1. Introducción
Las pequeñas y medianas empresas (pymes) reconocen cada vez más el potencial de la comprensión del lenguaje natural y la extracción de relaciones para digitalizar procesos y desarrollar nuevos productos de software. Muchas visiones de producto incluyen la extracción de conjuntos de menciones de conceptos de tamaño variable como relaciones a partir de textos, en los que los modelos de datos existentes definen un conjunto de atributos potenciales por relación. Sin embargo, la mayoría de los enfoques actuales se centran en la extracción de relaciones binarias. Por ejemplo, el número de miles de publicaciones científicas biomédicas por semana permitió automatizar con éxito el descubrimiento de conocimiento (Tsujii et al., 2011; Kim et al., 2011a; Kim et al., 2011b). A diferencia de muchos otros ámbitos, la restricción estructural de la binariedad parece razonable debido a las relaciones de causa-efecto. La extracción de relaciones semánticas más complejas requiere actualmente la construcción de sistemas sofisticados basados en clasificaciones binarias. El campo de la extracción de eventos abarca dichos enfoques. Los eventos son relaciones de múltiples atributos con las denominadas anotaciones de desencadenantes. Por ejemplo, en el siguiente mensaje sobre una obstrucción del tráfico: A1 entre Köln-Mühlheim y Köln-Dellbrück, objetos en la carretera, ambas direcciones cerradas. Según (Consortium, 2005), «cerrado» desencadena el evento, pero no proporciona información específica del mismo. Los atributos asignados a dichos desencadenantes construyen relaciones de eventos. El papel central de la anotación de desencadenantes da lugar a requisitos de alta calidad y a un mayor esfuerzo de anotación.
Esta investigación presenta la extracción de relaciones multiattributo (MARE), una nueva definición del problema que tiene como objetivo simplificar los enfoques de extracción de relaciones en la práctica. Relaciones multiattributo:
- disponer de un conjunto bien definido de posibles funciones para los atributos,
- no dar nada por sentado respecto a la multiplicidad de los atributos al crear una instancia de relación, y
- No te fíes del concepto de «desencadenante», que indica la presencia de una relación.
Presentamos un enfoque basado en el etiquetado de secuencias y el etiquetado de intervalos para reconocer entidades y extraer relaciones con múltiples atributos entre ellas en un modelo conjunto. Analizamos el rendimiento de nuestros enfoques en el corpus Smart-Data (Schiersch et al., 2018). Este corpus es el único recurso disponible para la extracción de relaciones en textos en alemán. Las anotaciones de este corpus incluyen entidades nombradas y relaciones con múltiples atributos entre ellas. Publicamos todos los datos y el código fuente relacionados con la investigación en un repositorio de GitHub¹. Nuestras principales contribuciones se pueden resumir de la siguiente manera:
- Formalizamos la extracción de relaciones con múltiples atributos e introducimos dos enfoques específicos para este problema.
- Demostramos que los enfoques que no se basan en disparadores obtienen, en general, mejores resultados con las relaciones multiatributo del corpus SmartData.
- Presentamos la primera evaluación reproducible de un método de extracción de relaciones no binarias en un corpus en alemán.
¹https://github.com/MSLars/mare
2. Trabajos relacionados
La extracción de relaciones analiza la relación mutua entre entidades nombradas en los textos con el fin de transferir la información no estructurada a esquemas predefinidos. La mayoría de los conjuntos de datos de referencia solo tienen en cuenta las relaciones binarias (Mintz et al., 2009; Hendrickx et al., 2010).
Los enfoques tradicionales de extracción de relaciones binarias utilizan el etiquetado de partes del discurso, el análisis sintáctico de dependencias y otros pasos para calcular representaciones de entrada para los modelos de aprendizaje automático (Xu et al., 2013). Los modelos de vanguardia actuales utilizan redes transformadoras para calcular representaciones altamente contextualizadas de las relaciones binarias candidatas y las combinan con capas de decisión especializadas en una red neuronal combinada (Li y Tian, 2020; Eberts y Ulges, 2019).
Como ampliación de la extracción de relaciones binarias, el campo de la extracción de relaciones n-arias tiene como objetivo detectar relaciones con un número fijo de n argumentos. (Peng et al., 2017) ampliaron las redes neuronales recurrentes para incluir de manera eficiente los enlaces de dependencia sintáctica con el fin de construir representaciones contextualizadas de las relaciones. (Lai y Lu, 2021) presentaron un enfoque basado en transformadores para la misma configuración experimental. Ambos se centran en las relaciones ternarias.
Los métodos de extracción de relaciones binarias y de n-arios reducidos suelen enumerar conjuntos de entidades previstas como punto de partida para generar candidatos a relaciones. Nosotros extraemos relaciones con un número arbitrario de atributos, evitando dicha enumeración para prevenir una explosión combinatoria.
Para ampliar la restricción de tamaño fijo, el campo de la extracción de eventos define los eventos como relaciones de múltiples atributos con un atributo desencadenante necesario. El desencadenante indica la presencia de un evento. Se pueden asignar otras entidades a un único desencadenante para formar relaciones de eventos (Consortium, 2005; Aguilar et al., 2014). Los enfoques de extracción de eventos se basan en estas anotaciones de desencadenantes (Xiang y Wang, 2019). Todas las entidades asignadas a un desencadenante forman una relación multiattributo. Esto reduce el problema a una secuencia de clasificaciones de relaciones binarias.
Tradicionalmente, los sistemas de extracción de relaciones del mundo real extraen entidades y sus relaciones en una cadena de procesamiento. Estos sistemas adolecen de la propagación de errores. El campo de la extracción conjunta de relaciones investiga modelos que extraen entidades y relaciones en un único modelo. Una forma habitual de construir un modelo conjunto consiste en compartir la capa de incrustación entre varias tareas posteriores. (Wadden et al., 2019) introdujeron un sistema que comparte incrustaciones para extraer entidades nombradas, construye candidatos a relaciones binarias y clasifica la relación entre ellos. (Zheng et al., 2017; Liu et al., 2019) introducen esquemas de etiquetado de secuencias para extraer explícitamente atributos y sus relaciones en un único paso de clasificación. Nuestros modelos extraen de manera similar estructuras más complejas sin una enumeración de candidatos de relación. Esto evita una explosión combinatoria para MARE. Aplicamos una novedosa red transformadora para recibir incrustaciones de texto contextualizadas (Devlin et al., 2019; Clark et al., 2020).
(Schiersch et al., 2018) presentaron el corpus Smart-Data para la extracción de relaciones en textos en alemán. Las relaciones anotadas contienen un número variable de argumentos obligatorios y opcionales. En la sección 3 se analiza el corpus con gran detalle. El artículo original incluye los resultados del sistema de extracción de relaciones DARE (Xu et al., 2013). Esta evaluación solo tiene en cuenta los roles de atributos obligatorios para cada relación. También tenemos en cuenta los atributos opcionales y analizamos los resultados en un contexto problemático más complejo. (Roller et al., 2018) investiga la extracción de entidades nombradas y relaciones binarias a partir de informes clínicos en alemán. Su corpus no ha sido publicado.
3. Análisis de datos
Entrenamos y evaluamos nuestros modelos en el corpus Smart-Data2 (Schiersch et al., 2018), un corpus en alemán facilitado por el DFKI3. El corpus contiene entidades y relaciones relacionadas con el tráfico y la industria, anotadas manualmente, procedentes de noticias, fuentes RSS y tuits.
