Il progresso tecnologico ha rivoluzionato radicalmente il modo di utilizzare i computer negli ultimi anni. Quasi nessun altro settore ha modificato in modo così significativo le modalità di lavoro delle persone. La comunicazione digitale è ormai efficace e scontata sia nella sfera privata che in quella professionale. I settori più arretrati risentono delle loro forme di comunicazione obsolete e stanno investendo nell’ottimizzazione.
Attualmente sono molto diffuse sia le soluzioni che consentono la comunicazione umana in linguaggio naturale tra persone, sia quelle che realizzano la comunicazione formale di dati tra sistemi informatici. Le prime rientrano nell'ambito delle e-mail, dei social media e delle chat. Molte aziende ricevono un gran numero di richieste di comunicazione in linguaggio naturale attraverso i canali sopra descritti. Finora, un'elevata percentuale di testo continuo rappresenta un ostacolo alla digitalizzazione e comporta costi elevati a causa di un'elaborazione prevalentemente manuale.
Il linguaggio naturale è caratterizzato soprattutto da un’elevata diversità, variabilità e ambiguità. Questi fattori rendono quasi impossibile l’elaborazione automatizzata con i metodi classici dell’informatica, come ad esempio grammatiche, dizionari o analizzatori sintattici. Al contrario, gli esseri umani possiedono una predisposizione genetica a ricavare informazioni dal contesto linguistico e a gestire così questi fattori.
Il settore di ricerca Elaborazione del linguaggio naturale (NLP) studia l'interfaccia tra i computer e il linguaggio naturale. In linea di massima, in questo campo non si cerca di implementare algoritmi di risoluzione basandosi esclusivamente su regole formulate in modo operativo (codice di programma ecc.). Piuttosto, le regole vengono apprese sulla base dei dati disponibili, dando origine a un modello statistico (Apprendimento automatico, ML). Una volta che il modello statistico è stato addestrato a sufficienza in questa forma, è possibile elaborare correttamente anche testi sconosciuti con un elevato grado di affidabilità. La combinazione di regole create manualmente e regole apprese genera un algoritmo efficace per l'elaborazione del linguaggio naturale, che funge da base per una vasta gamma di casi d'uso.

I metodi di apprendimento automatico sono oggetto di ricerca già dagli anni '50. Con l'avvento del deep learning nell'elaborazione delle immagini e del linguaggio negli anni 2010, questi metodi hanno trovato sempre più spazio nelle aziende.
La figura 1 illustra il processo di sviluppo delle applicazioni di elaborazione del linguaggio naturale (NLP). Per ottenere un insieme di dati di addestramento il più rappresentativo e sufficientemente ampio possibile, viene eseguita un'elaborazione manuale (tagging) al fine di creare una soluzione di riferimento. Questo insieme di dati (corpus annotato) costituisce la base per l'addestramento del modello, ovvero della distribuzione statistica. Il processo di sviluppo si conclude dopo alcune fasi di ottimizzazione facoltative.
Durante la fase di produzione successiva, sulla base di questo modello vengono analizzati testi sconosciuti. A seconda dell'applicazione specifica, si procede ad esempio all'estrazione di informazioni, ovvero all'identificazione di strutture semantiche note presenti nel testo, oppure all'analisi dello stato d'animo dell'autore al momento della scrittura. Visto dall'esterno, il modello addestrato funziona come un operatore umano e può essere integrato nei processi esistenti. Il seguente caso di studio illustra questo processo.
Caso di studio
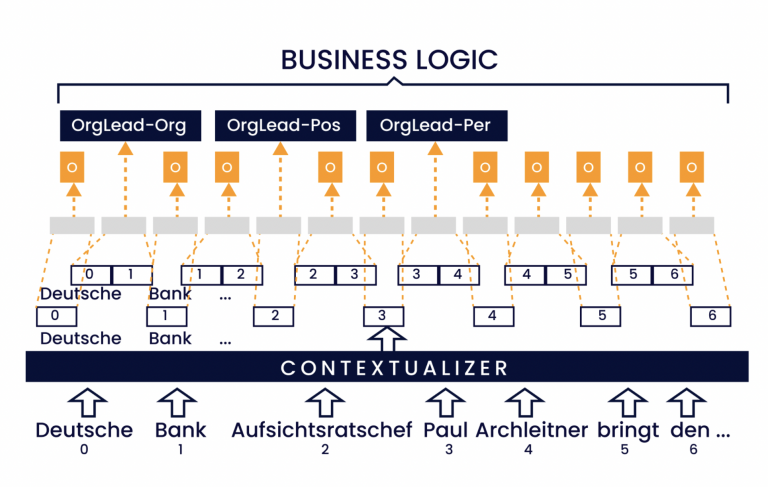
La Deutsche Bahn, in quanto importante operatore nel settore della mobilità, intende rendere più efficace la propria comunicazione con i clienti. Al fine di impiegare nel modo più efficiente possibile le risorse del proprio personale di assistenza, occorre prestare particolare attenzione alle richieste ricorrenti, quali
«Il mio treno da Aquisgrana a Colonia di mercoledì prossimo è stato soppresso; quale treno sostitutivo posso prendere?»
