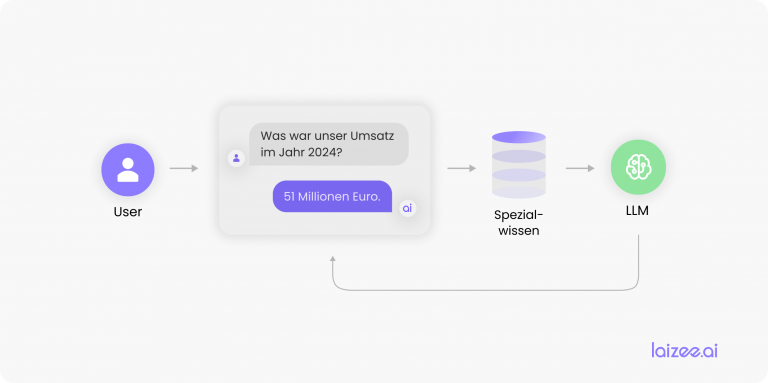
Pocas áreas de la informática gozan actualmente de tanta popularidad como el aprendizaje automático (ML) y, en particular, el procesamiento del lenguaje natural (NLP). ¿Quién no sabe cómo manejar el smartphone o la radio mediante un asistente de voz (Siri, Alexa, etc.)? ¿No es una maravilla poder decir simplemente la dirección a la que quieres que te lleve el navegador? Incluso es posible el reconocimiento automático de las consultas de los clientes en el procesamiento automático de cartas.
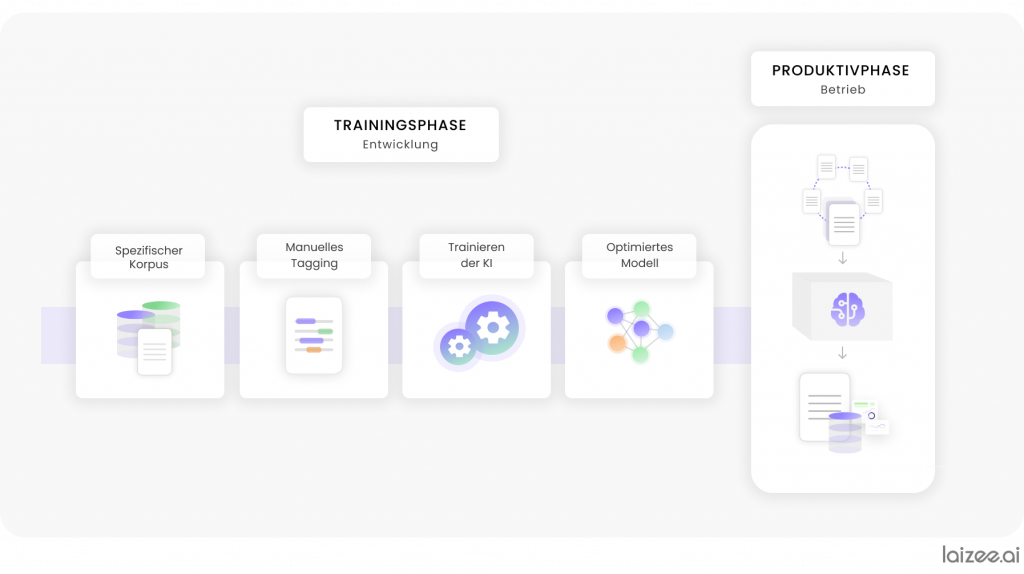
A pesar de la existencia de herramientas y de modelos de procesos y procedimientos ya consolidados, como por ejemplo STAMP4NLP [1], la creación de una aplicación de este tipo sigue suponiendo un gran esfuerzo. Para poder entrenar los modelos estadísticos necesarios, capaces de identificar patrones en los datos con el fin de extraer información, primero hay que identificar y preparar los datos adecuados. Esto incluye tanto la corrección de errores ortográficos como el etiquetado manual, que consiste en marcar elementos del texto. A partir del corpus anotado, el modelo se entrena durante la fase de entrenamiento y, una vez completada la optimización, se integra en un sistema de IA que puede utilizarse de forma productiva (véase Figura 1).
