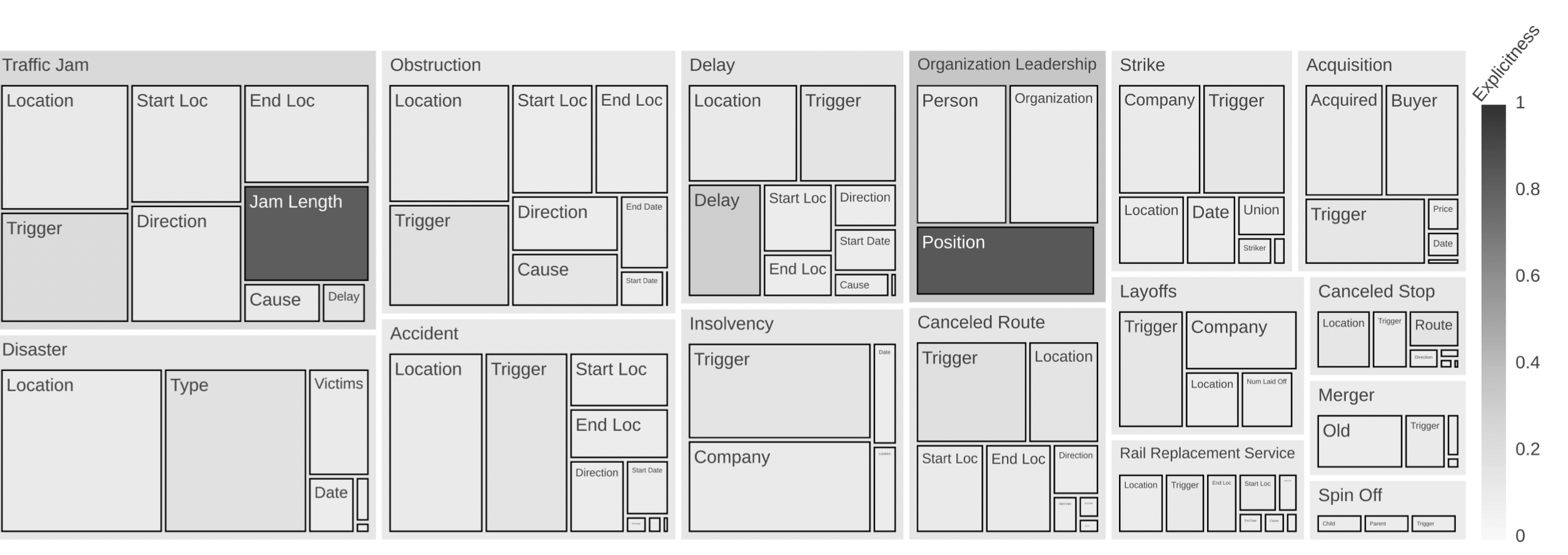
Figura 3: Distribuzione delle relazioni e degli attributi. Le dimensioni dei rettangoli sono proporzionali alla frequenza della relazione o dell'attributo. L'esplicitezza è il quoziente tra la frequenza degli attributi e il numero totale di entità con un tipo di entità adatto al ruolo specifico dell'attributo. Questa metrica indica con quanta affidabilità un tipo di entità indica un attributo di relazione.
La figura 1 illustra il metamodello dei dati. Si noti che una relazione può avere un numero variabile di attributi e non è limitata a un numero fisso. A ciascun ruolo di attributo può corrispondere un insieme fisso di tipi di entità: ad esempio, tipi di entità quali Location-Street, Location-City o Location-Route possono essere utilizzati in modo intercambiabile come attributi con il ruolo Location.
Di seguito illustriamo le caratteristiche principali del corpus SmartData.
Relazioni. Il corpus prevede 15 tipi di relazione, ciascuno con due attributi obbligatori e alcuni facoltativi. La figura 3 illustra la distribuzione delle relazioni e degli attributi.
Entità. SmartData offre 16 tipi di entità ben definiti. Per un elenco completo, si veda (Schiersch et al., 2018). Introduciamo l’esplicitezza come parametro per dimostrare che solo pochi tipi di entità costituiscono un indicatore significativo di una relazione (cfr. «Jam Length» o «Position» nella Figura 3). Di conseguenza, i modelli MARE devono apprendere una visione combinata dei complessi di entità.
Numero variabile di attributi di relazione. Ogni relazione contiene almeno uno di ciascuno degli attributi obbligatori. Può contenere o meno ulteriori attributi facoltativi. L'esempio relativo alle differenze discutibili riportato nella Figura 5 mostra un feed RSS con una relazione "Obstruction". Solo gli attributi "trigger" e "location" sono obbligatori. Gli attributi "StartLoc" e "EndLoc" sono facoltativi.
Sbilanciato. I set di dati sbilanciati pongono la sfida di individuare la struttura essenziale sia per i punti dati sottorappresentati che per quelli più abbondanti (Mountassir et al., 2012). Il set di dati è sbilanciato sia in termini di relazioni che di attributi (cfr. Figura 3): Traffic Jam si verifica circa 10 volte più spesso di Spin Off. Mentre le frequenze degli attributi di Spin Off sono abbastanza simili, gli attributi di Traffic Jam mostrano una differenza nella distribuzione degli attributi, che corrisponde agli attributi obbligatori e facoltativi.
Trigger non corretti. Nei corpora dedicati all’estrazione di eventi, i trigger sono rigorosamente definiti come un singolo token o span obbligatorio, dato il loro ruolo essenziale di indicatori di relazione (Consortium, 2005; Aguilar et al., 2014). SmartData non segue questi vincoli: i trigger sono opzionali e non sono vincolati a token consecutivi né a alcun lemma o parte del discorso specifico. Pertanto, questo corpus impedisce l'applicazione degli attuali approcci di estrazione di eventi a causa del loro presupposto dell'esistenza di un unico token/span trigger.
Entità correlate. In un unico documento possono essere presenti più relazioni. Le entità delle relazioni corrispondenti non devono necessariamente essere disgiunte: ad esempio, "Ingorgo" e "Ostacolo" possono comparire insieme e condividere attributi di posizione.