vengono gestite in modo automatizzato. Innanzitutto, si noti che in questo esempio i parametri rilevanti della richiesta vengono indicati in modo specifico:
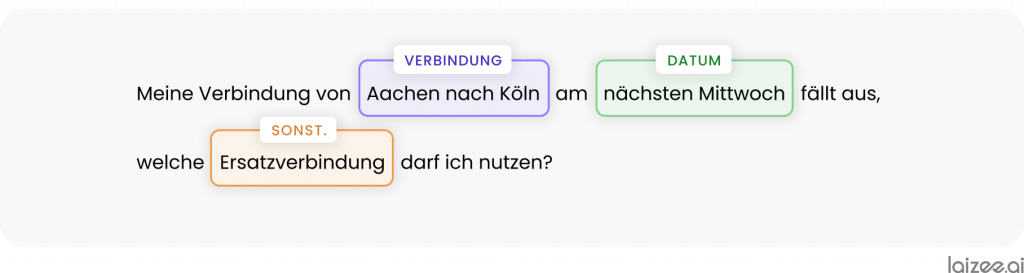
L'estrazione automatizzata di questi concetti noti consente di trasformare automaticamente la richiesta in formato testo in una richiesta strutturata, che può così essere integrata nei processi digitali esistenti.
Durante il processo di addestramento, questi concetti vengono associati alle richieste dei clienti già presenti nel sistema. Con il set di dati di addestramento così ottenuto, viene addestrato un modello statistico in modo tale da poter individuare regolarità nei testi continui sconosciuti ed estrarre le istanze delle classi di concetti addestrate. La combinazione del modello NLP con un'adeguata logica di business può ora essere utilizzata per rispondere in modo automatizzato a una parte delle richieste.
In questo contesto, vorremmo illustrare i vantaggi del ML prendendo come esempio il concetto di data. Per estrarre una data dalle richieste, potremmo utilizzare un'espressione regolare, ad esempio
^\d{1,2}[ \.]{1,2}\d{0,2}[ \.]{0,2}((19|20|21)?\d{0,2})?$da utilizzare in combinazione con un dizionario (lunedì, …, domenica, domani, il prossimo …). Questa forma classica di elaborazione dei dati funziona già bene in molti casi. Tuttavia, anche le più piccole deviazioni dallo schema qui definito comportano che una data non venga più riconosciuta nel testo. Inoltre, questo approccio comporta il rischio di diverse situazioni di errore gravi. Innanzitutto, risulta che errori come, ad esempio, refusi, errori ortografici ecc. non vengono presi in considerazione. Inoltre, vi sono casi in cui le parole del dizionario non vengono utilizzate nel contesto di una data.
«… ho perso il treno e sto aspettando il prossimo, ma lunedì il mio biglietto settimanale non sarà più valido.»
L'esempio mostra che "il prossimo" può anche riferirsi a un treno. In questo caso, l'assenza di punteggiatura, unita alla mancanza di distinzione tra maiuscole e minuscole, rende ancora più difficile definire regole universalmente valide. Un modello di NLP basato sul machine learning addestrato su dati di questo tipo riconosce il riferimento e può quindi identificare solo "lunedì" come indicazione di data.
Il processo di sviluppo e DevOps di questo modello NLP è supportato, analogamente allo sviluppo software convenzionale, da una suite di strumenti specifici per il problema. Framework NLP come spaCy, ad esempio, offrono tutti i metodi necessari per generare modelli NLP a partire dai dati esistenti. La creazione dei dati di addestramento è supportata da strumenti di annotazione specifici per le attività e da strumenti di versioning specifici per il ML, come ad esempio DVC. I modelli creati possono essere distribuiti, gestiti e monitorati in modo efficiente nel cloud tramite tecnologie container come Docker, in combinazione con sistemi per la distribuzione dei container software come Amazon EC² o Kubernetes.
Sintesi
Negli ultimi anni la ricerca nel campo dell'elaborazione del linguaggio naturale (NLP) ha compiuto progressi fondamentali. L'enorme aumento della potenza di calcolo disponibile sta portando alla creazione di modelli sempre più potenti e di sistemi di NLP sempre più efficaci (Google Traduttore ne è solo un esempio positivo).
Secondo uno studio di Gartner[1],l'NLP sta attualmente passando dalla fase di ricerca a quella industriale. Le opportunità offerte dall'NLP basato sull'apprendimento automatico (ML) hanno il potenziale, in molte aziende, di ottimizzare in modo sostanziale e economicamente efficiente i processi IT e, al contempo, di soddisfare le esigenze sempre crescenti dei clienti in termini di disponibilità attraverso un'automazione totale o parziale.
Autori
Prof. Dr. Bodo Kraft
Il Prof. Dr. Bodo Kraft è fondatore e direttore del laboratorio Business Programming. Da oltre dieci anni, insieme a cinque dottorandi, conduce ricerche orientate alle applicazioni nel campo della linguistica computazionale. Il filo conduttore dei vari progetti è la sfida di elaborare in modo efficiente e automatizzato grandi quantità di documenti in lingua naturale.
In questo contesto, è fondamentale che le soluzioni vengano adattate con successo al rispettivo ambito di applicazione. Un altro punto chiave è costituito da un approccio agile e orientato alla qualità per la realizzazione di sistemi software utilizzabili a livello operativo e di facile manutenzione.
Lars Klöser, M.Sc.
Lars Klöser, laureato in Ingegneria Informatica presso la RWTH di Aquisgrana, sta attualmente svolgendo il dottorato di ricerca sotto la supervisione del Prof. Dr. Bodo Kraft e fa parte del Laboratorio di Programmazione Aziendale. Il suo lavoro si concentra sull'elaborazione del linguaggio naturale (NLP) e, in particolare, sull'estrazione di strutture semantiche complesse dai testi giuridici.
[1] https://www.gartner.com/smarterwithgartner/top-trends-on-the-gartner-hype-cycle-for-artificial-intelligence-2019/