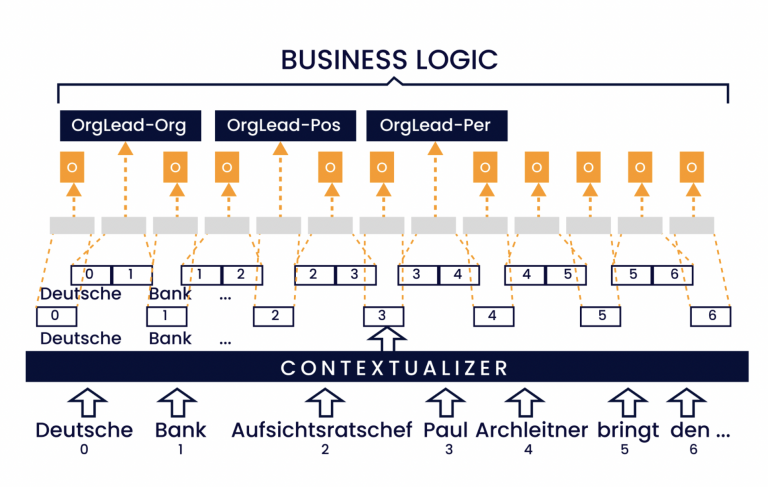
Desde noviembre de 2021, el tema de ChatGPT y la tecnología subyacente de los modelos de lenguaje a gran escala (LLM) está en boca de todos. Desde un punto de vista puramente técnico, el funcionamiento de los LLM se basa en la predicción de la siguiente palabra. Esto significa que la predicción de una palabra se realiza a partir de las palabras anteriores. Debido al enorme volumen de datos de entrenamiento y parámetros del modelo —GPT 3.5, por ejemplo, consta de 175 000 millones de parámetros—, los LLM pueden «comprender» diversos contextos y reconocer o reproducir patrones lingüísticos y semánticos más complejos.
Limitaciones
Pero, más allá de todo el revuelo que rodea a los LLM, también hay críticas justificadas y problemas de rendimiento:
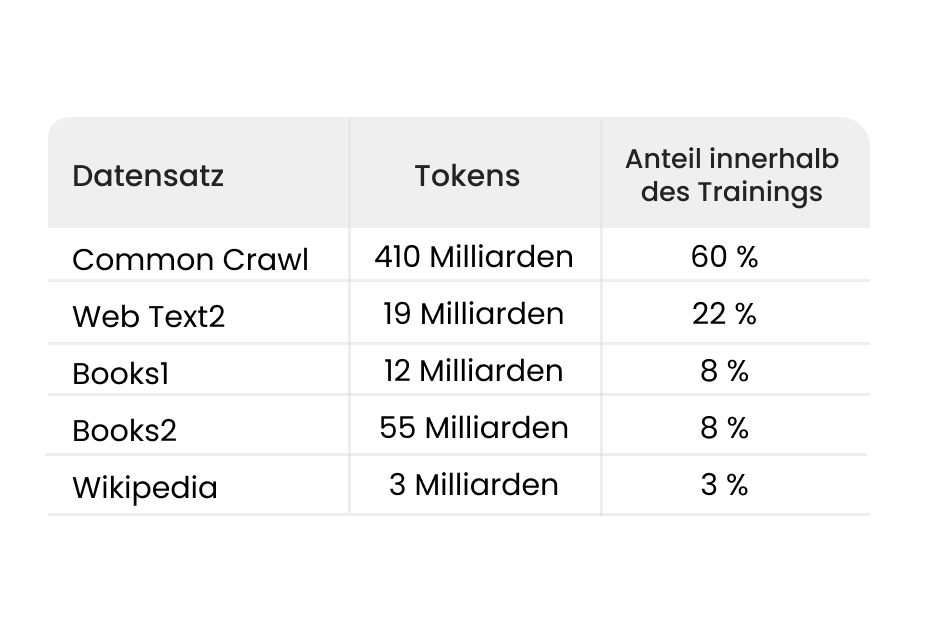
Los modelos de lenguaje grande (LLM) se entrenan con una cantidad enorme de datos. Para ello se utilizan, por ejemplo, textos de Wikipedia, noticias o el denominado CommonCrawl. En la mayoría de los casos, los contenidos de estos conjuntos de datos son muy generales y poco específicos. No se incluyen temas especializados ni información procedente, por ejemplo, de libros menos conocidos o protegidos por derechos de autor.