Diversi registri linguistici. SmartData utilizza fonti di dati diverse, il che comporta distribuzioni diverse e modelli di pattern che devono essere appresi. Mentre gli articoli di cronaca sono testi continui e grammaticalmente corretti, i feed di Twitter e RSS sono spesso costituiti da frammenti di frasi.
Il corpus SmartData offre relazioni con un numero variabile di attributi e prive di una definizione regolare dei trigger, il che lo rende conforme alla definizione MARE. Sono necessarie alcune modifiche per poter applicare gli attuali approcci di estrazione di relazioni o eventi.
2 https://github.com/DFKI-NLP/smartdata-corpus
3 Centro tedesco di ricerca sull'intelligenza artificiale (Traduzione: German Research Center for Artificial Intelligence)
4 I numeri differiscono da quelli dell'articolo originale a causa delle diverse versioni
4. MARE
Questa sezione introduce formalmente il concetto di estrazione di relazioni multi-attributo e presenta due approcci MARE. Descriviamo la nostra metodologia di valutazione, che prevede l'adattamento di un approccio per l'estrazione di eventi e relazioni binarie. Confrontiamo entrambi gli approcci con quelli MARE.
4.1 Definizione
Per un dato testo t = (t₁, …, t_n) con n gettoni,
S = {(ti,…,tj) | per ogni i, j ∈ {1,…,n}, i ≤ j}
indica l'insieme di tutti i segmenti di testo. Sia L un insieme di etichette di relazione e Al un insieme di ruoli di attributo per ciascuna etichetta di relazione l ∈ L. Il compito consiste nel prevedere un insieme di relazioni R per un dato testo t. Ogni istanza di relazione r ∈ R
r = (l, {α_i | per ogni i ∈ {1,…,m}})
è costituito da un'etichetta di relazione l e da un numero variabile di
0 < m ≤ |S| attributi
αi = (s,a) ∈ S×Al per ogni i ∈ {1,…,m}.
Ogni intervallo s ∈ S può contribuire al massimo a un solo attributo in ciascuna relazione r ∈ R. Tuttavia, un intervallo può contribuire ad attributi presenti in più relazioni. Consentiamo esplicitamente l'esistenza di relazioni con un solo attributo. Indichiamo gli intervalli di testo s_(ij) con i e j come indici di inizio e fine. Inoltre,
A = ∪₍₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎₎
è l'insieme di tutti i ruoli degli attributi.
La definizione formale non fa alcuna distinzione tra attributi obbligatori e facoltativi, come indicato nella Sezione 3. Continuiamo tuttavia a utilizzare questa distinzione per la valutazione del modello, poiché una maggiore frequenza di un ruolo di attributo implica una migliore performance di estrazione.
4.2 Approcci
Tutti gli approcci, ad eccezione dei modelli di riferimento, utilizzano reti Transformer come embedder contestualizzati. Tali reti calcolano rappresentazioni contestualizzate combinando più livelli di auto-attenzione e di propagazione in avanti. Sono addestrate in modo non supervisionato (Devlin et al., 2019). Applichiamo una versione in tedesco di ELECTRA5 (May e Reißel, 2020). I suoi compiti di pre-addestramento si concentrano sulla capacità dei modelli di descrivere la struttura semantica dei testi (Clark et al., 2020). Tutti gli approcci utilizzano la versione dell'algoritmo di ottimizzazione Adam con decadimento dei pesi introdotta in (Loshchilov e Hutter, 2019).
Di seguito utilizzeremo le definizioni introdotte nella Sezione 4.1.
4.2.1 Identificazione delle sequenze
Il numero indefinito di attributi in MARE richiede modelli che non debbano enumerare tutti i candidati di relazione. (Zheng et al., 2017) hanno introdotto uno schema di tagging per formulare l'estrazione di relazioni binarie come un problema di sequence tagging.
T = {b, i} × L × A ∪ {o}
descrive il nostro insieme di tag. I tag che iniziano con b e i contrassegnano i token come inizio o parte interna di un'entità. Per gli span dell'entità risultante, l'etichetta l ∈ L determina la relazione, mentre a ∈ Al determina il ruolo dell'attributo per una relazione determinata da l. o contrassegna i token che non appartengono a un attributo.
Da ogni sequenza di token contrassegnati, estraiamo un insieme di attributi di relazione incoerenti. Questi attributi vengono raggruppati in istanze di relazione in base alla loro etichetta di relazione.
La sequenza di input incorporata e contestualizzata costituisce l'input per un livello feed-forward, che la mappa alle probabilità delle etichette. Un campo casuale condizionale determina la perdita e la sequenza di etichette più probabile. (Huang et al., 2015) descrive i dettagli dei campi casuali condizionali per il tagging di sequenze.
Il nostro modello di tagging delle sequenze evita di enumerare tutti i potenziali candidati per le relazioni. Tuttavia, ciò comporta anche le due seguenti limitazioni:
1. Attributi condivisi tra relazioni. Più relazioni possono avere attributi con segmenti di testo in comune. Il nostro schema di tagging può assegnare ciascun segmento al massimo a una sola relazione.
2. Relazioni multiple con la stessa etichetta. Un campione può presentare più relazioni con la stessa etichetta. Ad esempio, due descrizioni di incidenti in un unico campione. Un raggruppamento basato sull'etichetta porta a una singola relazione anziché a più istanze.
Introduciamo un livello di logica di business per gestire tali situazioni. Nel caso in cui gli attributi condivisi si estendano su più relazioni, verifichiamo se nelle relazioni attuali manchino attributi obbligatori. In tal caso, cerchiamo i tipi di attributo che indicano argomenti condivisi. Se un attributo di questo tipo rientra nella larghezza massima della relazione⁶, lo utilizziamo per completare la relazione.
Di seguito, si ipotizza che gli attributi delle relazioni siano ordinati in base ai loro indici di estensione. Per gestire più relazioni con la stessa etichetta in un unico campione, si divide una relazione raggruppata α1,…,αn in corrispondenza di un indice i < n se i sottoinsiemi α1,…,αi e αi+1,…,αn contengono tutti gli attributi obbligatori e la distanza tra αi e αi+1 supera la larghezza massima della relazione.