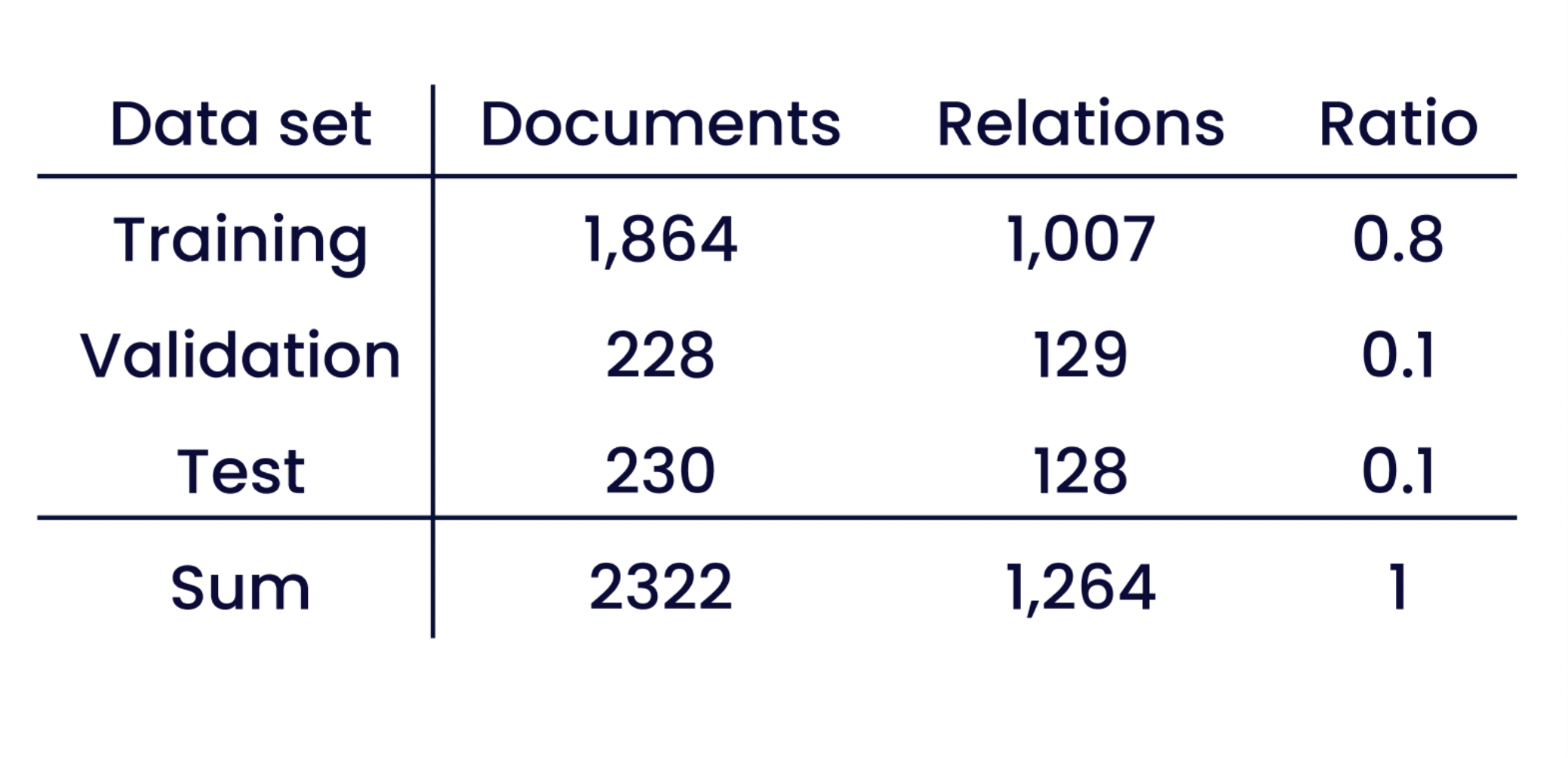
La tercera versión del corpus contiene 19 116 entidades y 1 264 relaciones repartidas en 2 322 documentos, con un total de 141 344 palabras⁴. La tabla 1 muestra la división entre datos de entrenamiento y de prueba facilitada por SmartData.
La concordancia entre anotadores se sitúa en un nivel moderado (Viera et al., 2005), con un coeficiente kappa de Cohen de 0,58 para las entidades y de 0,51 para las relaciones.
Tabla 1: División en conjuntos de entrenamiento y prueba del corpus SmartData, con el número de relaciones y la proporción de documentos en cada subconjunto.
El DFKI describe sus pasos de preprocesamiento en (Schiersch et al., 2018) y en GitHub.
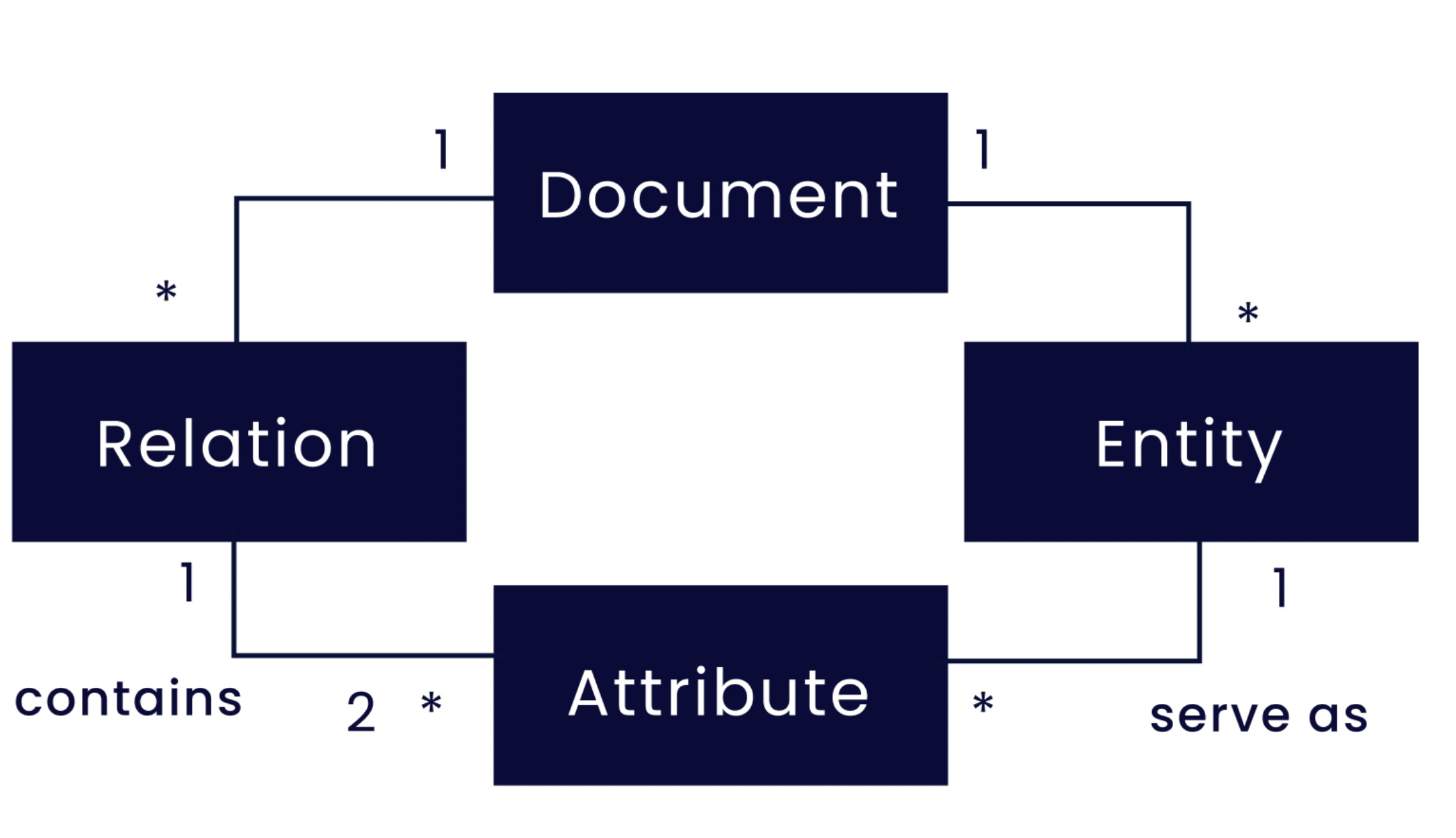
Figura 1: Estructura de las instancias del corpus SmartData. Los documentos contienen relaciones y entidades. Una relación tiene al menos dos atributos obligatorios. Cada atributo tiene una mención de entidad. Las entidades pueden actuar como atributos en ninguna o en varias relaciones. Por ejemplo, la entidad «Ubicación» puede actuar como atributo en «Accidente» y «Obstrucción» al mismo tiempo.