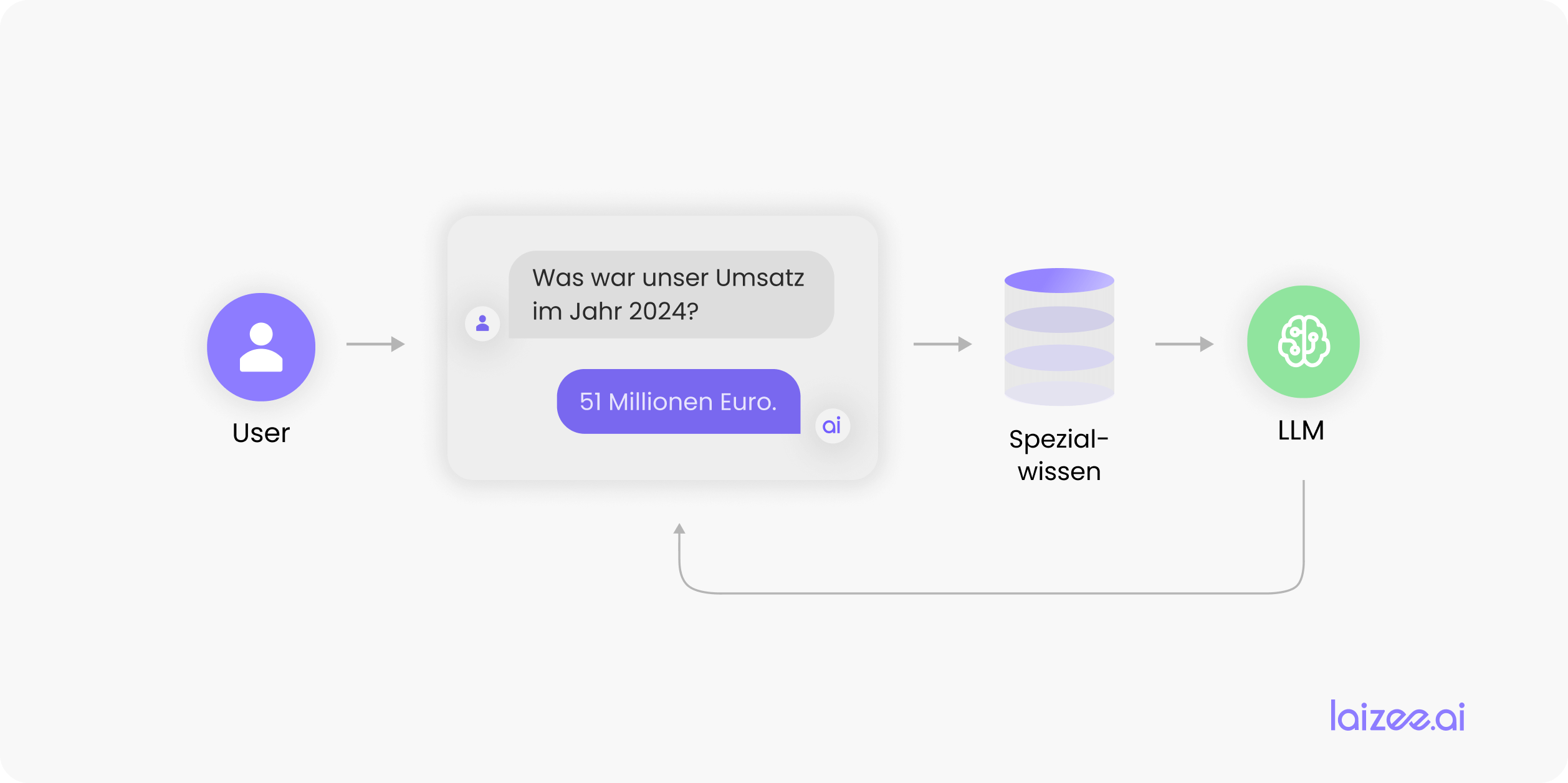
A más tardar cuando se le plantean a un chatbot como ChatGPT preguntas sobre temas de su propia especialidad —lo que también se conoce como «prompts»—, se observa que estos sistemas alcanzan rápidamente sus límites. Dado que los modelos de IA subyacentes no han sido entrenados suficientemente con información sobre posibles temas, estos modelos inventan respuestas que, a primera vista, parecen muy plausibles. En el ámbito de la IA, este fenómeno se denomina «alucinación». Dicho de otro modo, también se podría decir que el modelo convincente Se inventa datos y, con ello, genera desinformación.