Un aspecto que cada vez cobra mayor importancia en el desarrollo de sistemas de IA es la protección de datos [2]. Debido a la gran complejidad que entraña el desarrollo de aplicaciones de PLN, muchas empresas dependen de la ayuda de empresas y desarrolladores externos. Sin embargo, esto implica facilitar datos que contienen información sensible en materia de protección de datos, sobre cuya base se entrenan las nuevas aplicaciones. Este es el punto en el que, hasta ahora, la mayoría de estas empresas han desistido de introducir la PLN en sus propias operaciones, ya que la anonimización de los datos conlleva un gran esfuerzo.
En particular, gracias al Reglamento General de Protección de Datos (RGPD) de la UE, el tema de la anonimización de datos conforme a la normativa de protección de datos ha cobrado un nuevo impulso [3]. Debido a las elevadas sanciones que se imponen en caso de incumplimiento, la protección de datos supone actualmente un obstáculo especialmente importante para la implantación del PLN.
Los métodos existentes que sustituyen de forma relativamente sencilla la información sensible en materia de protección de datos por datos ficticios no pueden utilizarse sin más. Esto se debe, por un lado, al ámbito de aplicación concreto. En el contexto de los seguros, por ejemplo, sin duda deben considerarse sensibles los números de póliza, los nombres, los datos de los siniestros y las direcciones. Por el contrario, en el contexto de los datos médicos hay que prestar especial atención a atributos como, por ejemplo, la estatura, el peso, los síntomas y los diagnósticos. Por consiguiente, lo primero que hay que hacer es identificar los atributos críticos para cada ámbito.
Además, hay que tener en cuenta que se debe anonimizar una cantidad suficiente de información. Si, a partir de la información restante y añadiendo otra fuente de datos, es posible volver a deducir los datos originales, no se trata de una anonimización que impida la identificación. Un ejemplo de ello es la eliminación del nombre y la dirección, pero conservando al mismo tiempo la fecha de nacimiento y el sexo en un informe médico. Si ahora se añade el registro de empadronamiento y se limita a la zona de influencia del hospital, es posible identificar a la persona afectada con un esfuerzo mínimo [4].
Por otra parte, también hay que tener en cuenta la variedad de métodos disponibles. A modo de ejemplo, existen variantes que sustituyen los nombres de forma aleatoria por los 100 nombres más frecuentes en Alemania. Sin embargo, también es posible un intercambio esquemático 1:1 o aplicar métodos más complejos. En este contexto, no debe pasarse por alto la influencia que tiene la anonimización en el modelo que se va a entrenar. Si, durante el funcionamiento en producción de la aplicación de PLN, aparece un documento con un nombre que no se encuentra entre los 100 más frecuentes, es posible que este no se pueda reconocer. Por lo tanto, hay que tener en cuenta la conservación de la variabilidad de los datos dentro de los atributos anonimizados.
A esto se suma que, en el proceso de anonimización, también es importante mantener las relaciones entre los datos. De lo contrario, no se podrá reconocer, al analizar los registros, que se hace referencia a la misma persona o que los procesos descritos están relacionados entre sí. En general, los métodos utilizados hasta ahora limitan en exceso el entrenamiento de los modelos con datos anonimizados debido a la pérdida de información.
El objetivo es encontrar el equilibrio entre el cumplimiento de la normativa de protección de datos y el desarrollo de una aplicación de alta calidad. En el siguiente esquema se describe un posible procedimiento para hacer viable la implementación del PLN mediante la anonimización.
Esquema del procedimiento
Tomemos como ejemplo una empresa que se comunica con sus clientes a través de un formulario de contacto. Para no tener que gestionar cada mensaje manualmente, es conveniente que estos se procesen de forma automática en la medida de lo posible.