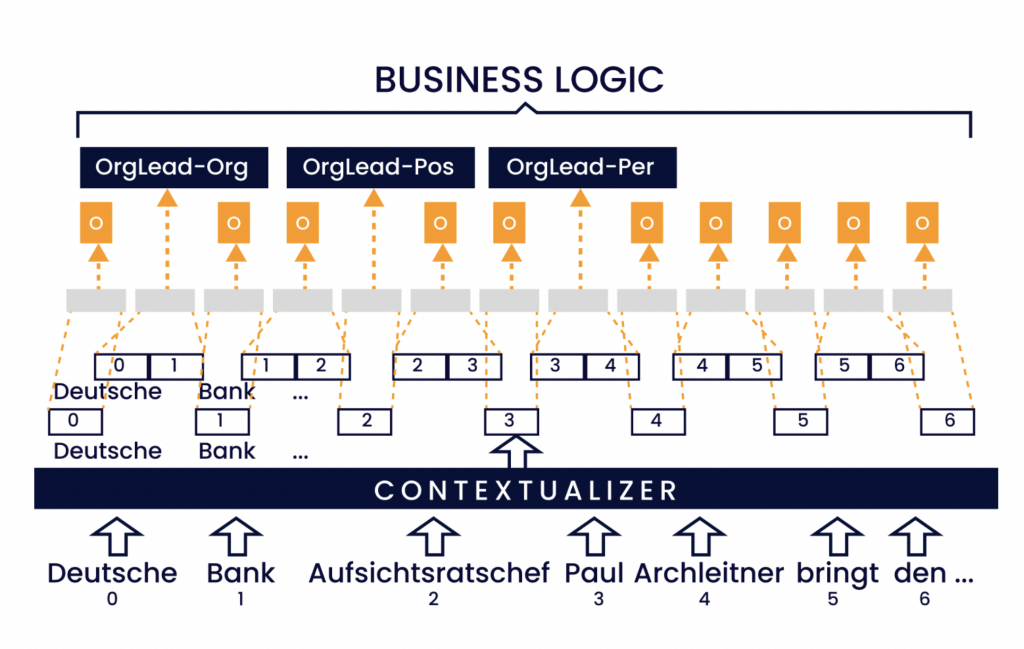
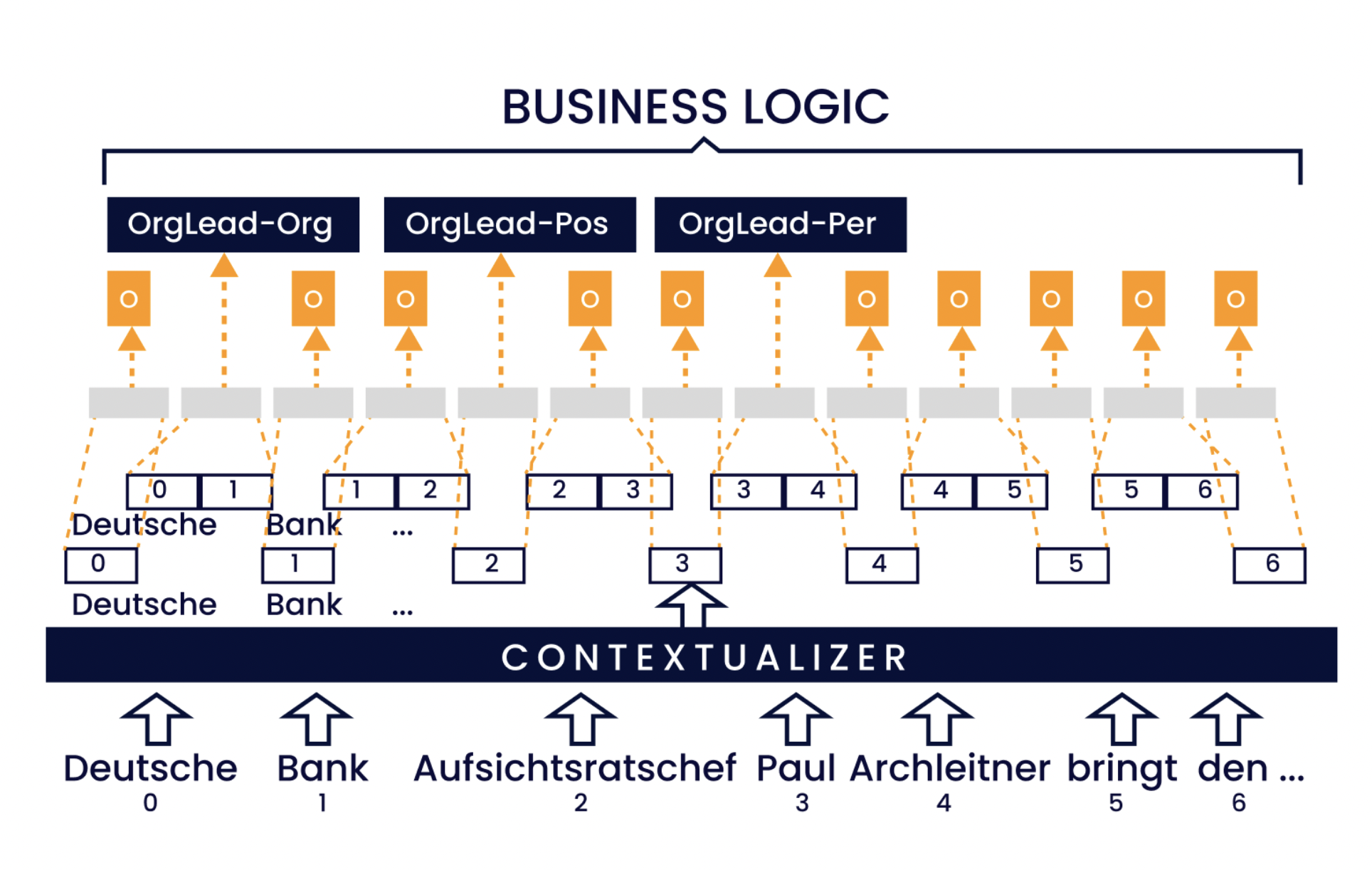
Figura 4: Illustrazione dell'approccio di etichettatura degli span. La sequenza di input viene incorporata e contestualizzata. Ogni span di testo, entro una larghezza massima dello span (2 in questo esempio), viene trasformato in una rappresentazione a lunghezza fissa etichettata con una combinazione di etichetta di relazione e ruolo dell'argomento. Infine, la logica di business raggruppa gli attributi in relazioni.
