El avance tecnológico ha revolucionado profundamente la forma de utilizar los ordenadores en los últimos años. Casi ningún otro sector ha transformado tanto la forma de trabajar de las personas. La comunicación digital es eficaz y se da por sentada tanto en el ámbito privado como en el profesional. Los sectores más rezagados se ven perjudicados por sus formas de comunicación obsoletas e invierten en su optimización.
En la actualidad, están muy extendidas las soluciones que permiten la comunicación humana en lenguaje natural entre personas y aquellas que facilitan la comunicación formal de datos entre sistemas informáticos. Las primeras se enmarcan en el ámbito del correo electrónico, las redes sociales y el chat. Muchas empresas reciben a través de los canales descritos anteriormente un gran número de solicitudes de comunicación en lenguaje natural. Hasta ahora, la elevada proporción de texto continuo ha supuesto un obstáculo para la digitalización y ha generado altos costes debido a un procesamiento mayoritariamente manual.
El lenguaje natural se caracteriza, sobre todo, por su gran diversidad, variabilidad y ambigüedad. Estos factores hacen que el procesamiento automatizado mediante métodos clásicos de la informática —como gramáticas, diccionarios o analizadores sintácticos— resulte casi imposible. Por el contrario, las personas tienen una predisposición genética para aprovechar la información del contexto del lenguaje y, de este modo, hacer frente a estos factores.
El ámbito de investigación Procesamiento del lenguaje natural (NLP) estudia la interfaz entre los ordenadores y el lenguaje natural. En principio, en este campo no se intenta implementar algoritmos de resolución basándose únicamente en reglas formuladas de manera operativa (código de programa, etc.). Más bien, las reglas se aprenden a partir de los datos disponibles, lo que da lugar a un modelo estadístico (Aprendizaje automático, ML). Una vez que el modelo estadístico se ha entrenado lo suficiente de esta forma, es posible procesar correctamente, con un alto grado de probabilidad, incluso textos desconocidos. La combinación de reglas creadas manualmente y reglas aprendidas da lugar a un algoritmo eficaz para el procesamiento del lenguaje natural, que sirve de base para múltiples casos de uso.

Los métodos de aprendizaje automático son objeto de investigación desde los años 50. Con el auge del aprendizaje profundo en el procesamiento de imágenes y del lenguaje en la década de 2010, estos métodos se han ido implantando cada vez más en las empresas.
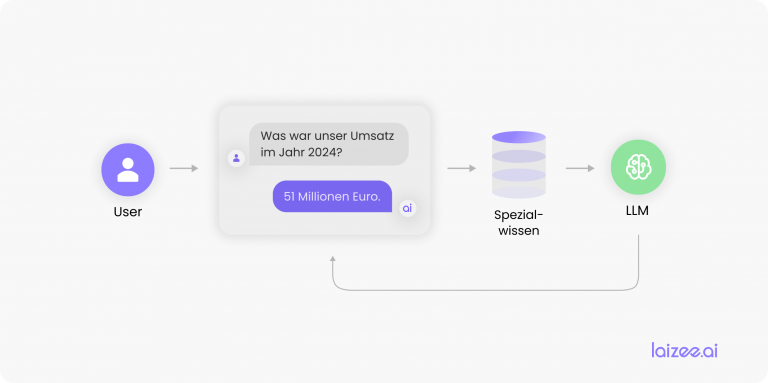
La figura 1 ilustra el proceso de desarrollo de las aplicaciones de PLN. Para obtener un conjunto de datos de entrenamiento lo más representativo y lo suficientemente amplio posible, se lleva a cabo un procesamiento manual (etiquetado) con el fin de crear una solución de referencia. Este conjunto de datos (corpus anotado) constituye la base para el entrenamiento del modelo, es decir, de la distribución estadística. Tras unos pasos de optimización opcionales, el proceso de desarrollo queda completado.