El desarrollo de la aplicación de PLN correspondiente corre a cargo de un proveedor externo de servicios de PLN, que solicita para ello los mensajes de los clientes que la empresa tiene en su poder. Sin embargo, dado que estos mensajes contienen datos personales sujetos a la normativa de protección de datos, la empresa no puede facilitarlos.
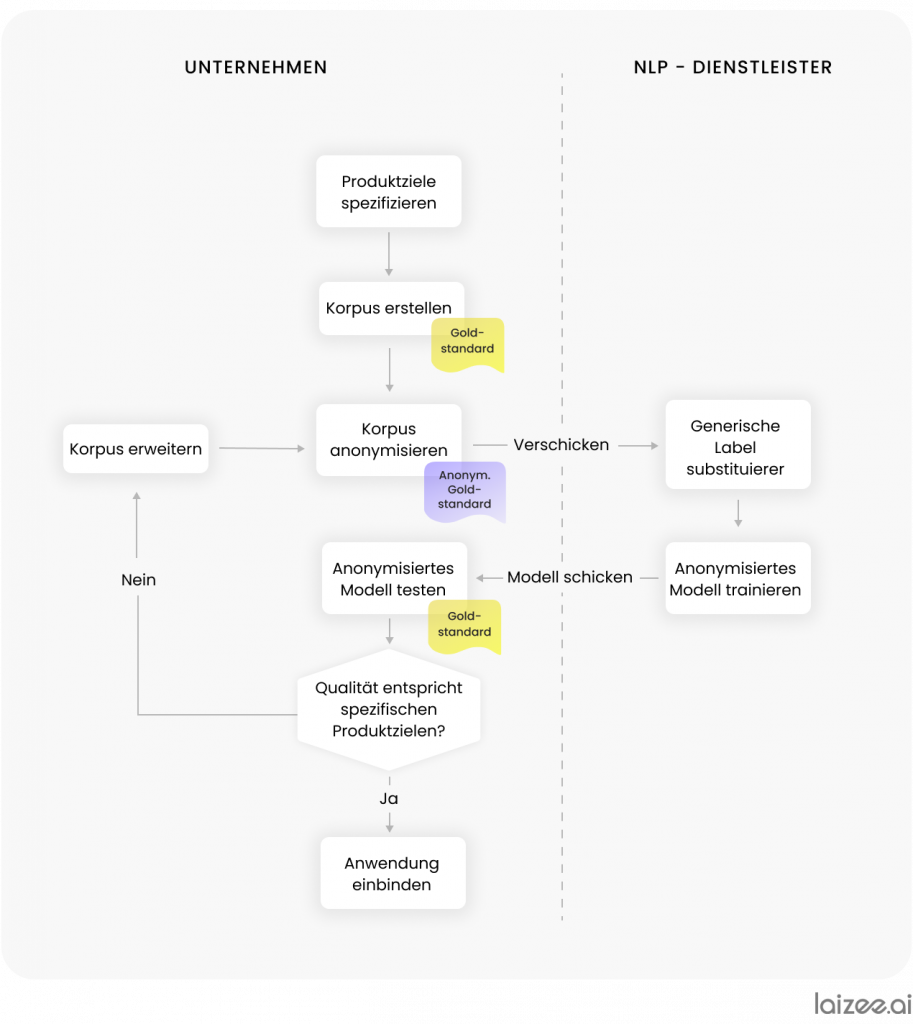
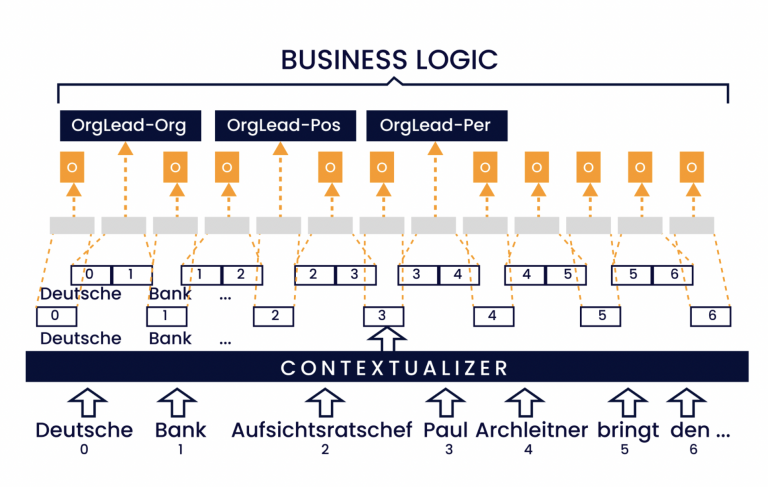
De acuerdo con Figura 2 Por lo tanto, se aplica el siguiente procedimiento: en primer lugar, la empresa crea un corpus y lo anota. Este se guarda como referencia de referencia. A continuación, hay que anonimizar el corpus. Una solución habitual consiste en que los empleados de la empresa marquen los puntos críticos de los mensajes y los sustituyan por las etiquetas correspondientes.