4.2.2 Etichettatura degli intervalli
Il nostro secondo approccio si ispira a (Liu et al., 2019). Gli autori hanno applicato un approccio basato sull'etichettatura delle sequenze anziché sul tagging delle sequenze. L'etichettatura consente di assegnare più etichette di attributo a ciascun intervallo di testo. Abbiamo modificato questo approccio per prevedere un'etichetta di attributo relazionale per ogni possibile intervallo di testo in un dato campione. Come il nostro approccio basato sul tagging delle sequenze, anche questo non richiede l'enumerazione di tutti i candidati di relazione e risolve il problema degli attributi condivisi tra le relazioni.
Sia T = L×A un insieme di etichette che indicano l'etichetta di relazione e il ruolo dell'attributo per un dato intervallo di testo. Il modello prevede una probabilità P(t|s) per ogni etichetta t ∈ T e ogni intervallo s ∈ S. Un iperparametro relativo alla larghezza massima dell'intervallo definisce il numero massimo di token per intervallo in S. Applichiamo una funzione di perdita di entropia incrociata binaria, che consente l'assegnazione di più etichette per ogni intervallo.
La Figura 4 illustra l'architettura del nostro modello. Le rappresentazioni degli span vengono calcolate con un modulo basato sull'auto-attenzione tratto da AllenNLP7. Per un dato testo di lunghezza n, calcoliamo gli embedding contestualizzati (c1,…,cn) di dimensione d. Per ogni span sij, disponiamo di j−i+1 embedding (ci,…,cj). Per ottenere una rappresentazione dello span a lunghezza fissa di dimensione d, calcoliamo una combinazione lineare di questi embedding. Una matrice di parametri M ∈ Rd×1 calcola i punteggi di attenzione globali ai = ci ·M per tutti gli i ∈ {1,…,n}. Questi vengono utilizzati per calcolare i pesi wi,…,wj per uno span sij, con
picco
wk = a per ogni k in {i,…,j}.
La somma dei numeri interi compresi tra i e j è
La funzione softmax garantisce che la somma dei pesi di ogni intervallo sia pari a 1. Le rappresentazioni finali degli intervalli sono una combinazione lineare di questi pesi e delle immersioni.
Uno strato feed-forward, in combinazione con la funzione sigmoide applicata elemento per elemento, calcola le probabilità di etichetta per ogni intervallo. Analogamente all'approccio precedente, ciò porta a un insieme di istanze di relazione raggruppate. Applichiamo la stessa logica di business descritta nella Sezione 4.2.1, poiché permane il vincolo relativo alla presenza di più relazioni con la stessa etichetta.
4.2.3 Estrazione degli eventi
Per applicare gli approcci di estrazione degli eventi, è necessario specificare un trigger di evento per ogni relazione multi-attributo. Come illustrato nella Sezione 3, alcune istanze nel
Il corpus SmartData non presenta annotazioni di questo tipo. Se la definizione di una relazione non prevede un attributo trigger obbligatorio, abbiamo definito un tipo di attributo obbligatorio per ciascuna relazione come trigger. Nel caso di intervalli trigger multipli e non congiunti, selezioniamo il primo intervallo come trigger. Non abbiamo applicato una logica più complessa poiché l'insieme delle relazioni con trigger multipli (78 su 1264) è relativamente piccolo. La prima situazione di errore nella Sezione 4.2.1 rimane irrisolta se le relazioni condividono i trigger. Altri attributi possono essere condivisi tra le relazioni.
Come approccio per l'estrazione degli eventi utilizziamo Dygie++8. Come descritto da (Wadden et al., 2019), Dygie++ utilizza rappresentazioni contestualizzate degli span, analogamente a quanto illustrato nella Sezione 4.2.2. Il rilevamento dei trigger e la disambiguazione degli attributi si avvalgono di queste rappresentazioni condivise degli span.
4.2.4 Estrazione delle relazioni binarie
Molti approcci all'estrazione di relazioni binarie classificano tutte le possibili coppie di entità come potenziali relazioni, come nel caso di SpERT (Eberts e Ulges, 2019). In combinazione con l'etichettatura multiclasse, ciò risolve entrambe le situazioni di errore descritte nella sezione 4.2.1.
Utilizziamo SpERT per estrarre relazioni binarie da 1.717 dei 1.864 campioni del set di addestramento che contengono relazioni con esattamente due attributi obbligatori. La sezione seguente illustra diverse strategie di valutazione. Presentiamo una strategia di estrazione delle relazioni binarie per confrontare le prestazioni di SpERT con quelle di tutti gli altri approcci sul sottoinsieme delle relazioni binarie valide.
4.3 Configurazione sperimentale
Abbiamo utilizzato AllenNLP (Gardner et al., 2017) e PyTorch per implementare l'approccio basato sul sequence tagging e sullo span labeling. Il nostro repository GitHub contiene versioni modificate di Dygie++ e SpERT. Tali modifiche si sono rese necessarie per integrare entrambi gli approcci nella nostra infrastruttura sperimentale.
Il nostro repository GitHub contiene una sintesi di tutti gli iperparametri e dei relativi valori nei modelli finali. Tutti gli iperparametri sono stati determinati con Optuna9. Abbiamo eseguito 50 iterazioni di ottimizzazione per ciascun modello. Abbiamo fissato il tasso di apprendimento per il livello di embedding della rete transformer a 5 · 10−5 e a 10−3 per tutti gli altri componenti della rete. Abbiamo selezionato una dimensione del batch pari a 6 per tutti gli approcci MARE, mentre per SpERT e Dygie++ abbiamo scelto una dimensione del batch pari a 1.