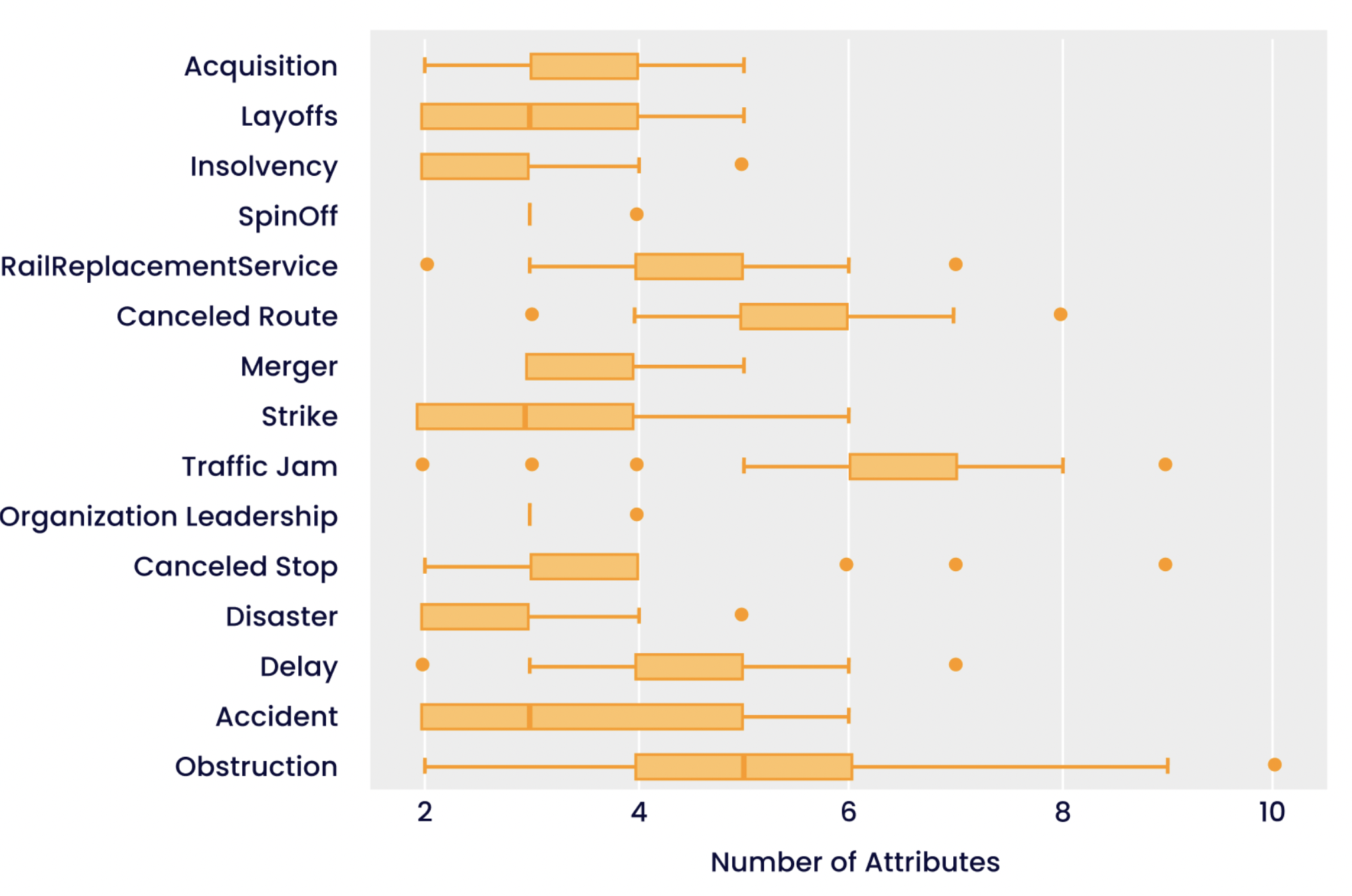
Figura 2: Diagrama de caja que ilustra la distribución del número de atributos por relación. Por ejemplo, el número de atributos de la relación «Obstrucción» oscila entre dos y diez, mientras que otras relaciones, como «Insolvencia», no muestran la misma variación. Los puntos indican valores atípicos.
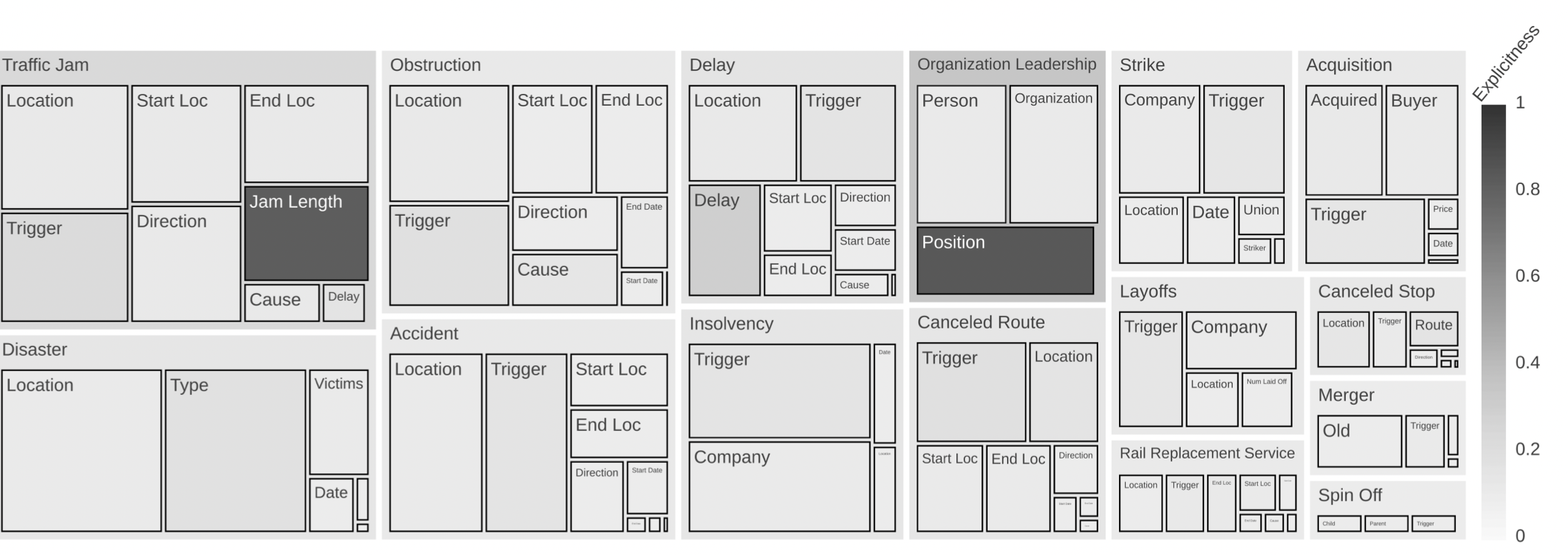
Figura 3: Distribución de relaciones y atributos. El tamaño de los rectángulos es proporcional a la frecuencia de la relación o del atributo. La explicitud es el cociente entre la frecuencia de los atributos y el número total de entidades con un tipo de entidad adecuado para la función específica del atributo. Esta métrica indica el grado de fiabilidad con el que un tipo de entidad indica un atributo de relación.
La figura 1 ilustra el metamodelo de datos. Cabe señalar que una relación puede tener un número variable de atributos y no se limita a un número fijo. A cada función de un atributo puede corresponder un conjunto fijo de tipos de entidad: por ejemplo, tipos de entidad como «Ubicación-Calle», «Ubicación-Ciudad» o «Ubicación-Ruta» pueden utilizarse indistintamente como atributos con la función «Ubicación».
A continuación, explicamos las características principales del corpus SmartData.
Relaciones. El corpus ofrece 15 tipos de relaciones con dos atributos obligatorios y otros opcionales. La figura 3 ilustra la distribución de las relaciones y los atributos.
Entidades. SmartData ofrece 16 tipos de entidades detallados. Para consultar la lista completa, véase (Schiersch et al., 2018). Introducimos la «explicitud» como métrica para demostrar que solo unos pocos tipos de entidades constituyen un indicador sólido de una relación (véase «Duración» o «Posición» en la figura 3). Por ello, los modelos MARE deben aprender una visión combinada de los compuestos de entidades.
Número variable de atributos de relación. Cada relación contiene al menos uno de cada uno de los atributos obligatorios. Pueden contener o no otros atributos opcionales. El ejemplo de «Diferencias discutibles» de la figura 5 muestra una fuente RSS con una relación «Obstrucción». Solo los atributos «trigger» y «location» son obligatorios. «StartLoc» y «EndLoc» son atributos opcionales.
Desequilibrado. Los conjuntos de datos desequilibrados plantean el reto de aprender la estructura esencial tanto para los puntos de datos infrarrepresentados como para los demás puntos de datos más abundantes (Mountassir et al., 2012). El conjunto de datos está desequilibrado tanto en términos de relaciones como de atributos (véase la figura 3): Traffic Jam se produce aproximadamente 10 veces más a menudo que Spin Off. Mientras que las frecuencias de los atributos de Spin Off son bastante similares, los atributos de Traffic Jam muestran una diferencia en la distribución de los atributos, que corresponde a los atributos obligatorios y opcionales.