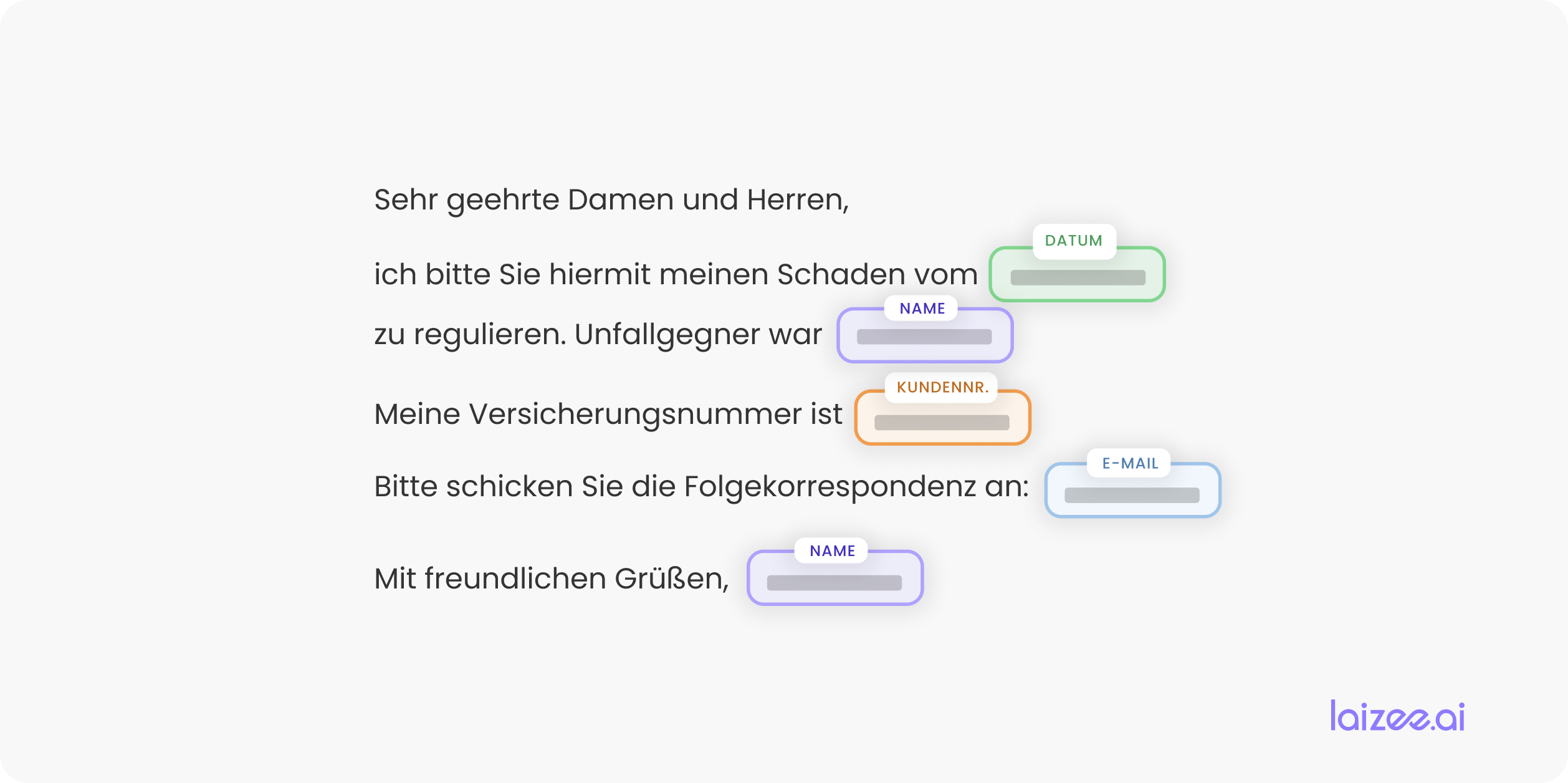
Para ello, en primer lugar hay que identificar todas las categorías de información crítica específicas del sector. A modo de ejemplo, nos encontramos en el sector de los seguros. Por lo tanto, deben sustituirse el nombre, la fecha, el número de cliente y la dirección de correo electrónico, así como otros posibles datos (véase Figura 3).
Una vez realizada la anonimización, el conjunto de datos con los correos electrónicos anonimizados se envía al proveedor de servicios de PLN. Este sustituye las etiquetas por datos ficticios y genera así un conjunto de datos que cumple con la normativa de protección de datos, que puede reutilizarse y que constituye un estándar de referencia anonimizado. A continuación, el proveedor de servicios entrena un modelo estadístico para la extracción de información y desarrolla un servicio de IA de PLN adecuado.
A continuación, el servicio y el modelo se entregan a la empresa contratante, donde se comprueba la calidad del procesamiento de los correos electrónicos. Para ello se utiliza el estándar de referencia establecido al inicio. Mediante diversas métricas, se mide la precisión de extracción de la aplicación en comparación con los objetivos del producto especificados previamente. Si la calidad no es suficiente, se evalúa si es necesario ajustar el procedimiento de anonimización o ampliar el corpus, y se vuelve a revisar la aplicación.