Utilizziamo diverse strategie di valutazione per analizzare le previsioni. Tali strategie mirano a rispecchiare le sfide poste da MARE a diversi livelli di complessità.
• Riconoscimento degli attributi (AR) La valutazione viene effettuata a livello di singolo attributo. Un attributo è considerato corretto se i suoi confini, l'etichetta della relazione e il ruolo dell'attributo sono stati previsti correttamente, senza tenere conto del raggruppamento in una relazione.
• Classificazione (Cl): una previsione è corretta se l'etichetta prevista corrisponde a un'etichetta di riferimento.
• Estrazione obbligatoria delle relazioni (MRE): una previsione è corretta se tutti gli attributi obbligatori e l'etichetta della relazione corrispondono all'annotazione di riferimento. Pertanto, è fondamentale raggruppare gli attributi obbligatori in un'unica relazione.
• Estrazione completa delle relazioni (CRE): misura la capacità del modello di estrarre la relazione con tutti gli attributi nel loro insieme. Pertanto, una previsione è considerata corretta se il modello estrae tutti gli attributi e li raggruppa correttamente in una relazione con l'etichetta di relazione corretta.
• Estrazione di relazioni binarie (BRE) Si tratta della strategia MRE applicata al sottoinsieme di campioni che contiene solo relazioni con esattamente due argomenti obbligatori. Questa strategia consente di mettere a confronto SpERT con tutti gli altri approcci.
Includiamo il modello di riferimento (DARE) tratto da (Schiersch et al., 2018), che si concentra sugli argomenti obbligatori e utilizza annotazioni di entità di riferimento. Il nostro modello di riferimento è una modifica dell'approccio basato sul sequence tagging. Sostituiamo la rete Transformer preaddestrata con una combinazione di vettori di parole GloVe10 (Pennington et al., 2014) e una CNN a livello di carattere come strato di embedding. Un livello Bi-GRU contestualizza gli input.
La nostra configurazione di calcolo comprende due nodi dotati di CPU Intel Xeon Platinum 8168, GPU Nvidia Quadro P5000 con 16 GB di RAM e sistema operativo Ubuntu 18.04. La ricerca degli iperparametri ha richiesto circa 24 ore.
5 https://huggingface.co/german-nlp-group/ electra-base-german-uncased
6 La larghezza massima della relazione è un iperparametro e viene determinata tramite una ricerca degli iperparametri. Il repository GitHub contiene la configurazione della ricerca e i valori finali.
7 http://docs.allennlp.org/main/api/modules/ estrattori di span/estrattore di span automatico/
8 https://github.com/dwadden/dygiepp
9 https://optuna.org/
5. Risultati
Gli indicatori riportati nella tabella 2 misurano diverse capacità necessarie per estrarre contemporaneamente tutti gli attributi, i loro ruoli e l'etichetta della relazione. In generale, all'aumentare dei requisiti degli indicatori, i valori degli stessi diminuiscono.
L'approccio basato sull'etichettatura degli span aumenta i risultati AR dell'estrazione di eventi di 0,06 e quelli Cl di 0,04 nei punteggi F1. Osserviamo che entrambi gli approcci MARE ottengono prestazioni migliori rispetto a Dygie++ sul set di dati completo. Il punteggio MRE simile e l'aumento dei punteggi AR e CRE indicano che i modelli MARE estraggono gli argomenti opzionali e potenzialmente meno frequenti in modo più affidabile. Una riduzione al sottoinsieme di documenti con esattamente due argomenti obbligatori porta a punteggi generali più alti, ma a un aumento molto maggiore per Dygie++ rispetto ai modelli MARE. Entrambe le osservazioni indicano che le architetture di modello con meno ipotesi strutturali sono più adatte alle caratteristiche uniche del corpus, come descritto nella Sezione 3.