Desencadenantes inadecuados. En otros corpus de extracción de eventos, los desencadenantes se definen estrictamente como un único token o segmento obligatorio, debido a su papel esencial como indicador de relación (Consortium, 2005; Aguilar et al., 2014). SmartData no sigue estas restricciones: los desencadenantes son opcionales y no están vinculados a tokens consecutivos ni a ningún lema o categoría gramatical específicos. Por lo tanto, este corpus impide la aplicación de los enfoques actuales de extracción de eventos debido a su supuesto de que existe un único token o span desencadenante.
Entidades que comparten relaciones. En un mismo documento pueden darse varias relaciones. Las entidades de las relaciones correspondientes no tienen por qué estar separadas: por ejemplo, es probable que «Atasco» y «Obstáculo» aparezcan juntos y compartan atributos de ubicación.
Diferentes registros lingüísticos. SmartData utiliza diversas fuentes de datos, lo que da lugar a diferentes distribuciones y patrones que los modelos deben aprender. Mientras que los artículos de prensa son textos continuos y gramaticalmente completos, las publicaciones de Twitter y los canales RSS suelen consistir en fragmentos de frases.
El corpus SmartData ofrece relaciones con un número variable de atributos y sin una definición de desencadenantes regular, lo que hace que el corpus se ajuste a la definición de MARE. Es necesario realizar modificaciones para aplicar los enfoques actuales de extracción de relaciones o eventos.
2 https://github.com/DFKI-NLP/smartdata-corpus
3 Centro Alemán de Investigación en Inteligencia Artificial (Traducción: German Research Center for Artificial Intelligence)
4 Las cifras difieren de las del artículo original debido a las diferentes versiones
4. GRANDE
En esta sección se presenta formalmente el concepto de extracción de relaciones multiattributo y se describen dos enfoques MARE. Describimos nuestra metodología de evaluación, que incluye la adaptación de un enfoque de extracción de eventos y relaciones binarias. Comparamos ambos enfoques con los enfoques MARE.
4.1 Definición
Para un texto determinado t = (t₁, …, t_n) con n fichas,
S = {(ti,…,tj) | para todo i, j ∈ {1,…,n}, i ≤ j}
denota el conjunto de todos los fragmentos de texto. Sea L un conjunto de etiquetas de relaciones y Al un conjunto de roles de atributos para cada etiqueta de relación l ∈ L. La tarea consiste en predecir un conjunto de relaciones R para un texto dado t. Cada instancia de relación r ∈ R
r = (l, {αi | para todo i ∈ {1,…,m}})
consta de una etiqueta de relación l y un número variable de
0 < m ≤ |S| atributos
αi = (s,a) ∈ S×Al para todo i ∈ {1,…,m}.
Cada fragmento s ∈ S puede contribuir como máximo a un atributo en cada relación r ∈ R. Sin embargo, un fragmento puede contribuir a atributos de varias relaciones. Permitimos explícitamente las relaciones con un solo atributo. Denotamos los fragmentos de texto s_(ij) con i e j como índices de inicio y fin. Además,
A = ∪ₐ∈L Lₐ
es el conjunto de todas las funciones de los atributos.
La definición formal no distingue entre atributos obligatorios y opcionales, tal y como se indica en la sección 3. No obstante, seguimos utilizando esta distinción para la evaluación del modelo, ya que una mayor frecuencia de un rol de atributo implica un mejor rendimiento en la extracción.
4.2 Enfoques
Todos los enfoques, salvo los de referencia, utilizan redes Transformer como generadores de representaciones contextualizadas. Dichas redes calculan representaciones contextualizadas mediante una combinación de múltiples capas de autoatención y de propagación hacia adelante. Se entrenan de forma no supervisada (Devlin et al., 2019). Aplicamos una versión en alemán de ELECTRA5 (May y Reißel, 2020). Sus tareas de preentrenamiento se centran en la capacidad de los modelos para describir la estructura semántica de los textos (Clark et al., 2020). Todos los enfoques utilizan la versión del algoritmo de optimización Adam con decaimiento de pesos introducida en (Loshchilov y Hutter, 2019).
A continuación, utilizamos las definiciones presentadas en la sección 4.1.
4.2.1 Etiquetado de secuencias
El número desconocido de atributos en MARE exige el uso de modelos que no tengan que enumerar todas las relaciones candidatas. (Zheng et al., 2017) introdujeron un esquema de etiquetado para formular la extracción de relaciones binarias como un problema de etiquetado de secuencias.
T = {b, i} × L × A ∪ {o}
describe nuestro conjunto de etiquetas. Las etiquetas que comienzan por «b» e «i» marcan los tokens como el inicio o la parte interna de una entidad. Para los intervalos de entidad resultantes, la etiqueta «l ∈ L» determina la relación, y «a ∈ Al» determina la función de atributo para una relación determinada por «l». «o» marca los tokens que no pertenecen a ningún atributo.
De cada secuencia de tokens etiquetados, extraemos un conjunto de atributos de relaciones incoherentes. Estos atributos se resumen en instancias de relación según su etiqueta de relación.
La secuencia de entrada incrustada y contextualizada se utiliza como entrada para una capa de propagación hacia adelante, que la mapea a probabilidades de etiquetas. Un campo aleatorio condicional determina la pérdida y la secuencia de etiquetas más probable. (Huang et al., 2015) describe los detalles de los campos aleatorios condicionales para el etiquetado de secuencias.
Nuestro modelo de etiquetado de secuencias evita tener que enumerar todas las posibles relaciones candidatas. Sin embargo, esto también conlleva las dos limitaciones siguientes:
1. Atributos compartidos entre relaciones. Varias relaciones pueden tener atributos con fragmentos de texto compartidos. Nuestro esquema de etiquetado solo puede asignar cada fragmento a una relación como máximo.
2. Varias relaciones con la misma etiqueta. Una muestra puede tener varias relaciones con la misma etiqueta de relación. Por ejemplo, dos descripciones de accidentes en una misma muestra. Agruparlas en función de la etiqueta da lugar a una única relación, en lugar de a varias instancias.
Introducimos una capa de lógica de negocio para gestionar este tipo de situaciones. En el caso de que un atributo se extienda a través de varias relaciones, comprobamos si a las relaciones actuales les falta algún atributo obligatorio. Si es así, buscamos tipos de atributos que indiquen argumentos compartidos. Si dicho atributo se encuentra dentro de la anchura máxima de la relación⁶, lo utilizamos para completar la relación.
A continuación, suponemos que los atributos de las relaciones están ordenados según sus índices de extensión. Para gestionar varias relaciones con la misma etiqueta en una muestra, dividimos una relación agrupada α1,…,αn en un índice i < n si los subconjuntos α1,…,αi y αi+1,…,αn contienen todos los atributos obligatorios y la distancia entre αi y αi+1 supera la anchura máxima de la relación.