Si la calidad de procesamiento cumple todos los criterios para su uso productivo, la aplicación se integrará en los procesos existentes. Se debe comprobar periódicamente si el procesamiento sigue funcionando sin problemas o si es necesario realizar algún ajuste.
¿Existe alguna alternativa a la contratación de proveedores de servicios?
Como alternativa a la contratación de proveedores externos, existen modernas plataformas «low-code» alojadas «on premise». En este contexto, «low-code» significa que incluso personas sin conocimientos técnicos pueden desarrollar modelos de PLN de alto rendimiento. Las soluciones de plataforma abierta, como la de la startup TaggingMatters de la Universidad de Ciencias Aplicadas de Aquisgrán (https://taggingmatters.de/), tienen en cuenta la protección de datos y, al mismo tiempo, ocultan la complejidad de los marcos utilizados. De este modo, los empleados de las empresas no tienen que convertirse en expertos en las complejas herramientas de PLN o de aprendizaje automático, como spaCy o TensorFlow, ni en las matemáticas que subyacen a los métodos modernos, sino que pueden centrarse en las actividades que aportan valor añadido.
Estas plataformas permiten, además de la preparación de los datos («etiquetado»), la creación optimizada de la IA y la prestación de servicios de IA. De este modo, las iteraciones descritas anteriormente pueden llevarse a cabo mucho más rápidamente, incluso sin experiencia en PLN. En última instancia, la empresa se beneficia de unos costes de desarrollo más bajos y de un retorno de la inversión más rápido, ya que no hay que perder de vista el objetivo real: la mejora de los procesos empresariales.