Tabella 2: Valutazione del modello sul set di test in base a diverse strategie, cfr. la Sezione 4.3. Come metriche di confronto vengono utilizzati la precisione, il richiamo e il punteggio F1.
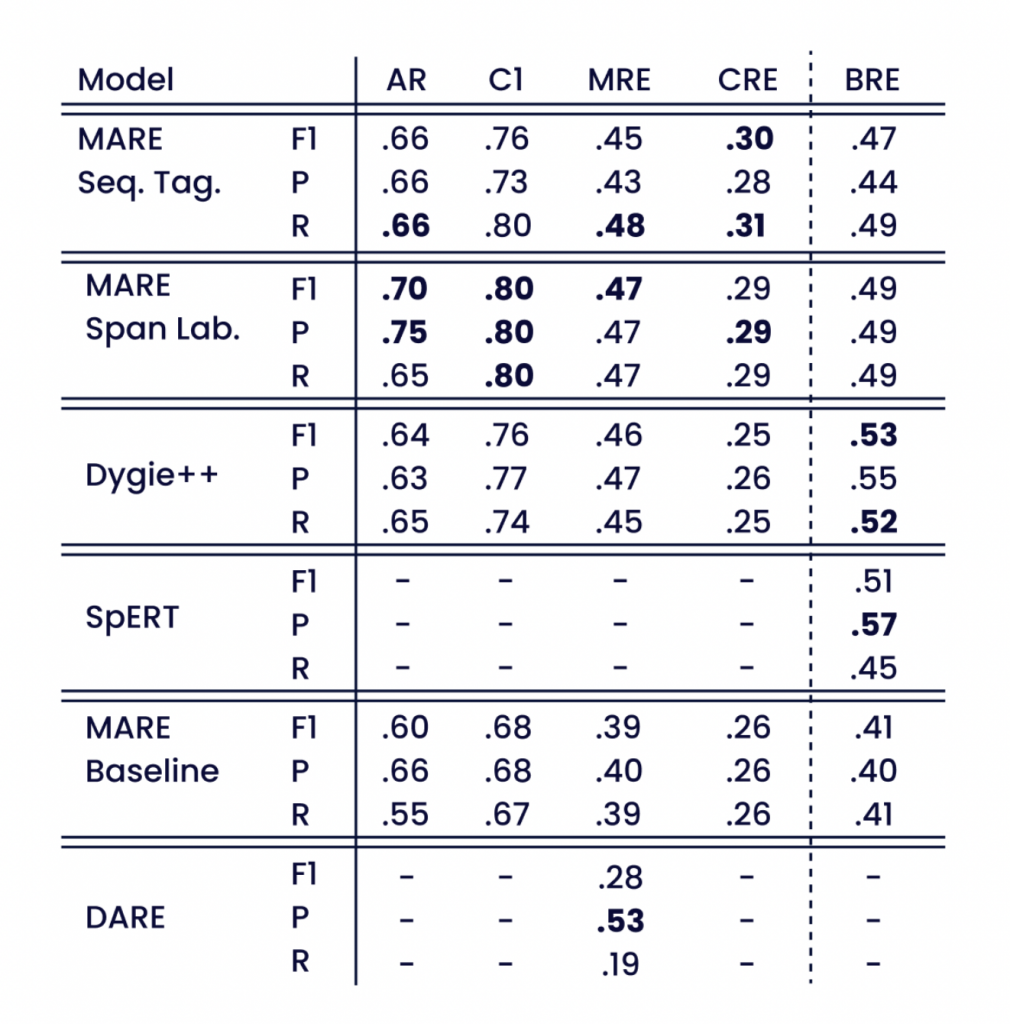
La differenza tra il benchmark MARE di riferimento e i due approcci MARE evidenzia l'effetto positivo delle reti Transformer preaddestrate. Nonostante le prestazioni complessivamente inferiori di DARE, che utilizza un insieme di regole selezionato automaticamente, il benchmark originale registra il punteggio di precisione MRE più elevato. Ciò indica un'elevata affidabilità delle relazioni estratte e un numero elevato di falsi negativi a causa del basso punteggio di richiamo.
La valutazione di SpERT evidenzia un netto miglioramento rispetto al nostro modello di riferimento MARE. SpERT offre inoltre prestazioni migliori rispetto ai nostri modelli MARE sul set di dati BRE.
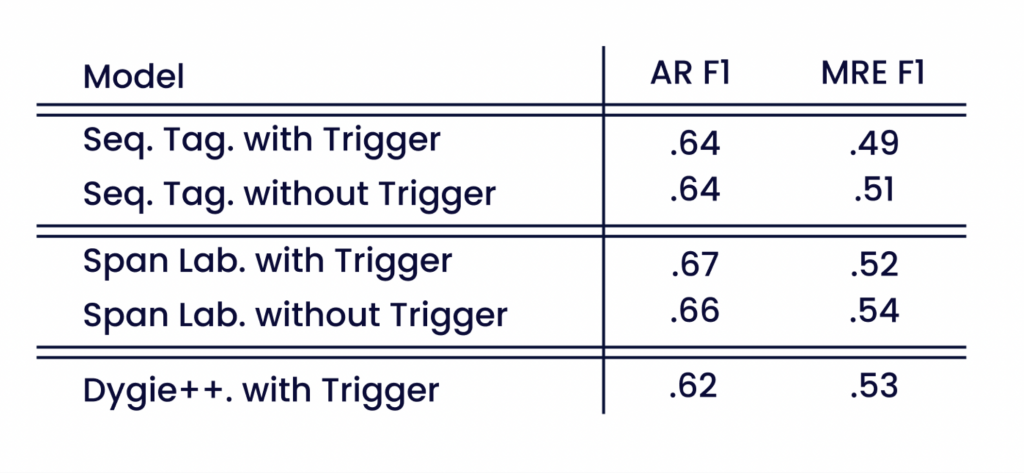
La tabella 3 mostra come le annotazioni dei trigger influenzino le prestazioni dei modelli MARE. Le valutazioni condotte su un sottoinsieme ridotto di attributi non trigger dei modelli MARE addestrati sia con che senza annotazioni dei trigger non evidenziano differenze significative nei punteggi AR e MRE. Le prestazioni dei nostri modelli senza annotazioni trigger sono paragonabili all'estrazione di eventi all'avanguardia sulle relazioni multi-attributo dal corpus Smart-Data. Il punteggio AR dei modelli MARE è migliore di quello di Dygie++. Ciò dimostra la capacità di MARE di estrarre attributi opzionali e meno frequenti.
Rispetto alla tabella 2, i punteggi AR diminuiscono, indicando che i modelli estraggono gli attributi trigger in modo affidabile. In assenza di attributi trigger, permangono molte relazioni basate su un singolo attributo. Ciò semplifica il compito di MRE e determina un aumento dei punteggi MRE.
Poiché l'estrazione delle relazioni è un'attività di alto livello semantico e le annotazioni di riferimento di SmartData presentano un certo grado di incoerenza, forniamo un'analisi manuale degli errori per comprendere meglio le caratteristiche predittive dei nostri modelli.
5.1 Controllo degli errori
Abbiamo effettuato un confronto manuale delle differenze tra le annotazioni di riferimento e le previsioni dei modelli. Dalla nostra analisi manuale emergono le seguenti classi di equivalenza di errore. Tutti gli esempi citati nell'elenco che segue si riferiscono alla Figura 5.
1. Differenze discutibili Le previsioni dei modelli sono spesso plausibili anche se i dati di riferimento contengono annotazioni divergenti. L'esempio mostra una relazione di "Ostruzione", in cui la maratona rappresenta la causa dell'ostruzione. L'annotazione di riferimento non riflette questa circostanza. Le differenze discutibili indicano che i nostri modelli hanno appreso determinati concetti semantici. Alcune generalizzazioni nelle previsioni portano a falsi positivi che abbassano le metriche di valutazione.
2. Classi di relazioni semanticamente correlate Alcune classi di relazioni, come "Incidente" e "Ostacolo", presentano una forte relazione semantica. Pertanto, le istanze di queste relazioni sono spesso annidate e condividono intervalli di entità come attributi. Le annotazioni di questi attributi condivisi sono spesso errate. L'esempio mostra un'Ostruzione causata da un Disastro. L'annotazione di riferimento contiene due relazioni separate e non esprime questa dipendenza. Il fattore scatenante del Disastro potrebbe anche essere interpretato come la causa dell'Ostruzione. Questa distinzione rappresenta una sfida per i modelli.