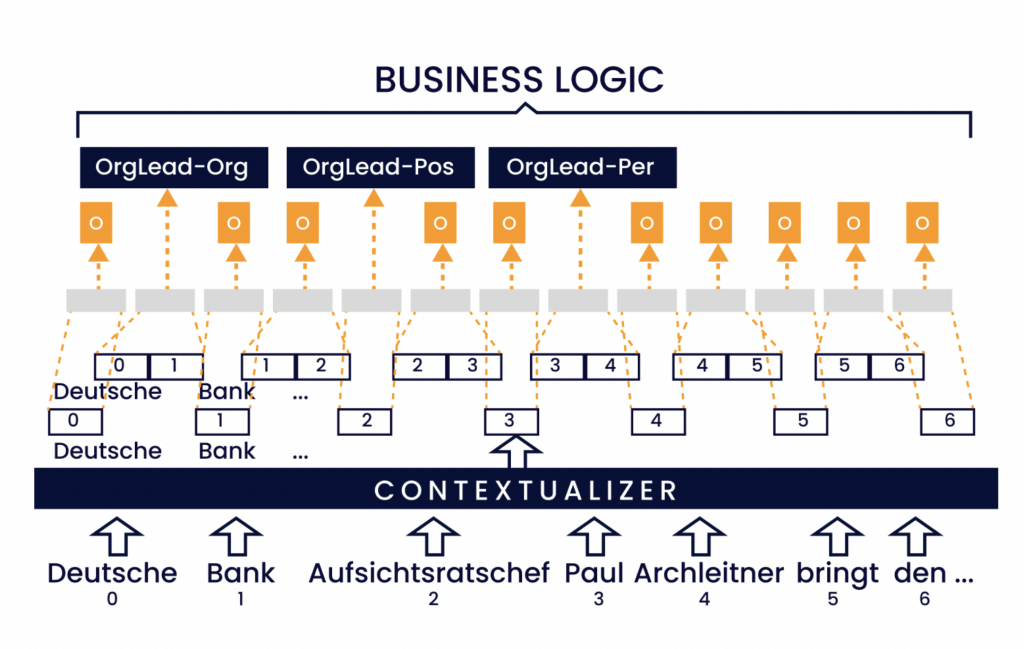
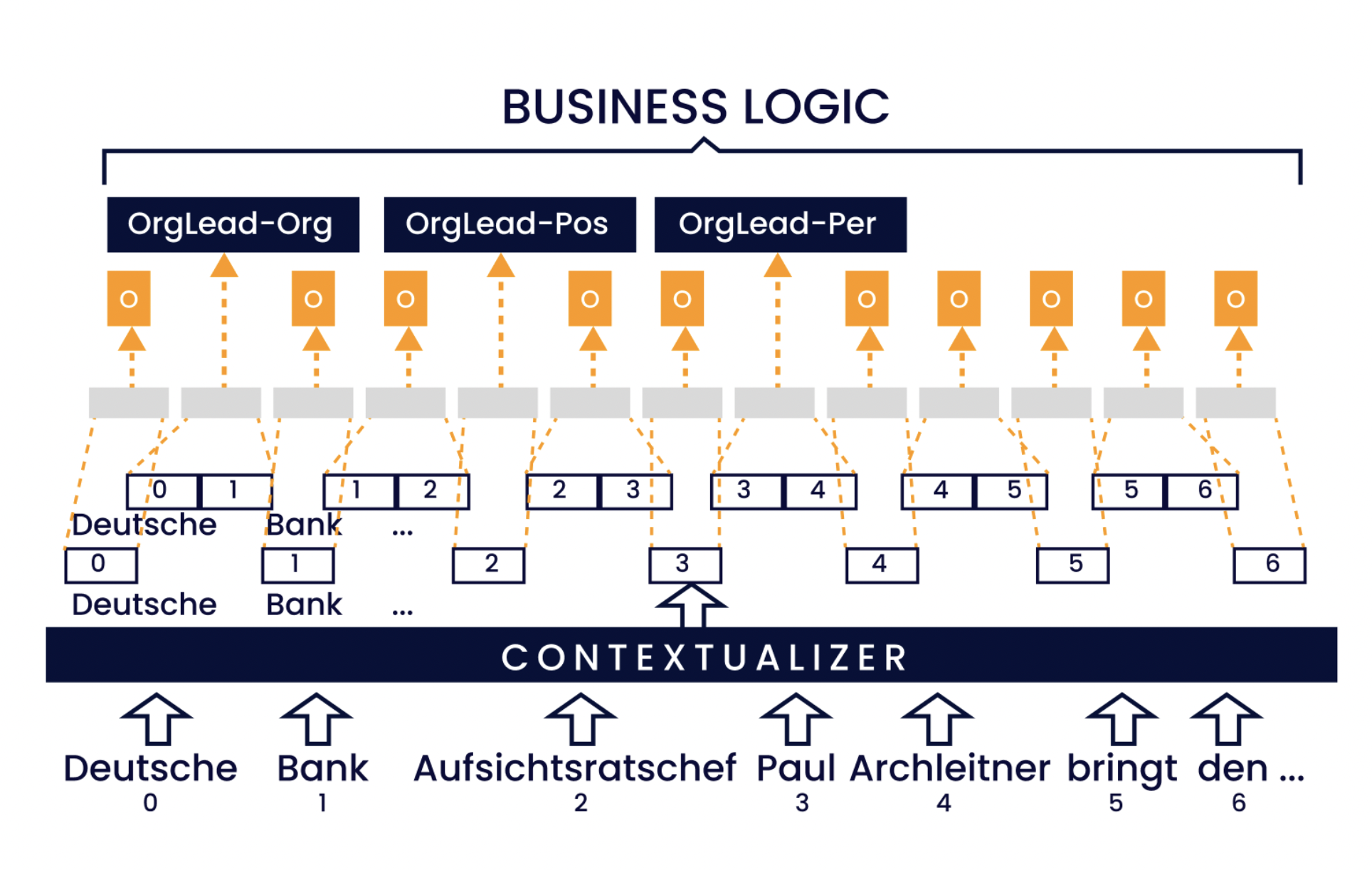
Figura 4: Ilustración del método de etiquetado de fragmentos. La secuencia de entrada se integra y se contextualiza. Cada fragmento de texto, dentro de un ancho máximo de fragmento (2 en este ejemplo), se transforma en una representación de longitud fija etiquetada con una combinación de etiqueta de relación y rol de argumento. Por último, la lógica de negocio agrupa los atributos a las relaciones.
4.2.2 Etiquetado de tramos
Nuestro segundo enfoque se inspira en (Liu et al., 2019). Estos autores aplicaron un método de etiquetado de secuencias en lugar del etiquetado de secuencias. El etiquetado permite asignar varias etiquetas de atributos a cada fragmento de texto. Modificamos este enfoque y predecimos una etiqueta de atributo de relación para cada fragmento de texto posible en una muestra dada. Al igual que nuestro enfoque de etiquetado de secuencias, este método no requiere enumerar todas las relaciones candidatas y resuelve la limitación que supone la coincidencia de atributos entre relaciones.
Sea T = L×A un conjunto de etiquetas que indican la etiqueta de relación y la función del atributo para un fragmento de texto dado. El modelo predice una probabilidad P(t|s) para cada etiqueta t ∈ T y cada fragmento s ∈ S. Un hiperparámetro de anchura máxima de fragmento define el número máximo de tokens por fragmento en S. Aplicamos una función de pérdida de entropía cruzada binaria, que permite asignar varias etiquetas por fragmento.
La figura 4 ilustra la arquitectura de nuestro modelo. Las representaciones de los intervalos se calculan mediante un módulo basado en autoatención de AllenNLP7. Para un texto dado de longitud n, calculamos incrustaciones contextualizadas (c1,…,cn) de dimensión d. Para cada intervalo sij, disponemos de j−i+1 incrustaciones (ci,…,cj). Para obtener una representación de intervalo de longitud fija de dimensión d, calculamos una combinación lineal de estas incrustaciones. Una matriz de parámetros M ∈ Rd×1 calcula puntuaciones de atención global ai = ci ·M para todo i ∈ {1,…,n}. Estas se utilizan para calcular los pesos wi,…,wj para un intervalo sij, con
punta
wk = a para todo k en {i,…,j}.
La suma de los números enteros desde i hasta j es
La función softmax garantiza que la suma de los pesos de cada span sea igual a 1. Las representaciones finales de los spans son una combinación lineal de estos pesos y las incrustaciones.
Una capa de propagación hacia adelante, en combinación con la función sigmoide elemento por elemento, calcula las probabilidades de etiqueta para cada intervalo. Al igual que en el enfoque anterior, esto da lugar a un conjunto de instancias de relaciones agrupadas. Aplicamos la misma lógica de negocio que en la sección 4.2.1, ya que sigue existiendo la limitación de que varias relaciones puedan tener la misma etiqueta.
4.2.3 Extracción de eventos
Para aplicar métodos de extracción de eventos, debemos especificar un desencadenante de evento para cada relación multiattributo. Como se muestra en la sección 3, algunas instancias en el
El corpus SmartData no contiene este tipo de anotaciones. Si la definición de una relación no incluye un atributo de activador obligatorio, hemos definido un tipo de atributo obligatorio para cada relación como activador. En el caso de que haya varios intervalos de activación no conjuntos, seleccionamos el primer intervalo como activador. No aplicamos una lógica más compleja, ya que el conjunto de relaciones con múltiples desencadenantes (78 de 1264) es relativamente pequeño. La primera situación de error de la sección 4.2.1 queda sin resolver si las relaciones comparten desencadenantes. Otros atributos pueden compartirse entre relaciones.
Utilizamos Dygie++⁸ como método de extracción de eventos. Tal y como describen (Wadden et al., 2019), Dygie++ emplea representaciones de fragmentos contextualizadas, similares a las de la sección 4.2.2. La detección de desencadenantes y la desambiguación de atributos utilizan estas representaciones de fragmentos compartidas.