Resumen
La existencia y el endurecimiento de la normativa sobre protección de datos dificultan la implantación del PLN en numerosas empresas de los más diversos sectores. La anonimización antes de ceder los datos a empresas de software externas o el uso de una plataforma de bajo código pueden ser soluciones útiles en este sentido. Un punto crítico es la calidad alcanzable de los modelos entrenados con datos anonimizados y su evaluación por parte de la empresa contratante. Para ello, es imprescindible un proceso de optimización iterativo para la creación y optimización de modelos con retroalimentación múltiple.
De cara al futuro, los procesos automatizados cobrarán cada vez más importancia en el contexto digital. Especialmente en lo que respecta a la Ley de Accesibilidad en Internet (OZG), cada vez más empresas estarán interesadas en optimizar sus procesos. Para ello, será cada vez más necesario contar con apoyo externo, lo cual puede llevarse a cabo mediante el esquema de procedimiento que aquí se muestra o mediante el uso de plataformas «low-code».
Autores
Prof. Dr. rer. nat. Bodo Kraft
El Prof. Dr. Bodo Kraft es fundador y director del laboratorio Business Programming. Allí lleva más de diez años realizando, junto con los cinco doctorandos que lo integran actualmente, investigación aplicada en el ámbito de la lingüística computacional. El objetivo común de los distintos proyectos es procesar de forma eficiente y automatizada grandes volúmenes de documentos en lenguaje natural.
En este sentido, es fundamental adaptar con éxito las soluciones al ámbito concreto. Otro aspecto clave es adoptar un enfoque ágil y orientado a la calidad para crear sistemas de software que sean útiles para la empresa y fáciles de mantener.
Prof. Dr. Matthias Meinecke
El Prof. Dr. Matthias Meinecke (catedrático de Gestión de Operaciones y miembro del consejo de administración del Instituto de Digitalización de Aquisgrán, Universidad de Ciencias Aplicadas de Aquisgrán) imparte clases, investiga y presta asesoramiento sobre temas relacionados con la optimización y la automatización de los procesos empresariales.
Junto con el Prof. Dr. Kraft, es asesor de la start-up laizee.ai, que desarrolla productos y servicios para el procesamiento eficiente y automatizado del lenguaje humano con el fin de optimizar los procesos empresariales.
M. Sc. Inés Larissa Siebigteroth
La máster Ines Larissa Siebigteroth estudió Matemáticas Aplicadas en la Universidad de Ciencias Aplicadas de Aquisgrán y en la Universidad de Wisconsin-Milwaukee, y actualmente está realizando su doctorado bajo la dirección del Prof. Dr. Bodo Kraft. La Sra. Siebigteroth forma parte del laboratorio de Programación Empresarial. Su trabajo se centra en el procesamiento del lenguaje natural (NLP) y, en particular, en la creación de corpus de alta calidad que cumplan con la normativa de protección de datos para el procesamiento automatizado del lenguaje natural.
Referencias
| [1] | P. Kohl, O. Schmidts, L. Klöser, H. Werth, B. Kraft y A. Zündorf, «STAMP 4 NLP: un marco ágil para el desarrollo rápido de aplicaciones de PLN orientadas a la calidad», [en línea]. Disponible en: https://link.springer.com/chapter/10.1007%2F978-3-030-85347-1_12. |
| [2] | Comisión de Ética de los Datos, «Recomendaciones de la Comisión de Ética de los Datos para la estrategia del Gobierno federal en materia de inteligencia artificial», [en línea]. Disponible en: https://www.bmjv.de/SharedDocs/Downloads/DE/Ministerium/ForschungUndWissenschaft/DEK_Empfehlungen.pdf?__blob=publicationFile&v=2. |
| [3] | S. C. A. Probst Eide, «El estado actual del desarrollo de herramientas para la anonimización de datos», [en línea]. Disponible en: https://www.it-finanzmagazin.de/entwicklungsstand-daten-anonymisierung-73373/. |
| [4] | D. Barth-Jones, «La “reidentificación” de la información médica del gobernador William Weld: un análisis crítico de los riesgos de identificación de los datos sanitarios y las medidas de protección de la privacidad, entonces y ahora», [en línea]. Disponible en: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=2076397. [Consultado el 15 de diciembre de 2021]. |