Durante la fase de producción posterior, se analizan textos desconocidos basándose en este modelo. Según la aplicación concreta, se lleva a cabo, por ejemplo, una extracción de información —es decir, la identificación de estructuras semánticas conocidas en el texto— o un análisis del estado de ánimo del autor en el momento de escribir. Visto desde fuera, el modelo entrenado funciona como un empleado humano y puede integrarse en los procesos existentes. El siguiente caso práctico ilustra este proceso.
Caso práctico
Deutsche Bahn, como ejemplo de un gran proveedor de servicios de movilidad, desea mejorar la eficacia de su comunicación con los clientes. Con el fin de aprovechar al máximo el trabajo de su personal de atención al cliente, se pretende dar prioridad a las consultas más habituales, como
«Mi conexión de Aquisgrán a Colonia del próximo miércoles se ha cancelado, ¿qué conexión alternativa puedo utilizar?»
se respondan de forma automática. En primer lugar, cabe señalar que en este ejemplo se mencionan específicamente los parámetros relevantes de la consulta:
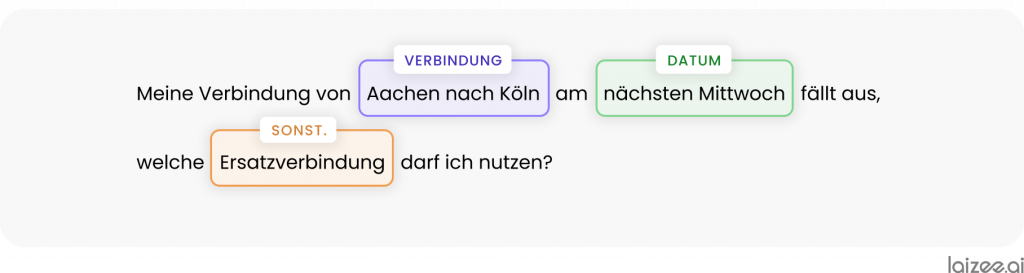
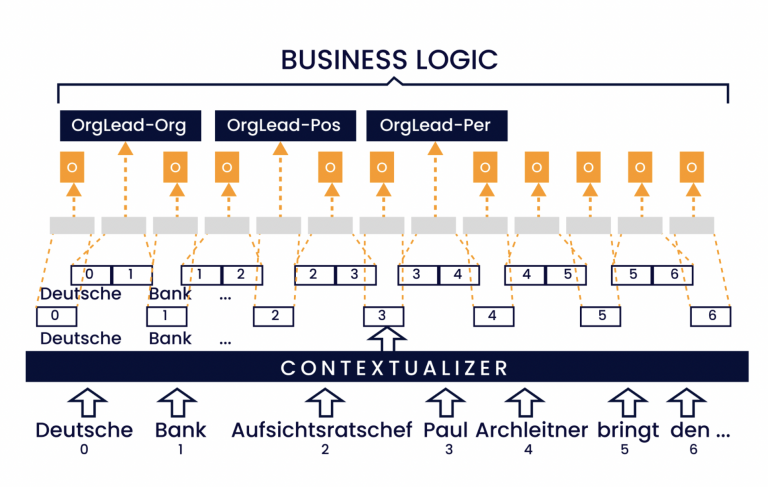
La extracción automatizada de estos conceptos conocidos permite convertir automáticamente la consulta en formato de texto continuo en una consulta estructurada, lo que permite integrarla en los procesos digitales existentes.
Durante el proceso de entrenamiento, estos conceptos se anotan en las consultas de los clientes existentes. Con el conjunto de datos de entrenamiento resultante, se entrena un modelo estadístico de tal manera que pueda detectar patrones en textos continuos desconocidos para extraer instancias de las clases de conceptos entrenadas. La combinación del modelo de PLN con la lógica empresarial correspondiente puede utilizarse ahora para responder de forma automatizada a una parte de las consultas.