4.2.4 Extracción de relaciones binarias
Muchos enfoques de extracción de relaciones binarias clasifican todos los pares posibles de entidades como candidatos a relaciones, como es el caso de SpERT (Eberts y Ulges, 2019). En combinación con el etiquetado multiclase, esto resuelve las dos situaciones de error descritas en la sección 4.2.1.
Aplicamos SpERT para extraer relaciones binarias de 1.717 de las 1.864 muestras del conjunto de entrenamiento que contienen relaciones con exactamente dos atributos obligatorios. En la siguiente sección se presentan diversas estrategias de evaluación. Presentamos una estrategia de extracción de relaciones binarias para comparar el rendimiento de SpERT con el de todos los demás enfoques en el subconjunto de relaciones binarias válidas.
4.3 Configuración experimental
Utilizamos AllenNLP (Gardner et al., 2017) y PyTorch para implementar el método de etiquetado de secuencias y de marcaje de intervalos. Nuestro repositorio de GitHub contiene versiones modificadas de Dygie++ y SpERT. Estas modificaciones fueron necesarias para integrar ambos métodos en nuestra infraestructura experimental.
Nuestro repositorio de GitHub contiene un resumen de todos los hiperparámetros y sus valores en los modelos finales. Todos los hiperparámetros se determinaron con Optuna9. Aplicamos 50 iteraciones de optimización para cada modelo. Fijamos la tasa de aprendizaje de la capa de incrustación de la red transformadora en 5 · 10−5 y en 10−3 para el resto de componentes de la red. Seleccionamos un tamaño de lote de 6 para todos los enfoques MARE, y para SpERT y Dygie++ un tamaño de lote de 1.
Utilizamos diversas estrategias de evaluación para analizar las predicciones. El objetivo de estas estrategias es reflejar los retos que plantea MARE en distintos niveles de complejidad.
• Reconocimiento de atributos (AR): la evaluación se realiza por atributos. Se considera que un atributo es correcto si se predicen correctamente sus límites, la etiqueta de la relación y la función del atributo, sin tener en cuenta la agrupación en una relación.
• Clasificación (Cl): una predicción es correcta si la etiqueta predicha coincide con la etiqueta de referencia.
• Extracción de relaciones obligatorias (MRE): una predicción se considera correcta si todos los atributos obligatorios y la etiqueta de la relación coinciden con la anotación de referencia. Por lo tanto, es fundamental agrupar los atributos obligatorios en una sola relación.
• La extracción completa de relaciones (CRE) mide la capacidad del modelo para extraer la relación con todos los atributos en su conjunto. Por lo tanto, una predicción se considera correcta si el modelo extrae todos los atributos y los agrupa correctamente en una relación con la etiqueta de relación adecuada.
• Extracción de relaciones binarias (BRE): se trata de la estrategia MRE aplicada al subconjunto de muestras que contiene únicamente relaciones con exactamente dos argumentos obligatorios. Esta estrategia permite comparar SpERT con todos los demás enfoques.
Incluimos el modelo de referencia (DARE) de (Schiersch et al., 2018), que se centra en los argumentos obligatorios y utiliza anotaciones de entidades de referencia. Nuestro propio modelo de referencia es una modificación del enfoque de etiquetado de secuencias. Sustituimos la red Transformer preentrenada por una combinación de vectores de palabras GloVe10 (Pennington et al., 2014) y una CNN a nivel de caracteres como capa de incrustación. Una capa Bi-GRU contextualiza las entradas.
Nuestra configuración informática consta de dos nodos con procesadores Intel Xeon Platinum 8168, tarjetas gráficas Nvidia Quadro P5000 con 16 GB de RAM y el sistema operativo Ubuntu 18.04. La búsqueda de hiperparámetros duró aproximadamente 24 horas.
5 https://huggingface.co/german-nlp-group/ electra-base-german-uncased
6 El ancho máximo de la relación es un hiperparámetro y se determina mediante una búsqueda de hiperparámetros. El repositorio de GitHub contiene la configuración de la búsqueda y los valores finales.
7 http://docs.allennlp.org/main/api/modules/ extractores de intervalos/extractor de intervalos autónomo/
8 https://github.com/dwadden/dygiepp
9 https://optuna.org/
5. Resultados
Los indicadores de la tabla 2 miden las distintas capacidades necesarias para extraer todos los atributos, sus funciones y la etiqueta de relación de forma conjunta. En general, a medida que aumentan los requisitos de los indicadores, sus valores disminuyen.
El enfoque de etiquetado de intervalos aumenta los resultados de AR en la extracción de eventos en 0,06 y los de Cl en 0,04 en las puntuaciones F1. Observamos que ambos enfoques MARE obtienen mejores resultados que Dygie++ en el conjunto de datos completo. La puntuación MRE similar y el aumento de las puntuaciones AR y CRE indican que los modelos MARE extraen los argumentos opcionales y potencialmente menos frecuentes de forma más fiable. Una reducción al subconjunto de documentos con exactamente dos argumentos obligatorios conduce a puntuaciones generales más altas, pero a un aumento mucho mayor para Dygie++ que para los modelos MARE. Ambas observaciones indican que las arquitecturas de modelo con menos supuestos estructurales se adaptan mejor a las características únicas del corpus, tal y como se describe en la sección 3.
Tabla 2: Evaluación del modelo en el conjunto de prueba basándose en diferentes estrategias; véase la sección 4.3. La precisión, el recall y el índice F1 sirven como métricas de comparación.
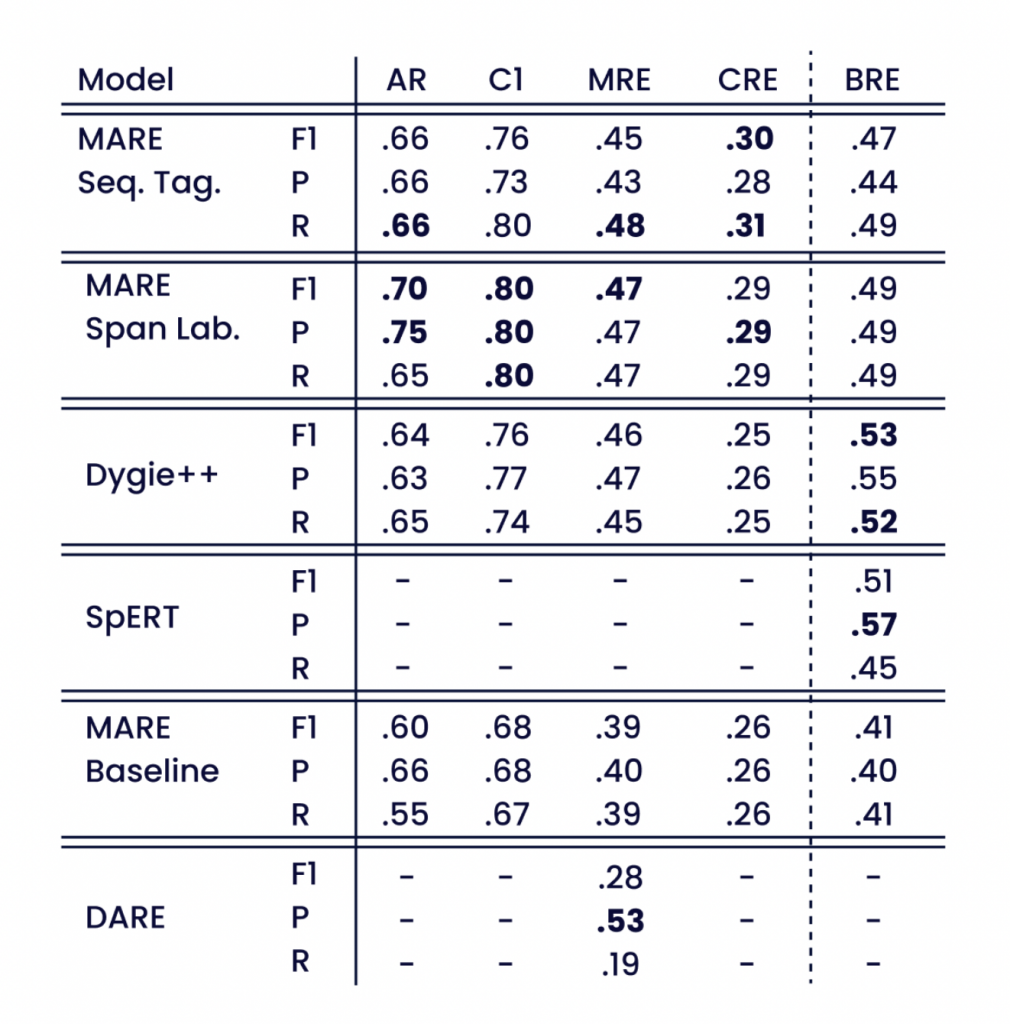
La diferencia entre la referencia MARE y los dos enfoques MARE pone de manifiesto el efecto positivo de las redes Transformer preentrenadas. A pesar del rendimiento generalmente inferior de DARE, que utiliza un conjunto de reglas seleccionado automáticamente, la referencia original presenta la puntuación de precisión MRE más alta. Esto indica una gran fiabilidad en las relaciones extraídas y un elevado número de falsos negativos debido a la baja puntuación de recuperación.