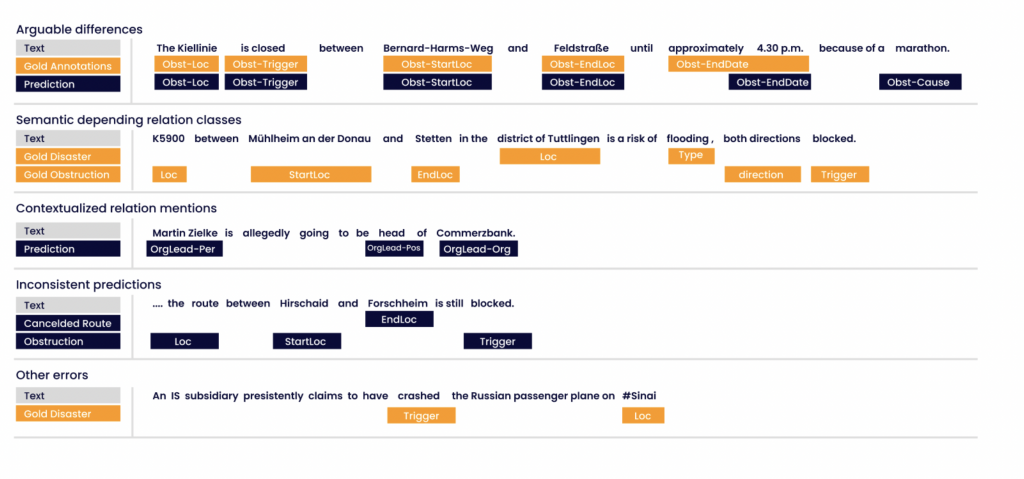
Figura 5: Esempi di classi di errore. I riquadri colorati indicano le relazioni e i relativi attributi. Il ruolo degli attributi è annotato testualmente. Previsioni ottenute con l'approccio di etichettatura degli span.
3. Menzioni di relazioni contestualizzate Molte presunte istanze di relazione compaiono in un contesto di supposizione. Parole come «presumibilmente» indicano supposizioni piuttosto che fatti. L'esempio mostra una supposizione riguardante la leadership di un'organizzazione. In molti di questi casi, i modelli hanno previsto istanze di relazione.
4. Previsioni incoerenti L'esempio mostra una relazione di "Ostruzione", in cui il modello ha previsto correttamente tutti i ruoli. L'etichetta della relazione per la "Posizione finale" appartiene a una relazione semantica simile. Se gli attributi mancanti non sono obbligatori, tali situazioni non possono essere risolte dalla logica di business.
5. Altri errori Molte relazioni non vengono riconosciute dai modelli. Spesso tali errori si verificano in frasi con una struttura grammaticale meno articolata e in frasi che contengono molti caratteri speciali come "@", "#" o frasi chiave tipiche che non appartengono ad alcuna relazione. L'esempio mostra un evento catastrofico che nessun modello aveva previsto.
I risultati indicano che gli attuali approcci all'estrazione di eventi o relazioni binarie superano i modelli MARE nel compito di estrazione delle relazioni binarie. Tuttavia, allentando i requisiti strutturali, i modelli MARE risultano superiori. Gli approcci MARE presentati consentono l'estrazione di relazioni complesse a più attributi dal testo semplice senza dover enumerare tutti i candidati di relazione. I limiti dei nostri approcci, descritti nella Sezione 4.2, non hanno avuto un impatto significativo sul corpus di dati intelligenti.
10 https://deepset.ai/german-word-embeddings
6. Conclusione
Abbiamo introdotto il concetto di estrazione di relazioni multi-attributo, distinguendo questa definizione dalla terminologia corrente, ovvero l'estrazione di relazioni n-arie e l'estrazione di eventi. La nostra definizione del problema porta ad approcci semplificati per l'estrazione di relazioni con un numero arbitrario di attributi, evitando il ricorso all'enumerazione dei candidati e al concetto di trigger.
I modelli MARE risultano superiori quando le relazioni non rientrano in schemi binari o basati sugli eventi. Essi evitano i vincoli strutturali e offrono prestazioni migliori rispetto agli attuali approcci all'avanguardia per l'estrazione di relazioni ed eventi sul corpus SmartData.
In futuro intendiamo integrare i risultati dell'analisi manuale nell'elaborazione di approcci MARE migliorati. In particolare, intendiamo affrontare i limiti degli approcci MARE e l'integrazione del contesto specifico delle relazioni.
7. Bibliografia
Aguilar, J., Beller, C., McNamee, P., Van Durme, B., Strassel, S., Song, Z. ed Ellis, J. (2014). Un confronto tra eventi e relazioni negli standard di annotazione ACE, ERE, TAC-KBP e FrameNet. In Atti del Secondo Workshop su EVENTS: Definizione, Rilevamento, Coreferenza e Rappresentazione, pagine 45–53, Baltimora, Maryland, USA. Associazione per la Linguistica Computazionale.
Clark, K., Luong, M.-T., Le, Q. V. e Manning, C. D. (2020). ELECTRA: Pre-addestramento degli encoder di testo come discriminatori anziché come generatori. arXiv:2003.10555 [cs]. arXiv: 2003.10555.
Consortium, L. D. (2005). Linee guida ACE (Automatic Content Extraction) per l'annotazione in inglese degli eventi. Pagina 77.
Devlin, J., Chang, M.-W., Lee, K. e Toutanova, K. (2019). BERT: Pre-addestramento di trasformatori bidirezionali profondi per la comprensione del linguaggio. arXiv:1810.04805 [cs]. arXiv: 1810.04805.
Eberts, M. e Ulges, A. (2019). Estrazione congiunta di entità e relazioni basata su span con pre-addestramento Transformer. arXiv:1909.07755 [cs]. arXiv: 1909.07755.