Otro problema es que los LLM solo se entrenan con datos que abarcan hasta una fecha determinada. En el caso de GPT-3.5, por ejemplo, esa fecha es junio de 2021. Por lo tanto, toda la información y los textos publicados después de esa fecha no están disponibles para el modelo de IA. El reentrenamiento periódico de los modelos con datos adicionales puede ayudar a cerrar esta brecha de datos, pero resulta muy costoso y requiere mucho tiempo.
Las limitaciones y los problemas de los modelos de lenguaje grande (LLM) restringen considerablemente su utilidad para muchos usuarios, especialmente en ámbitos altamente especializados.
¿Cómo puede una empresa aprovechar, a pesar de las posibles limitaciones, las ventajas de los modelos de lenguaje grande (LLM) y ampliar sus conocimientos con información interna de la empresa? Una forma de integrar de manera rápida y económica los conocimientos que faltan en el propio sistema o modelo es el RAG.
¿Qué es RAG y cómo funciona?
RAG significa Generación aumentada por recuperación. En español se podría traducir como «generación ampliada mediante consultas». RAG es un proceso destinado a optimizar y especializar los resultados de los modelos de lenguaje grande (LLM). Básicamente, se trata de ampliar el conocimiento implícito aprendido por un LLM con información específica de la aplicación. A continuación, el LLM es capaz de responder correctamente a las consultas específicas de un usuario basándose en su ampliación de conocimientos.
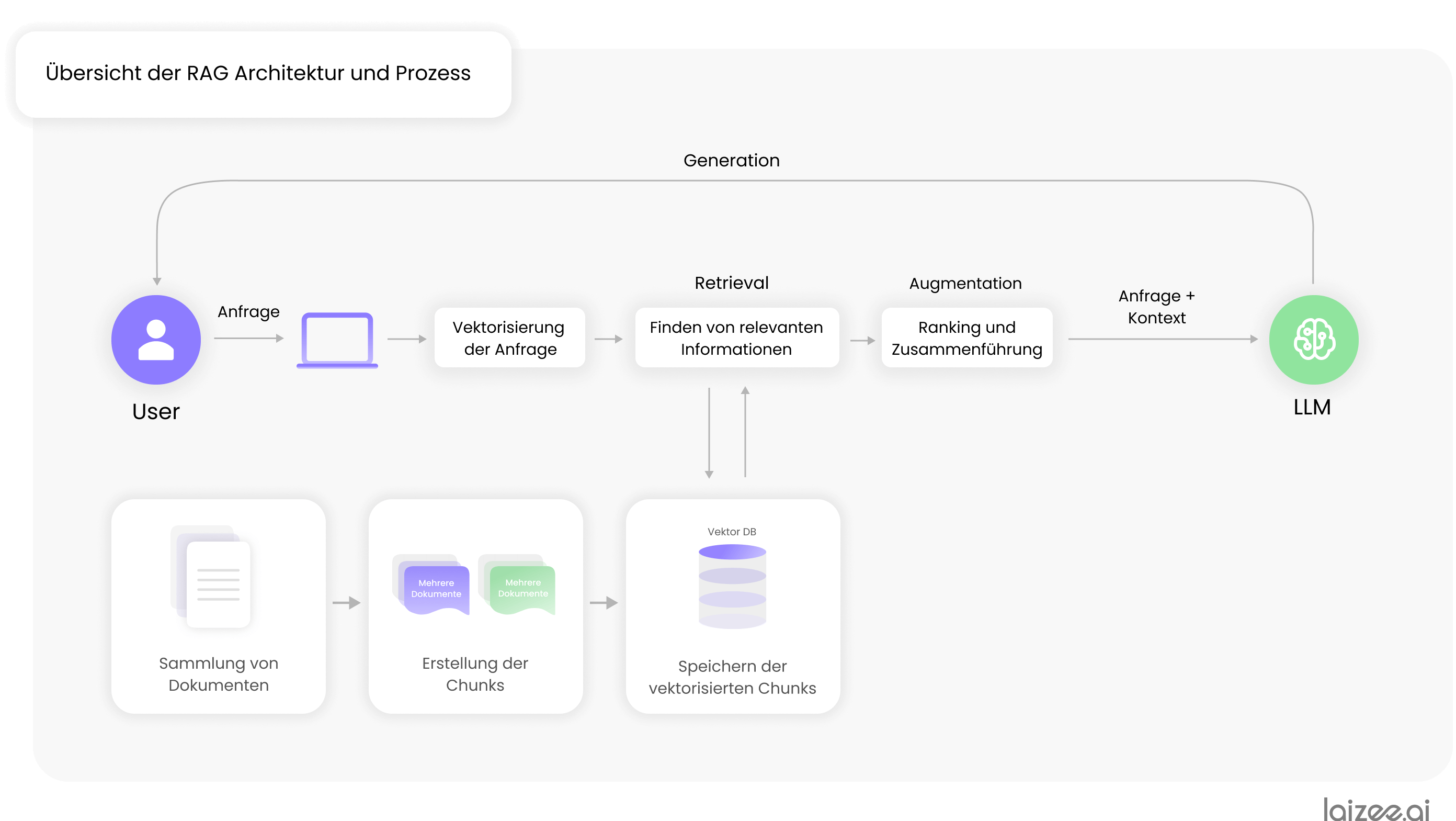
En su forma más básica, el proceso RAG se basa en tres componentes:
- Una base de datos vectorial en la que se almacenan bloques de información específicos para cada aplicación.
- Un sistema de recuperación que busca en la base de datos vectorial información relevante para la consulta.
- El LLM, que genera respuestas fáciles de entender a partir de la información encontrada.
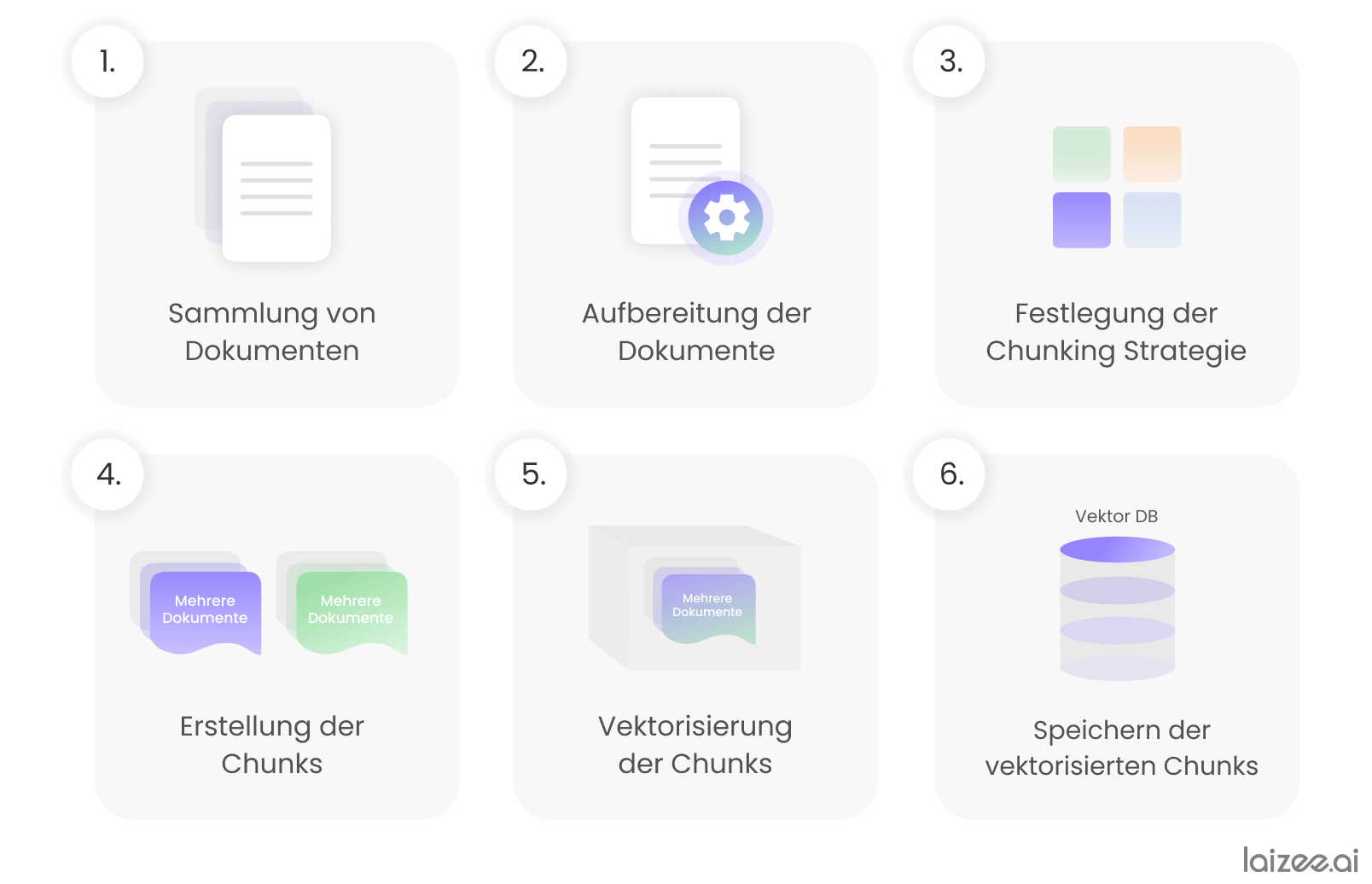
La columna vertebral de un sistema RAG es la base de datos vectorial, en la que se almacena la información necesaria para responder a las consultas específicas de la aplicación. Para crearla, se siguen básicamente estos seis pasos:
- Recopilación de documentos (por ejemplo, documentos PDF) con información y datos específicos de la aplicación.
- Preparación de documentos, por ejemplo, la conversión de documentos PDF a texto legible por máquina.
- Definición de la denominada estrategia de fragmentación, mediante la cual los documentos se dividen en bloques de información.
- Generación de bloques de información («chunks») según la estrategia previamente establecida.
- Conversión de los fragmentos en secuencias numéricas (vectores). Este paso también se conoce como «embedding».
- Almacenamiento de los fragmentos transferidos en la base de datos vectorial.
¿Cómo funciona el sistema de recuperación?
Las palabras se convierten en vectores numéricos. Cada palabra se representa, por tanto, como una secuencia de números. Lo interesante de los vectores es que permiten calcular similitudes semánticas y relaciones entre palabras. Dado que los vectores se pueden comparar muy rápidamente, un sistema de recuperación permite encontrar documentos con contenidos similares.
Proceso RAG
El usuario envía una solicitud al sistema. Esta solicitud se convierte en un vector utilizando el mismo procedimiento del paso 5.
A partir del vector de la consulta, se busca información relevante en la base de datos vectorial.