La evaluación de SpERT muestra una clara mejora con respecto a nuestro modelo de referencia MARE. SpERT también obtiene mejores resultados que nuestros modelos MARE en BRE.
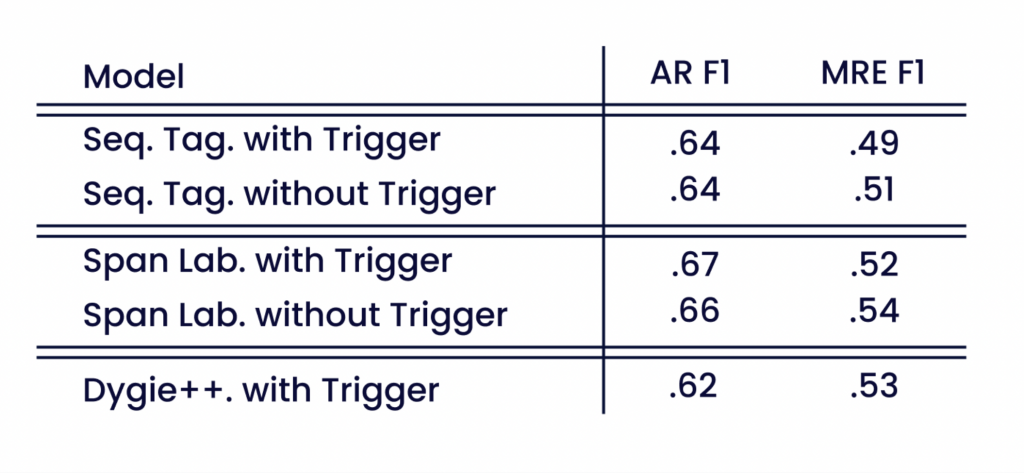
La tabla 3 muestra cómo las anotaciones de desencadenantes afectan al rendimiento de los modelos MARE. Las evaluaciones realizadas en el conjunto reducido de atributos no desencadenantes de los modelos MARE, entrenados tanto con como sin anotaciones de desencadenantes, no muestran una diferencia significativa en las puntuaciones de AR y MRE. El rendimiento de nuestros modelos sin anotaciones de desencadenantes es comparable al de la extracción de eventos de vanguardia en relaciones multiattributo del corpus Smart-Data. La puntuación AR de los modelos MARE es mejor que la de Dygie++. Esto demuestra la capacidad de MARE para extraer atributos opcionales y menos frecuentes.
En comparación con la tabla 2, las puntuaciones de AR disminuyen, lo que indica que los modelos extraen los atributos desencadenantes de forma fiable. Sin los atributos desencadenantes, persisten muchas relaciones de un solo atributo. Esto simplifica la tarea de MRE y da lugar a un aumento de las puntuaciones de MRE.
Dado que la extracción de relaciones es una tarea de alto nivel semántico y que las anotaciones de referencia de SmartData presentan cierto grado de inconsistencia, llevamos a cabo un análisis manual de los errores para comprender mejor las características de predicción de nuestros modelos.
5.1 Comprobación de errores
Hemos llevado a cabo una comparación manual de las diferencias entre las anotaciones de referencia y las predicciones de los modelos. De nuestra revisión manual se desprenden las siguientes clases de equivalencia de errores. Todos los ejemplos mencionados en la siguiente enumeración se refieren a la figura 5.
1. Diferencias discutibles Las predicciones de los modelos suelen ser razonables, incluso cuando los datos de referencia contienen anotaciones divergentes. El ejemplo muestra una relación de «obstáculo», en la que la maratón representa la «causa del obstáculo». La anotación de referencia no refleja esta circunstancia. Las diferencias discutibles indican que nuestros modelos han aprendido ciertos conceptos semánticos. Algunas generalizaciones en las predicciones dan lugar a falsos positivos, lo que reduce las métricas de evaluación.
2. Clases de relaciones con dependencia semántica. Algunas clases de relaciones, como «Accidente» y «Obstrucción», presentan una fuerte relación semántica. Por lo tanto, las instancias de estas relaciones suelen estar anidadas y comparten intervalos de entidad como atributos. Las anotaciones de estos atributos compartidos suelen ser defectuosas. El ejemplo muestra una Obstrucción causada por un Desastre. La anotación de referencia contiene dos relaciones separadas y no expresa esta dependencia. El desencadenante del Desastre también podría interpretarse como la causa de la Obstrucción. Esta distinción supone un reto para los modelos.
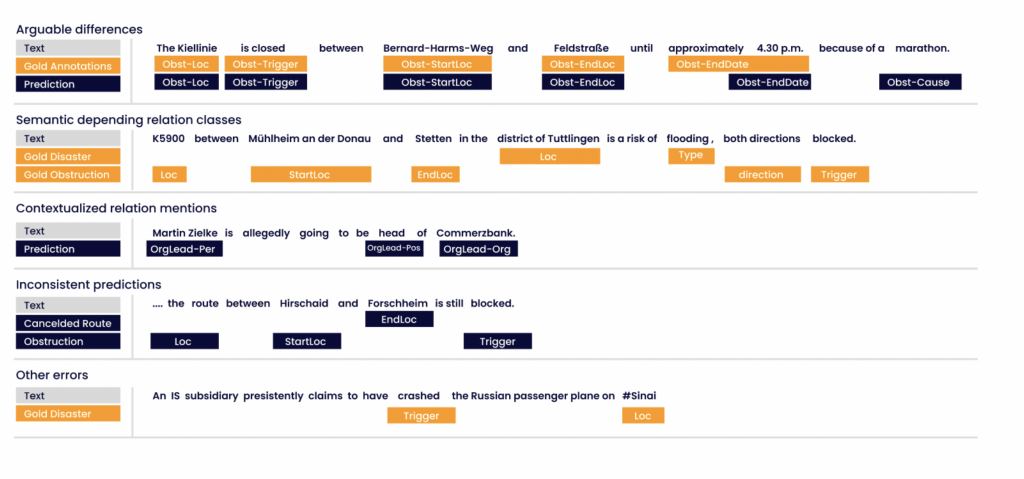
Figura 5: Ejemplos de clases de error. Los recuadros de colores indican las relaciones y sus atributos. El atributo «role» se ha anotado textualmente. Predicciones realizadas mediante el método de etiquetado de intervalos.
3. Menciones de relaciones contextualizadas: Muchas de las supuestas instancias de relación aparecen en un contexto de presunción. Palabras como «supuestamente» indican suposiciones más que hechos. El ejemplo muestra una presunción sobre el liderazgo de una organización. En muchos de estos casos, los modelos predijeron instancias de relación.
4. Predicciones incoherentes El ejemplo muestra una relación de «Obstrucción», en la que el modelo predijo todos los roles correctamente. La etiqueta de la relación correspondiente a la «Ubicación final» pertenece a una relación semántica similar. Si los atributos que faltan no son obligatorios, la lógica de negocio no puede resolver este tipo de situaciones.
5. Otros errores: los modelos no reconocen muchas relaciones. A menudo, estos errores se producen en oraciones con una estructura gramatical menos definida y en oraciones que contienen muchos caracteres especiales, como «@» o «#», o frases clave típicas que no pertenecen a ninguna relación. El ejemplo muestra un desastre que ningún modelo predijo.
Los resultados indican que los enfoques actuales de extracción de eventos o relaciones binarias superan a los modelos MARE en la tarea de extracción de relaciones binarias. Sin embargo, a medida que reducimos los requisitos estructurales, los modelos MARE pasan a ser superiores. Los enfoques MARE presentados permiten extraer relaciones complejas con múltiples atributos a partir de texto sin formato, sin necesidad de enumerar todas las relaciones candidatas. Las limitaciones de nuestros enfoques, que se describen en la sección 4.2, no tuvieron un impacto significativo en el corpus de datos inteligentes.