Gardner, M., Grus, J., Neumann, M., Tafjord, O., Dasigi, P., Liu, N. F., Peters, M., Schmitz, M. e Zettlemoyer, L. S. (2017). Allennlp: una piattaforma di elaborazione semantica avanzata del linguaggio naturale.
Hendrickx, I., Kim, S. N., Kozareva, Z., Nakov, P., Ó Seághdha, D., Pado, S., Pennacchiotti, M., Romano, L. e Szpakowicz, S. (2010). SemEval-2010 Task 8: Classificazione a più vie delle relazioni semantiche tra coppie di nomi. In Atti del 5° Workshop internazionale sulla valutazione semantica, pagine 33–38, Uppsala, Svezia. Associazione per la Linguistica Computazionale.
Huang, Z., Xu, W. e Yu, K. (2015). Modelli LSTM-CRF bidirezionali per il tagging di sequenze. arXiv:1508.01991 [cs]. arXiv: 1508.01991.
Kim, J.-D., Pyysalo, S., Ohta, T., Bossy, R., Nguyen, N. e Tsujii, J. (2011a). Panoramica del BioNLP Shared Task 2011. In Atti del workshop BioNLP Shared Task 2011, pp. 1–6, Portland, Oregon, USA. Association for Computational Linguistics.
Kim, J.-D., Wang, Y., Takagi, T. e Yonezawa, A. (2011b). Panoramica sul compito relativo all’evento Genia nell’ambito del BioNLP Shared Task 2011. In Atti del workshop BioNLP Shared Task 2011, pp. 7–15, Portland, Oregon, USA. Association for Computational Linguistics.
Lai, P.-T. e Lu, Z. (2021). BERT-GT: Estrazione di relazioni n-arie tra frasi con BERT e Graph Transformer. Bioinformatics.
Li, C. e Tian, Y. (2020). Progettazione del modello a valle di un modello linguistico pre-addestrato per il compito di estrazione delle relazioni. arXiv:2004.03786 [cs]. arXiv: 2004.03786 versione: 1.
Liu, Y., Li, A., Huang, J., Zheng, X., Wang, H., Han, W. e Wang, Z. (2019). Estrazione congiunta di entità e relazioni basata sulla classificazione multi-label. In 2019 IEEE Fourth International Conference on Data Science in Cyberspace (DSC), pp. 106–111.
Loshchilov, I. e Hutter, F. (2019). Regolarizzazione con decadimento dei pesi disaccoppiato. arXiv:1711.05101 [cs, math]. arXiv: 1711.05101.
May, P. e Reißel, P. (2020). German Electra: una nuova prospettiva.
Mintz, M., Bills, S., Snow, R. e Jurafsky, D. (2009). Supervisione a distanza per l'estrazione di relazioni senza dati etichettati. In Atti della Conferenza congiunta del 47° incontro annuale dell’ACL e della 4ª Conferenza internazionale congiunta sull’elaborazione del linguaggio naturale dell’AFNLP: Volume 2 – ACL-IJCNLP ’09, volume 2, pagina 1003, Suntec, Singapore. Associazione per la Linguistica Computazionale.
Mountassir, A., Benbrahim, H. e Berrada, I. (2012). Uno studio empirico sul problema dei set di dati sbilanciati nella classificazione del sentiment. In 2012 IEEE International Conference on Systems, Man, and Cybernetics (SMC), pp. 3298–3303.
Peng, N., Poon, H., Quirk, C., Toutanova, K. e Yih, W.-t. (2017). Estrazione di relazioni N-arie tra frasi con LSTM grafiche. Transactions of the Association for Computational Linguistics, 5:101–115.
Pennington, J., Socher, R. e Manning, C. (2014). GloVe: vettori globali per la rappresentazione delle parole. In Atti della Conferenza 2014 sui metodi empirici nell'elaborazione del linguaggio naturale (EMNLP), pp. 1532–1543, Doha, Qatar. Associazione per la Linguistica Computazionale.
Roller, R., Rethmeier, N., Thomas, P., Hübner, M., Uszkoreit, H., Staeck, O., Budde, K., Halleck, F. e Schmidt, D. (2018). Rilevamento di entità denominate e relazioni nelle relazioni cliniche in tedesco. In Rehm, G. e Declerck, T., a cura di, Language Technologies for the Challenges of the Digital Age, Lecture Notes in Computer Science, pagine 146–154, Cham. Springer International Publishing.
Schiersch, M., Mironova, V., Schmitt, M., Thomas, P., Gabryszak, A. e Hennig, L. (2018). Un corpus tedesco per il riconoscimento dettagliato delle entità denominate e l'estrazione delle relazioni relative a eventi nel settore dei trasporti e dell'industria. Pagina 8.
Tsujii, J., Kim, J.-D. e Pyysalo, S., a cura di (2011). Atti del workshop BioNLP Shared Task 2011, Portland, Oregon, USA. Associazione per la Linguistica Computazionale.
Viera, A. J., Garrett, J. M., et al. (2005). Comprendere la concordanza interosservatore: la statistica kappa. Fam med, 37(5):360–363.
Wadden, D., Wennberg, U., Luan, Y. e Hajishirzi, H. (2019). Estrazione di entità, relazioni ed eventi con rappresentazioni contestualizzate degli span. In Atti della Conferenza 2019 sui metodi empirici nell'elaborazione del linguaggio naturale e della 9a Conferenza internazionale congiunta sull'elaborazione del linguaggio naturale (EMNLP-IJCNLP), pagine 5784–5789, Hong Kong, Cina. Associazione per la linguistica computazionale.
Xiang, W. e Wang, B. (2019). Una rassegna sull'estrazione di eventi dal testo. IEEE Access, 7:173111–173137. Nome della conferenza: IEEE Access.
Xu, F., Uszkoreit, H., Li, H., Adolphs, P. e Cheng, X. (2013). Estrazione di relazioni adattiva al dominio per il Web semantico.
Zheng, S., Wang, F., Bao, H., Hao, Y., Zhou, P. e Xu, B. (2017). Estrazione congiunta di entità e relazioni basata su un nuovo schema di tagging. arXiv:1706.05075 [cs]. arXiv: 1706.05075.