En este contexto, nos gustaría ilustrar las ventajas del aprendizaje automático (ML) tomando como ejemplo el concepto de fecha. Para extraer una fecha de las consultas, podríamos utilizar una expresión regular, por ejemplo:
^\d{1,2}[ \.]{1,2}\d{0,2}[ \.]{0,2}((19|20|21)?\d{0,2})?$en combinación con un diccionario (lunes, …, domingo, mañana, el próximo …). Esta forma clásica de procesamiento de datos ya funciona bien en muchos casos. Sin embargo, las más mínimas desviaciones del esquema aquí definido hacen que una fecha ya no se reconozca en el texto. Además, este enfoque conlleva el riesgo de que se produzcan diversos errores graves. En primer lugar, resulta que no se tienen en cuenta errores como, por ejemplo, errores tipográficos, ortográficos, etc. Además, hay casos en los que las palabras del diccionario no se utilizan en el contexto de una fecha.
«… He perdido el tren y estoy esperando al siguiente; el lunes ya no podré usar mi billete de fin de semana».
El ejemplo muestra que «el próximo» también puede referirse a un tren. En este caso, la falta de signos de puntuación, sumada a la ausencia de distinción entre mayúsculas y minúsculas, complica aún más la definición de reglas universales. Un modelo de PLN basado en aprendizaje automático y entrenado con este tipo de datos reconoce la referencia y, por lo tanto, puede identificar únicamente «lunes» como indicación de fecha.
El proceso de desarrollo y DevOps de este modelo de PLN se apoya, al igual que en el desarrollo de software convencional, en un conjunto de herramientas específicas para cada problema. Así, los marcos de PLN, como por ejemplo spaCy, ofrecen todos los métodos necesarios para crear modelos de PLN a partir de datos existentes. La creación de los datos de entrenamiento se ve respaldada por herramientas de anotación específicas para cada tarea y herramientas de control de versiones específicas para el aprendizaje automático, como DVC. Los modelos creados pueden implementarse, gestionarse y supervisarse de forma eficiente en la nube mediante tecnologías de contenedores como Docker, en combinación con sistemas de implementación de contenedores de software como Amazon EC² o Kubernetes.
Resumen
La investigación en el campo del PLN ha logrado avances fundamentales en los últimos años. El enorme aumento de la potencia de cálculo disponible da lugar a modelos cada vez más potentes y a sistemas de PLN cada vez mejores (el Traductor de Google es solo un ejemplo positivo).
Según un estudio de Gartner[1],el PLN está pasando actualmente de la investigación al ámbito industrial. Las posibilidades que ofrece el PLN basado en el aprendizaje automático tienen el potencial de optimizar de forma radical y rentable los procesos de TI en muchas empresas y, al mismo tiempo, satisfacer las exigencias cada vez mayores de los clientes en materia de disponibilidad mediante una automatización total o parcial.
Autores
Prof. Dr. Bodo Kraft
El Prof. Dr. Bodo Kraft es fundador y director del laboratorio Business Programming. Allí lleva más de diez años realizando, junto con los cinco doctorandos que lo integran actualmente, investigación aplicada en el ámbito de la lingüística computacional. El denominador común de los distintos proyectos es el reto de procesar de forma eficiente y automatizada grandes volúmenes de documentos en lenguaje natural.
En este sentido, es fundamental adaptar con éxito las soluciones al ámbito concreto. Otro aspecto clave es adoptar un enfoque ágil y orientado a la calidad para crear sistemas de software que sean útiles para la empresa y fáciles de mantener.
Lars Klöser, máster en Ciencias
Lars Klöser, máster en Ciencias, estudió Informática en la RWTH de Aquisgrán y actualmente está realizando su doctorado bajo la dirección del Prof. Dr. Bodo Kraft, formando parte del Laboratorio de Programación Empresarial. Su trabajo se centra en el procesamiento del lenguaje natural (NLP) y, en particular, en la extracción de estructuras semánticas complejas a partir de textos jurídicos.
[1] https://www.gartner.com/smarterwithgartner/top-trends-on-the-gartner-hype-cycle-for-artificial-intelligence-2019/