10 https://deepset.ai/german-word-embeddings
6. Conclusión
Hemos introducido la extracción de relaciones con múltiples atributos y hemos diferenciado esta definición de la terminología actual, conocida como «extracción de relaciones n-arias» y «extracción de eventos». Nuestra definición del problema da lugar a enfoques simplificados para extraer relaciones con un número arbitrario de atributos, al evitar el uso de la enumeración de candidatos y el concepto de «desencadenante».
Los modelos MARE resultan más adecuados cuando las relaciones no se ajustan a esquemas binarios o de eventos. Evitan las restricciones estructurales y ofrecen mejores resultados que los métodos de extracción de relaciones y eventos más avanzados actualmente en el corpus SmartData.
Tenemos previsto incorporar los resultados del análisis manual en el desarrollo de enfoques MARE mejorados en el futuro. Nuestro principal objetivo es abordar las limitaciones que presentan los enfoques MARE e integrar el contexto específico de cada relación.
7. Referencias
Aguilar, J., Beller, C., McNamee, P., Van Durme, B., Strassel, S., Song, Z. y Ellis, J. (2014). Una comparación de los eventos y relaciones en los estándares de anotación ACE, ERE, TAC-KBP y FrameNet. En Actas del Segundo Taller sobre EVENTOS: Definición, Detección, Coreferencia y Representación, páginas 45–53, Baltimore, Maryland, EE. UU. Asociación de Lingüística Computacional.
Clark, K., Luong, M.-T., Le, Q. V. y Manning, C. D. (2020). ELECTRA: Preentrenamiento de codificadores de texto como discriminadores en lugar de generadores. arXiv:2003.10555 [cs]. arXiv: 2003.10555.
Consortium, L. D. (2005). Ace (extracción automática de contenido): directrices de anotación en inglés para eventos. Página 77.
Devlin, J., Chang, M.-W., Lee, K. y Toutanova, K. (2019). BERT: Preentrenamiento de transformadores bidireccionales profundos para la comprensión del lenguaje. arXiv:1810.04805 [cs]. arXiv: 1810.04805.
Eberts, M. y Ulges, A. (2019). Extracción conjunta de entidades y relaciones basada en intervalos con preentrenamiento de Transformer. arXiv:1909.07755 [cs]. arXiv: 1909.07755.
Gardner, M., Grus, J., Neumann, M., Tafjord, O., Dasigi, P., Liu, N. F., Peters, M., Schmitz, M. y Zettlemoyer, L. S. (2017). Allennlp: una plataforma de procesamiento semántico profundo del lenguaje natural.
Hendrickx, I., Kim, S. N., Kozareva, Z., Nakov, P., Ó Seághdha, D., Pado, S., Pennacchiotti, M., Romano, L. y Szpakowicz, S. (2010). SemEval-2010 Tarea 8: Clasificación multidireccional de relaciones semánticas entre pares de nominales. En Actas del 5.º Taller Internacional sobre Evaluación Semántica, páginas 33–38, Uppsala, Suecia. Asociación de Lingüística Computacional.
Huang, Z., Xu, W. y Yu, K. (2015). Modelos bidireccionales LSTM-CRF para el etiquetado de secuencias. arXiv:1508.01991 [cs]. arXiv: 1508.01991.
Kim, J.-D., Pyysalo, S., Ohta, T., Bossy, R., Nguyen, N. y Tsujii, J. (2011a). Resumen de la tarea compartida BioNLP 2011. En Actas del taller BioNLP Shared Task 2011, pp. 1-6, Portland, Oregón, EE. UU. Asociación de Lingüística Computacional.
Kim, J.-D., Wang, Y., Takagi, T. y Yonezawa, A. (2011b). Resumen de la tarea «Genia event» en la BioNLP Shared Task 2011. En Actas del taller BioNLP Shared Task 2011, pp. 7-15, Portland, Oregón, EE. UU. Asociación de Lingüística Computacional.
Lai, P.-T. y Lu, Z. (2021). BERT-GT: Extracción de relaciones n-arias entre oraciones con BERT y Graph Transformer. Bioinformatics.
Li, C. y Tian, Y. (2020). Diseño de modelos de fase posterior para un modelo de lenguaje preentrenado destinado a la tarea de extracción de relaciones. arXiv:2004.03786 [cs]. arXiv: 2004.03786, versión: 1.
Liu, Y., Li, A., Huang, J., Zheng, X., Wang, H., Han, W. y Wang, Z. (2019). «Extracción conjunta de entidades y relaciones basada en la clasificación multietiqueta». En 4.ª Conferencia Internacional IEEE sobre Ciencia de Datos en el Ciberespacio (DSC) de 2019, pp. 106-111.
Loshchilov, I. y Hutter, F. (2019). Regularización por decaimiento de pesos desacoplado. arXiv:1711.05101 [cs, math]. arXiv: 1711.05101.
May, P. y Reißel, P. (2020). German Electra sin caja.
Mintz, M., Bills, S., Snow, R. y Jurafsky, D. (2009). Supervisión a distancia para la extracción de relaciones sin datos etiquetados. En Actas de la Conferencia Conjunta de la 47.ª Reunión Anual de la ACL y la 4.ª Conferencia Internacional Conjunta sobre Procesamiento del Lenguaje Natural de la AFNLP: Volumen 2 – ACL-IJCNLP ’09, volumen 2, página 1003, Suntec, Singapur. Asociación de Lingüística Computacional.
Mountassir, A., Benbrahim, H. y Berrada, I. (2012). Estudio empírico para abordar el problema de los conjuntos de datos desequilibrados en la clasificación de opiniones. En la Conferencia Internacional IEEE de 2012 sobre Sistemas, Hombre y Cibernética (SMC), pp. 3298-3303.
Peng, N., Poon, H., Quirk, C., Toutanova, K. y Yih, W.-t. (2017). «Extracción de relaciones n-arias entre oraciones mediante LSTM de grafos». Transactions of the Association for Computational Linguistics, 5:101-115.
Pennington, J., Socher, R. y Manning, C. (2014). GloVe: Vectores globales para la representación de palabras. En Actas de la Conferencia de 2014 sobre Métodos Empíricos en el Procesamiento del Lenguaje Natural (EMNLP), páginas 1532-1543, Doha, Catar. Asociación de Lingüística Computacional.
Roller, R., Rethmeier, N., Thomas, P., Hübner, M., Uszkoreit, H., Staeck, O., Budde, K., Halleck, F. y Schmidt, D. (2018). Detección de entidades nombradas y relaciones en informes clínicos en alemán. En Rehm, G. y Declerck, T., editores, Tecnologías del lenguaje para los retos de la era digital, Lecture Notes in Computer Science, páginas 146–154, Cham. Springer International Publishing.
Schiersch, M., Mironova, V., Schmitt, M., Thomas, P., Gabryszak, A. y Hennig, L. (2018). Un corpus alemán para el reconocimiento detallado de entidades nombradas y la extracción de relaciones en eventos relacionados con el tráfico y la industria. Página 8.
Tsujii, J., Kim, J.-D. y Pyysalo, S., editores (2011). Actas del taller BioNLP Shared Task 2011, Portland, Oregón, EE. UU. Asociación de Lingüística Computacional.
Viera, A. J., Garrett, J. M., et al. (2005). Comprensión de la concordancia entre observadores: la estadística kappa. Fam Med, 37(5):360–363.
Wadden, D., Wennberg, U., Luan, Y. y Hajishirzi, H. (2019). Extracción de entidades, relaciones y eventos mediante representaciones de intervalos contextualizadas. En Actas de la Conferencia de 2019 sobre Métodos Empíricos en el Procesamiento del Lenguaje Natural y la 9.ª Conferencia Internacional Conjunta sobre Procesamiento del Lenguaje Natural (EMNLP-IJCNLP), páginas 5784-5789, Hong Kong, China. Asociación de Lingüística Computacional.
Xiang, W. y Wang, B. (2019). Estudio sobre la extracción de eventos a partir de textos. IEEE Access, 7:173111–173137. Nombre de la conferencia: IEEE Access.
Xu, F., Uszkoreit, H., Li, H., Adolphs, P. y Cheng, X. (2013). Extracción de relaciones adaptada al dominio para la web semántica.
Zheng, S., Wang, F., Bao, H., Hao, Y., Zhou, P. y Xu, B. (2017). Extracción conjunta de entidades y relaciones basada en un novedoso esquema de etiquetado. arXiv:1706.05075 [cs]. arXiv: 1706.05075.