A continuación, estos datos se recuperan y se evalúan en función de diversos factores, se clasifican y, finalmente, se consolidan los resultados más destacados. Estos datos y documentos constituyen el Contexto con el que se amplía la solicitud del usuario.
A continuación, la consulta y el contexto previamente determinado se envían al LLM. Este genera una respuesta adecuada con ayuda de la información adicional y, finalmente, se la muestra al usuario.
Resumen de la arquitectura y los procesos de RAG
RAG frente a ajuste fino
Otra forma de ampliar un modelo de lenguaje grande (LLM) con información específica de una aplicación es la denominada Ajustes de precisiónPara ello, se toma un LLM ya preentrenado y se le somete a un entrenamiento adicional basado en información específica de la aplicación. En el marco de este entrenamiento adicional, se optimizan los parámetros existentes del modelo. Gracias al ajuste fino de los parámetros del modelo, el modelo entrenado adicionalmente es capaz, a diferencia del modelo original, de resolver también tareas específicas de la aplicación. El ajuste fino de los LLM existentes suele ser, por lo general, mucho más costoso y laborioso que el enfoque RAG.
Ventajas del enfoque de ajuste fino
- El modelo ajustado puede utilizarse para todas las tareas de los modelos de lenguaje grande (LLM) (por ejemplo, análisis de opiniones, reconocimiento de entidades) y no solo para sistemas de preguntas y respuestas, es decir, tareas de Q&A.
- Costes únicos (a menos que sea necesario formar al personal periódicamente en nuevos contenidos)
- Sin gastos adicionales de infraestructura a largo plazo
Retos del enfoque de ajuste fino
- En principio, esto no es posible con proveedores de modelos de terceros de código cerrado, como OpenAI
- El proceso de formación tiende a ser costoso y a requerir mucho tiempo
- no es funcional cuando hay que tener en cuenta datos en tiempo real o dinámicos
- Las alucinaciones siguen siendo un problema
- No es posible rastrear el origen de las respuestas/no se puede determinar
Ventajas del proceso RAG
- Una forma rápida de ampliar los modelos de lenguaje grande (LLM) con conocimientos internos y específicos del ámbito
- Una configuración sencilla y económica
- Admite la integración dinámica de datos en tiempo real
- Permite indicar y verificar las fuentes
- No requiere datos etiquetados
- Gestión del acceso a las fuentes
Retos del proceso RAG
- El proceso de «búsqueda y recuperación» tiene una gran influencia en la calidad del resultado
- RAG es especialmente relevante para los sistemas de preguntas y respuestas
- La creación y el funcionamiento continuo de la base de datos vectorial generan gastos corrientes
- El número de tokens de entrada que se pasan al LLM aumenta gracias al contexto
Casos de uso
RAG ofrece un rendimiento excepcional, sobre todo en tareas de preguntas y respuestas y en la extracción de información, es decir, en aquellas tareas en las que esperamos que el sistema de IA nos dé una respuesta clara a una pregunta. Además, la respuesta puede ir acompañada de las fuentes que el modelo de lenguaje grande (LLM) ha utilizado para responder a la consulta. Esto permite al usuario realizar un posible seguimiento u obtener más información.
Algunos ejemplos concretos en el ámbito empresarial son la incorporación de un chatbot a la intranet de la empresa o a una base de datos de conocimientos, con el que los empleados puedan interactuar fácilmente y formular preguntas. El chatbot de RAG permite a los empleados acceder rápidamente a los conocimientos internos de la empresa. Además, el chatbot procesa la información encontrada y la presenta de forma resumida. Esto permite un uso eficiente de los conocimientos de la empresa, mejora la calidad del trabajo de los empleados y puede contribuir a asegurar una ventaja competitiva a largo plazo.
Algunos ejemplos de casos de uso y aplicaciones de producto para un chatbot RAG son:
- Incorporación de nuevos empleados
- Uso diario y obtención de información empresarial
- El chatbot como vía adicional de acceso a los contenidos de aprendizaje digitales
… o creáis vuestro propio alter ego digital al estilo de Tom Riddle con las entradas de vuestro diario.